 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attention at Constant Cost per Token via Symmetry-Aware Taylor Approximation
Jan 30, 2026The most widely used artificial intelligence (AI) models today are Transformers employing self-attention. In its standard form, self-attention incurs costs that increase with context length, driving demand for storage, compute, and energy that is now outstripping society's ability to provide them. To help address this issue, we show that self-attention is efficiently computable to arbitrary precision with constant cost per token, achieving orders-of-magnitude reductions in memory use and computation. We derive our formulation by decomposing the conventional formulation's Taylor expansion into expressions over symmetric chains of tensor products. We exploit their symmetry to obtain feed-forward transformations that efficiently map queries and keys to coordinates in a minimal polynomial-kernel feature basis. Notably, cost is fixed inversely in proportion to head size, enabling application over a greater number of heads per token than otherwise feasible. We implement our formulation and empirically validate its correctness. Our work enables unbounded token generation at modest fixed cost, substantially reducing the infrastructure and energy demands of large-scale Transformer models. The mathematical techniques we introduce are of independent interest.
Softmax Attention with Constant Cost per Token
Apr 08, 2024We propose a simple modification to the conventional attention mechanism applied by Transformers: Instead of quantifying pairwise query-key similarity with scaled dot-products, we quantify it with the logarithms of scaled dot-products of exponentials. Attention becomes expressible as a composition of log-sums of exponentials that is linearizable, with a latent space of constant size, enabling sequential application with constant time and space complexity per token. We implement our modification, verify that it works in practice, and conclude that it is a promising alternative to conventional attention.
An Algorithm for Routing Vectors in Sequences
Nov 23, 2022We propose a routing algorithm that takes a sequence of vectors and computes a new sequence with specified length and vector size. Each output vector maximizes "bang per bit," the difference between a net benefit to use and net cost to ignore data, by better predicting the input vectors. We describe output vectors as geometric objects, as latent variables that assign credit, as query states in a model of associative memory, and as agents in a model of a Society of Mind. We implement the algorithm with optimizations that reduce parameter count, computation, and memory use by orders of magnitude, enabling us to route sequences of greater length than previously possible. We evaluate our implementation on natural language and visual classification tasks, obtaining competitive or state-of-the-art accuracy and end-to-end credit assignments that are interpretable.
Tree Methods for Hierarchical Classification in Parallel
Sep 21, 2022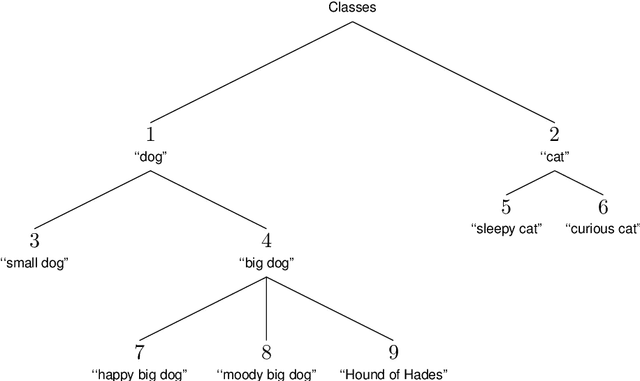


We propose methods that enable efficient hierarchical classification in parallel. Our methods transform a batch of classification scores and labels, corresponding to given nodes in a semantic tree, to scores and labels corresponding to all nodes in the ancestral paths going down the tree to every given node, relying only on tensor operations that execute efficiently on hardware accelerators. We implement our methods and test them on current hardware accelerators with a tree incorporating all English-language synsets in WordNet 3.0, spanning 117,659 classes in 20 levels of depth. We transform batches of scores and labels to their respective ancestral paths, incurring negligible computation and consuming only a fixed 0.04GB of memory over the footprint of data.
An Algorithm for Routing Capsules in All Domains
Dec 15, 2019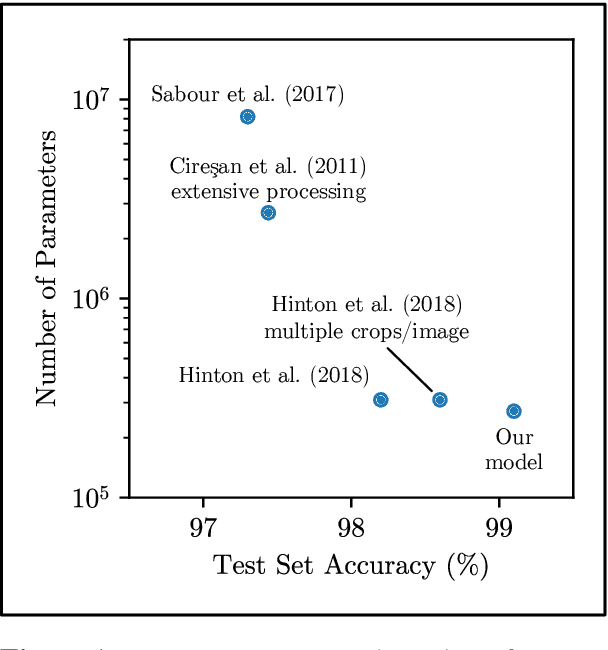

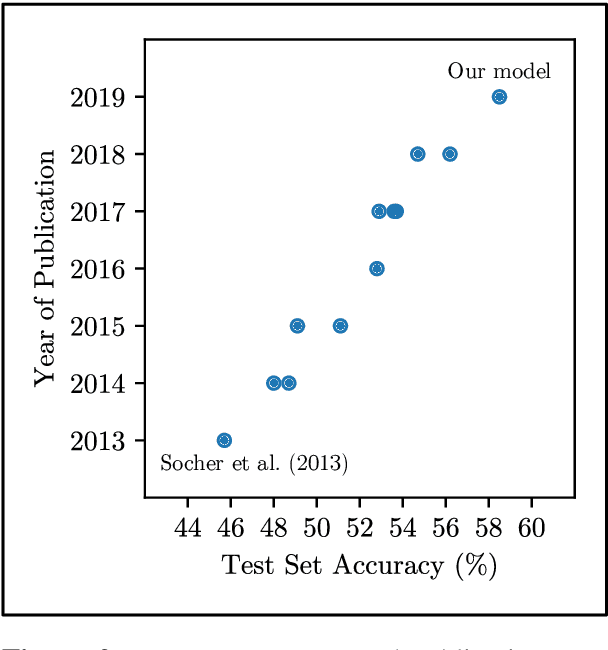
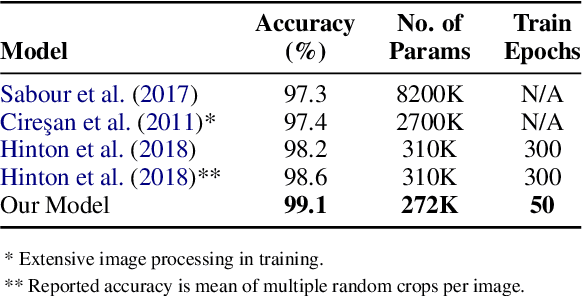
Building on recent work on capsule networks, we propose a new, general-purpose form of "routing by agreement" that activates output capsules in a layer as a function of their net benefit to use and net cost to ignore input capsules from earlier layers. To illustrate the usefulness of our routing algorithm, we present two capsule networks that apply it in different domains: vision and language. The first network achieves new state-of-the-art accuracy of 99.1% on the smallNORB visual recognition task with fewer parameters and an order of magnitude less training than previous capsule models, and we find evidence that it learns to perform a form of "reverse graphics." The second network achieves new state-of-the-art accuracies on the root sentences of the Stanford Sentiment Treebank: 58.5% on fine-grained and 95.6% on binary labels with a single-task model that routes frozen embeddings from a pretrained transformer as capsules. In both domains, we train with the same regime. Code is available at https://github.com/glassroom/heinsen_routing along with replication instructions.