 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-the-Wild Model Organisms: Mitigating Undesirable Emergent Behaviors in Production LLM Post-Training via Data Attribution
Feb 13, 2026We propose activation-based data attribution, a method that traces behavioral changes in post-trained language models to responsible training datapoints. By computing activation-difference vectors for both test prompts and preference pairs and ranking by cosine similarity, we identify datapoints that cause specific behaviors and validate these attributions causally by retraining with modified data. Clustering behavior-datapoint similarity matrices also enables unsupervised discovery of emergent behaviors. Applying this to OLMo 2's production DPO training, we surfaced distractor-triggered compliance: a harmful behavior where the model complies with dangerous requests when benign formatting instructions are appended. Filtering top-ranked datapoints reduces this behavior by 63% while switching their labels achieves 78%. Our method outperforms gradient-based attribution and LLM-judge baselines while being over 10 times cheaper than both. This in-the-wild model organism - emerging from contaminated preference data rather than deliberate injection - provides a realistic benchmark for safety techniques.
Diffusion-Based Action Recognition Generalizes to Untrained Domains
Sep 10, 2025



Humans can recognize the same actions despite large context and viewpoint variations, such as differences between species (walking in spiders vs. horses), viewpoints (egocentric vs. third-person), and contexts (real life vs movies). Current deep learning models struggle with such generalization. We propose using features generated by a Vision Diffusion Model (VDM), aggregated via a transformer, to achieve human-like action recognition across these challenging conditions. We find that generalization is enhanced by the use of a model conditioned on earlier timesteps of the diffusion process to highlight semantic information over pixel level details in the extracted features. We experimentally explore the generalization properties of our approach in classifying actions across animal species, across different viewing angles, and different recording contexts. Our model sets a new state-of-the-art across all three generalization benchmarks, bringing machine action recognition closer to human-like robustness. Project page: $\href{https://www.vision.caltech.edu/actiondiff/}{\texttt{vision.caltech.edu/actiondiff}}$ Code: $\href{https://github.com/frankyaoxiao/ActionDiff}{\texttt{github.com/frankyaoxiao/ActionDiff}}$
Image augmentation improves few-shot classification performance in plant disease recognition
Aug 25, 2022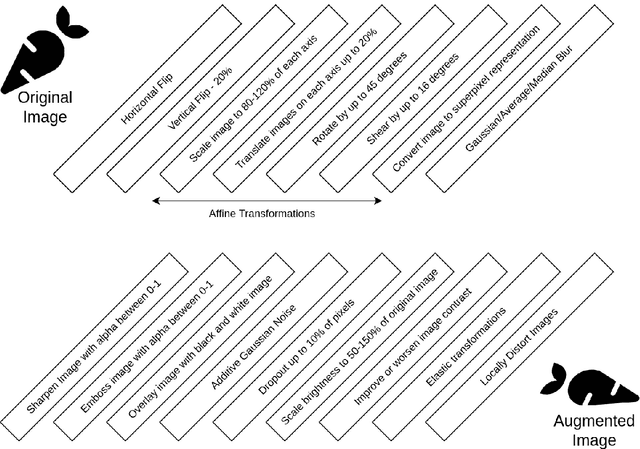

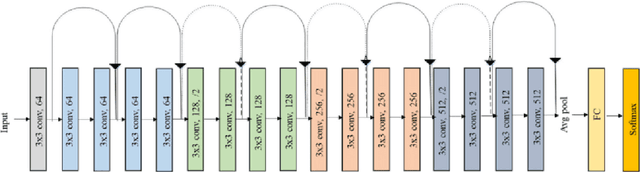
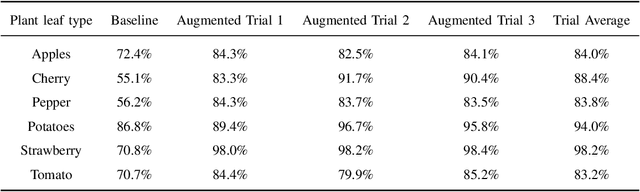
With the world population projected to near 10 billion by 2050, minimizing crop damage and guaranteeing food security has never been more important. Machine learning has been proposed as a solution to quickly and efficiently identify diseases in crops. Convolutional Neural Networks typically require large datasets of annotated data which are not available on demand. Collecting this data is a long and arduous process which involves manually picking, imaging, and annotating each individual leaf. I tackle the problem of plant image data scarcity by exploring the efficacy of various data augmentation techniques when used in conjunction with transfer learning. I evaluate the impact of various data augmentation techniques both individually and combined on the performance of a ResNet. I propose an augmentation scheme utilizing a sequence of different augmentations which consistently improves accuracy through many trials. Using only 10 total seed images, I demonstrate that my augmentation framework can increase model accuracy by upwards of 25\%.
Time Series Forecasting with Stacked Long Short-Term Memory Networks
Nov 02, 2020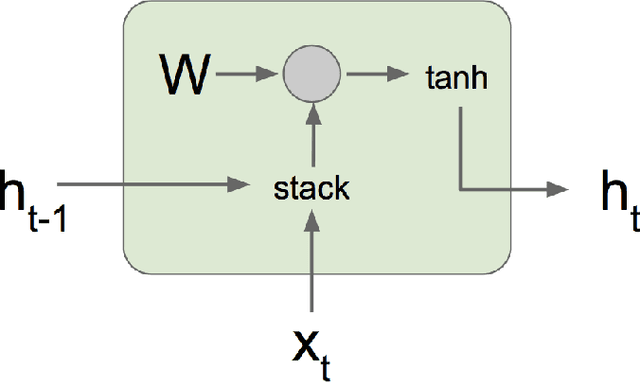
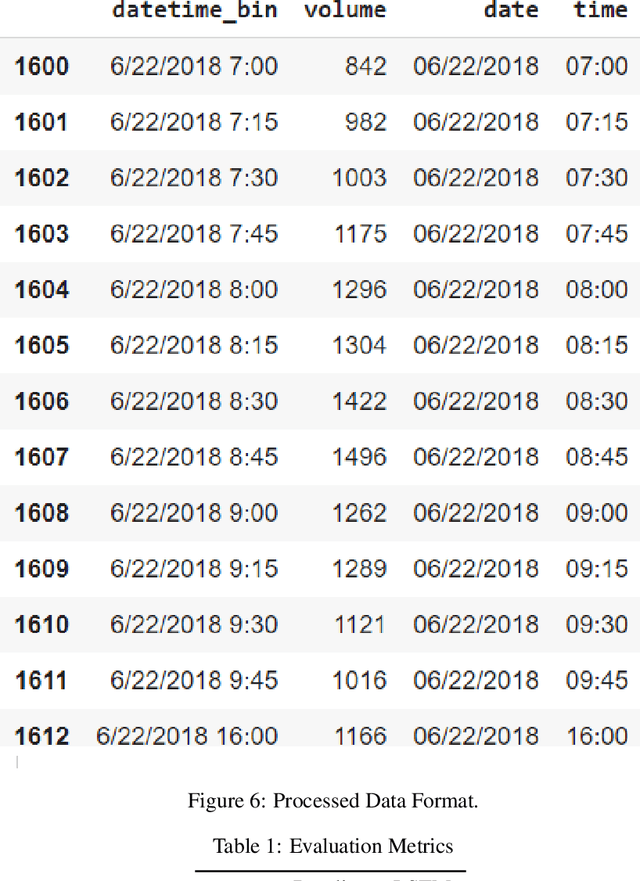
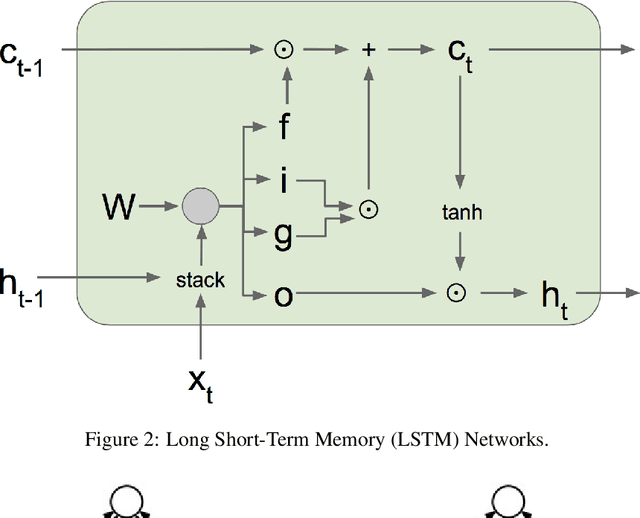
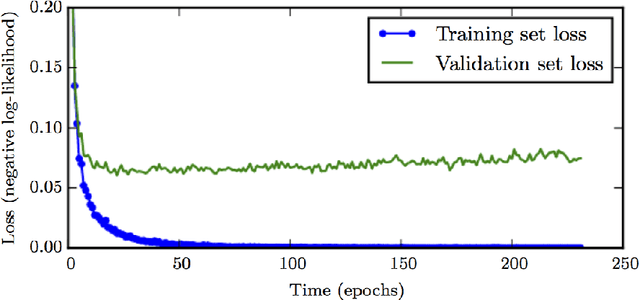
Long Short-Term Memory (LSTM) networks are often used to capture temporal dependency patterns. By stacking multi-layer LSTM networks, it can capture even more complex patterns. This paper explores the effectiveness of applying stacked LSTM networks in the time series prediction domain, specifically, the traffic volume forecasting. Being able to predict traffic volume more accurately can result in better planning, thus greatly reduce the operation cost and improve overall efficiency.