 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn analysis on the use of autoencoders for representation learning: fundamentals, learning task case studies, explainability and challenges
May 21, 2020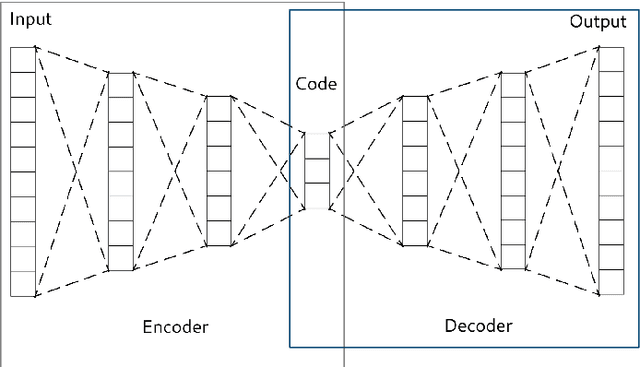
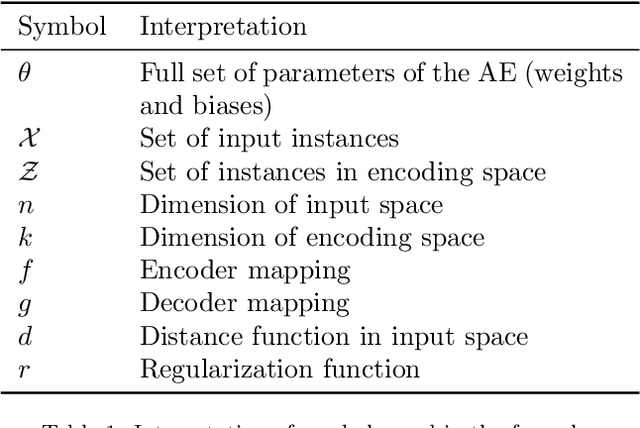
In many machine learning tasks, learning a good representation of the data can be the key to building a well-performant solution. This is because most learning algorithms operate with the features in order to find models for the data. For instance, classification performance can improve if the data is mapped to a space where classes are easily separated, and regression can be facilitated by finding a manifold of data in the feature space. As a general rule, features are transformed by means of statistical methods such as principal component analysis, or manifold learning techniques such as Isomap or locally linear embedding. From a plethora of representation learning methods, one of the most versatile tools is the autoencoder. In this paper we aim to demonstrate how to influence its learned representations to achieve the desired learning behavior. To this end, we present a series of learning tasks: data embedding for visualization, image denoising, semantic hashing, detection of abnormal behaviors and instance generation. We model them from the representation learning perspective, following the state of the art methodologies in each field. A solution is proposed for each task employing autoencoders as the only learning method. The theoretical developments are put into practice using a selection of datasets for the different problems and implementing each solution, followed by a discussion of the results in each case study and a brief explanation of other six learning applications. We also explore the current challenges and approaches to explainability in the context of autoencoders. All of this helps conclude that, thanks to alterations in their structure as well as their objective function, autoencoders may be the core of a possible solution to many problems which can be modeled as a transformation of the feature space.
A Showcase of the Use of Autoencoders in Feature Learning Applications
May 08, 2020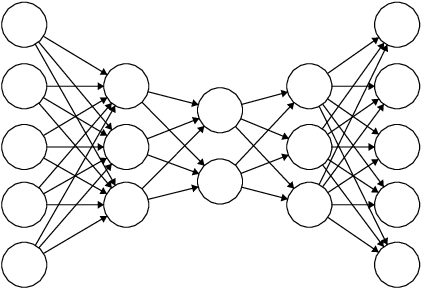
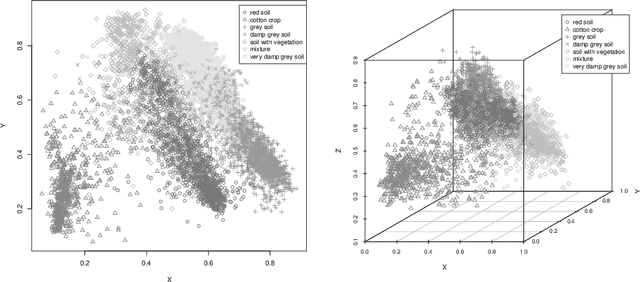

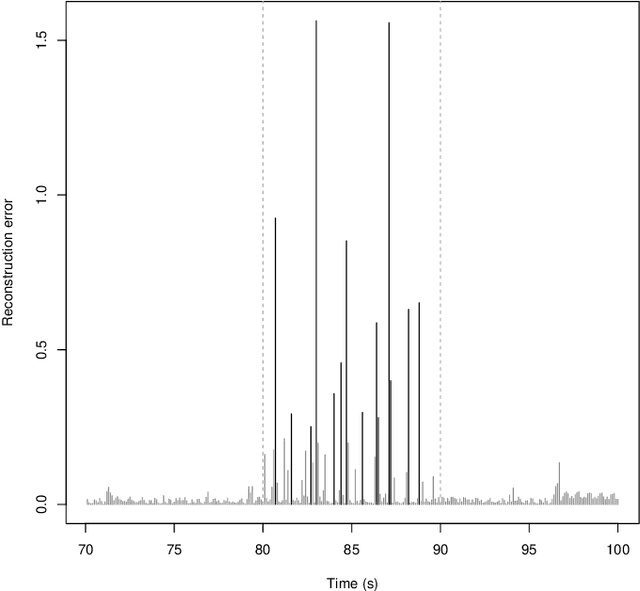
Autoencoders are techniques for data representation learning based on artificial neural networks. Differently to other feature learning methods which may be focused on finding specific transformations of the feature space, they can be adapted to fulfill many purposes, such as data visualization, denoising, anomaly detection and semantic hashing. This work presents these applications and provides details on how autoencoders can perform them, including code samples making use of an R package with an easy-to-use interface for autoencoder design and training, \texttt{ruta}. Along the way, the explanations on how each learning task has been achieved are provided with the aim to help the reader design their own autoencoders for these or other objectives.
* This manuscript was accepted as conference paper in IWINAC 2019. The final authenticated publication is available online at https://doi.org/10.1007/978-3-030-19651-6_40
Fairness in Bio-inspired Optimization Research: A Prescription of Methodological Guidelines for Comparing Meta-heuristics
Apr 19, 2020
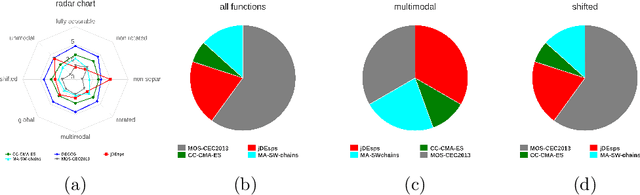
Bio-inspired optimization (including Evolutionary Computation and Swarm Intelligence) is a growing research topic with many competitive bio-inspired algorithms being proposed every year. In such an active area, preparing a successful proposal of a new bio-inspired algorithm is not an easy task. Given the maturity of this research field, proposing a new optimization technique with innovative elements is no longer enough. Apart from the novelty, results reported by the authors should be proven to achieve a significant advance over previous outcomes from the state of the art. Unfortunately, not all new proposals deal with this requirement properly. Some of them fail to select an appropriate benchmark or reference algorithms to compare with. In other cases, the validation process carried out is not defined in a principled way (or is even not done at all). Consequently, the significance of the results presented in such studies cannot be guaranteed. In this work we review several recommendations in the literature and propose methodological guidelines to prepare a successful proposal, taking all these issues into account. We expect these guidelines to be useful not only for authors, but also for reviewers and editors along their assessment of new contributions to the field.
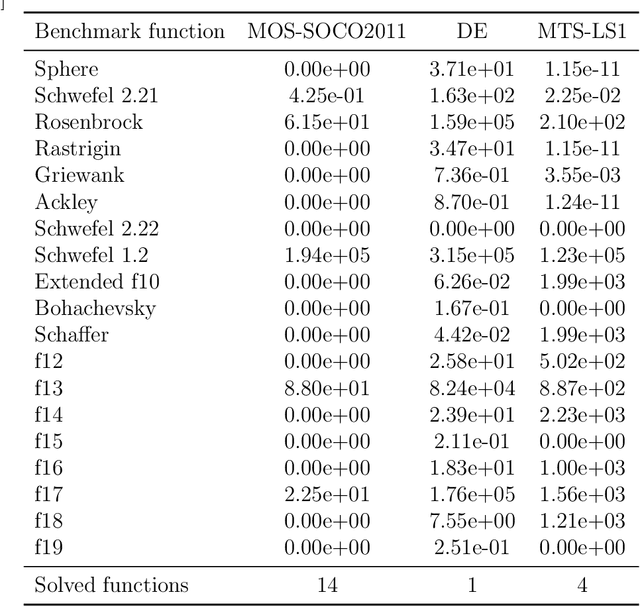
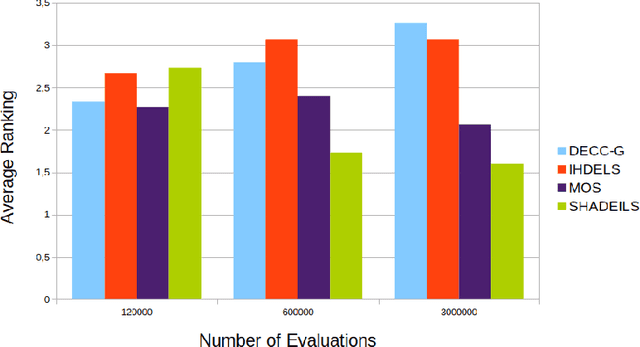
Multifactorial Cellular Genetic Algorithm (MFCGA): Algorithmic Design, Performance Comparison and Genetic Transferability Analysis
Mar 24, 2020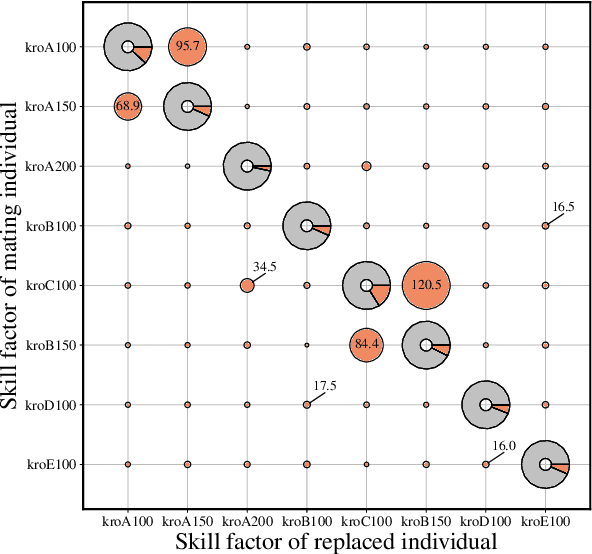

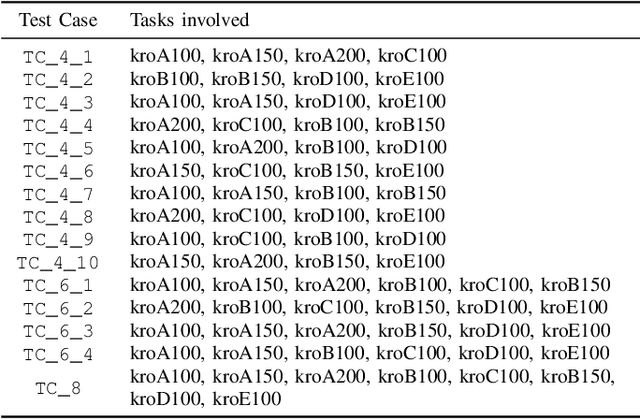

Multitasking optimization is an incipient research area which is lately gaining a notable research momentum. Unlike traditional optimization paradigm that focuses on solving a single task at a time, multitasking addresses how multiple optimization problems can be tackled simultaneously by performing a single search process. The main objective to achieve this goal efficiently is to exploit synergies between the problems (tasks) to be optimized, helping each other via knowledge transfer (thereby being referred to as Transfer Optimization). Furthermore, the equally recent concept of Evolutionary Multitasking (EM) refers to multitasking environments adopting concepts from Evolutionary Computation as their inspiration for the simultaneous solving of the problems under consideration. As such, EM approaches such as the Multifactorial Evolutionary Algorithm (MFEA) has shown a remarkable success when dealing with multiple discrete, continuous, single-, and/or multi-objective optimization problems. In this work we propose a novel algorithmic scheme for Multifactorial Optimization scenarios - the Multifactorial Cellular Genetic Algorithm (MFCGA) - that hinges on concepts from Cellular Automata to implement mechanisms for exchanging knowledge among problems. We conduct an extensive performance analysis of the proposed MFCGA and compare it to the canonical MFEA under the same algorithmic conditions and over 15 different multitasking setups (encompassing different reference instances of the discrete Traveling Salesman Problem). A further contribution of this analysis beyond performance benchmarking is a quantitative examination of the genetic transferability among the problem instances, eliciting an empirical demonstration of the synergies emerged between the different optimization tasks along the MFCGA search process.
Simultaneously Evolving Deep Reinforcement Learning Models using Multifactorial Optimization
Mar 23, 2020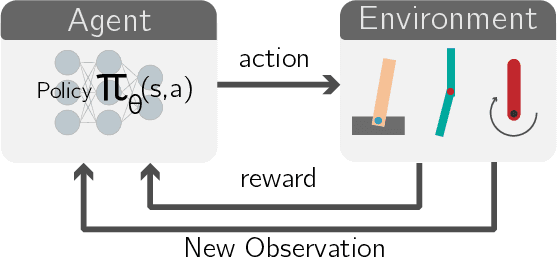
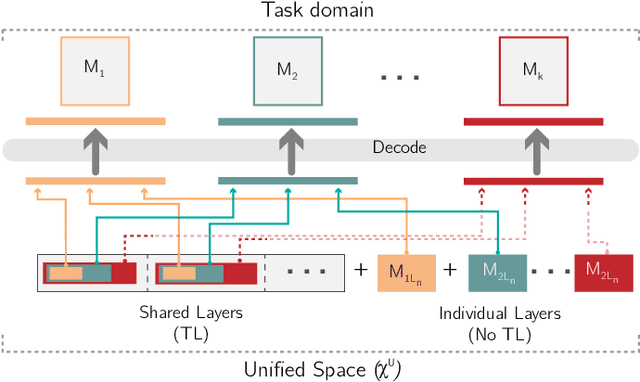
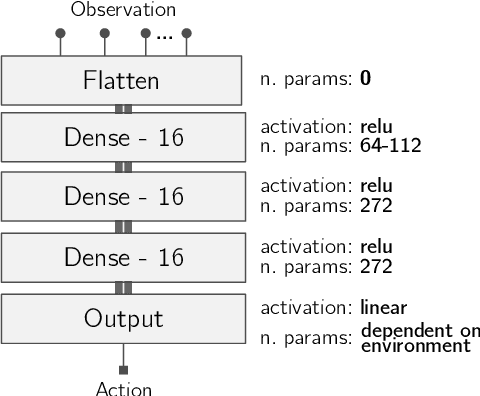
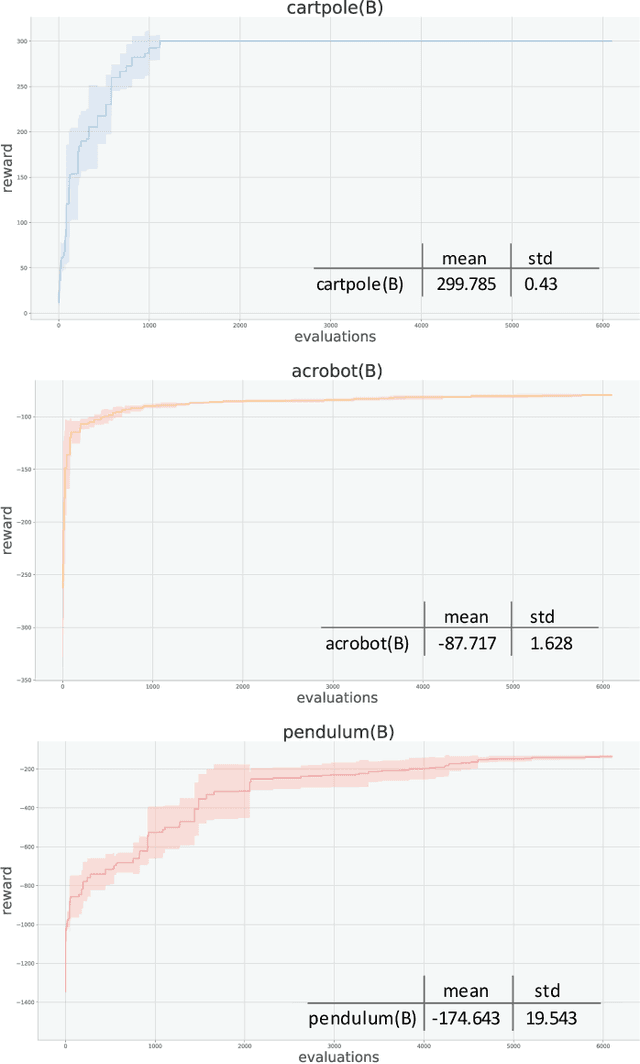
In recent years, Multifactorial Optimization (MFO) has gained a notable momentum in the research community. MFO is known for its inherent capability to efficiently address multiple optimization tasks at the same time, while transferring information among such tasks to improve their convergence speed. On the other hand, the quantum leap made by Deep Q Learning (DQL) in the Machine Learning field has allowed facing Reinforcement Learning (RL) problems of unprecedented complexity. Unfortunately, complex DQL models usually find it difficult to converge to optimal policies due to the lack of exploration or sparse rewards. In order to overcome these drawbacks, pre-trained models are widely harnessed via Transfer Learning, extrapolating knowledge acquired in a source task to the target task. Besides, meta-heuristic optimization has been shown to reduce the lack of exploration of DQL models. This work proposes a MFO framework capable of simultaneously evolving several DQL models towards solving interrelated RL tasks. Specifically, our proposed framework blends together the benefits of meta-heuristic optimization, Transfer Learning and DQL to automate the process of knowledge transfer and policy learning of distributed RL agents. A thorough experimentation is presented and discussed so as to assess the performance of the framework, its comparison to the traditional methodology for Transfer Learning in terms of convergence, speed and policy quality , and the intertask relationships found and exploited over the search process.
Fuzzy k-Nearest Neighbors with monotonicity constraints: Moving towards the robustness of monotonic noise
Mar 05, 2020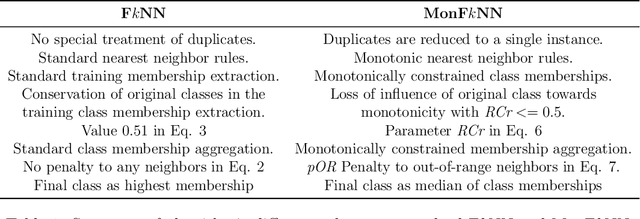
This paper proposes a new model based on Fuzzy k-Nearest Neighbors for classification with monotonic constraints, Monotonic Fuzzy k-NN (MonFkNN). Real-life data-sets often do not comply with monotonic constraints due to class noise. MonFkNN incorporates a new calculation of fuzzy memberships, which increases robustness against monotonic noise without the need for relabeling. Our proposal has been designed to be adaptable to the different needs of the problem being tackled. In several experimental studies, we show significant improvements in accuracy while matching the best degree of monotonicity obtained by comparable methods. We also show that MonFkNN empirically achieves improved performance compared with Monotonic k-NN in the presence of large amounts of class noise.
Comprehensive Taxonomies of Nature- and Bio-inspired Optimization: Inspiration versus Algorithmic Behavior, Critical Analysis and Recommendations
Feb 20, 2020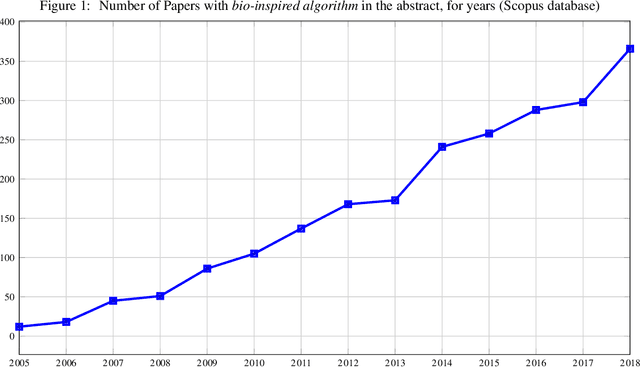
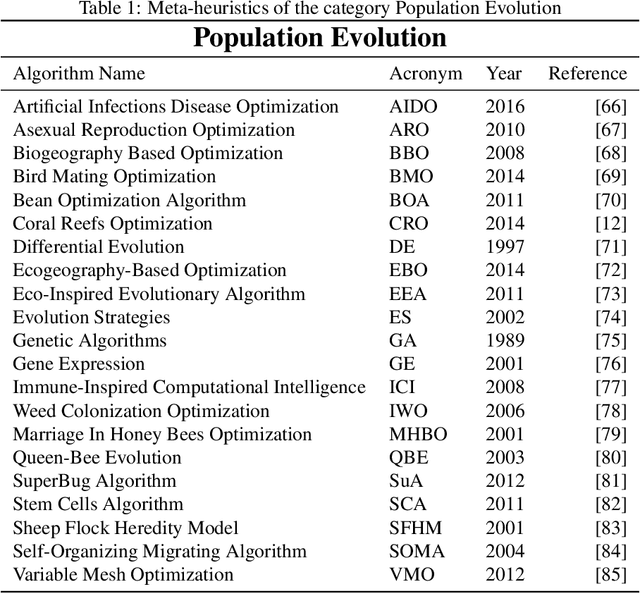
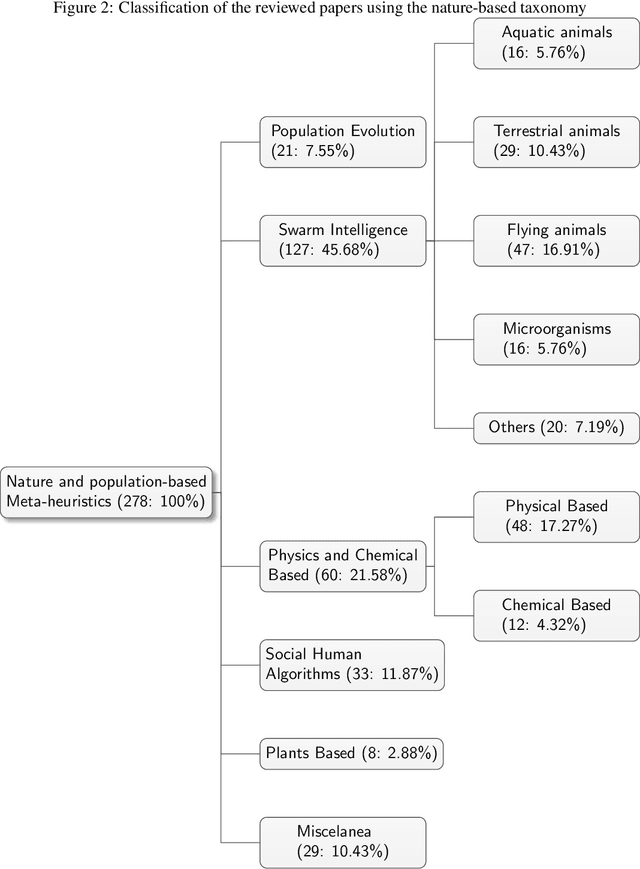
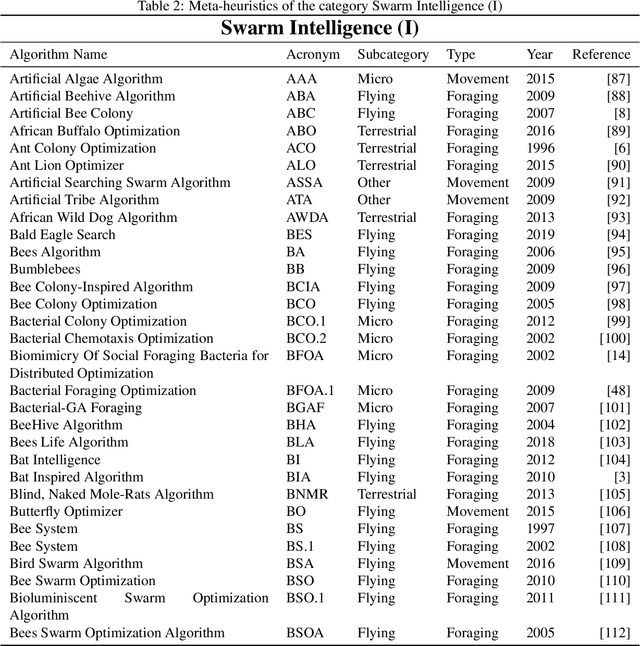
In recent years, a great variety of nature- and bio-inspired algorithms has been reported in the literature. This algorithmic family simulates different biological processes observed in Nature in order to efficiently address complex optimization problems. In the last years the number of bio-inspired optimization approaches in literature has grown considerably, reaching unprecedented levels that dark the future prospects of this field of research. This paper addresses this problem by proposing two comprehensive, principle-based taxonomies that allow researchers to organize existing and future algorithmic developments into well-defined categories, considering two different criteria: the source of inspiration and the behavior of each algorithm. Using these taxonomies we review more than three hundred publications dealing with nature-inspired and bio-inspired algorithms, and proposals falling within each of these categories are examined, leading to a critical summary of design trends and similarities between them, and the identification of the most similar classical algorithm for each reviewed paper. From our analysis we conclude that a poor relationship is often found between the natural inspiration of an algorithm and its behavior. Furthermore, similarities in terms of behavior between different algorithms are greater than what is claimed in their public disclosure: specifically, we show that more than one-third of the reviewed bio-inspired solvers are versions of classical algorithms. Grounded on the conclusions of our critical analysis, we give several recommendations and points of improvement for better methodological practices in this active and growing research field.
LUNAR: Cellular Automata for Drifting Data Streams
Feb 06, 2020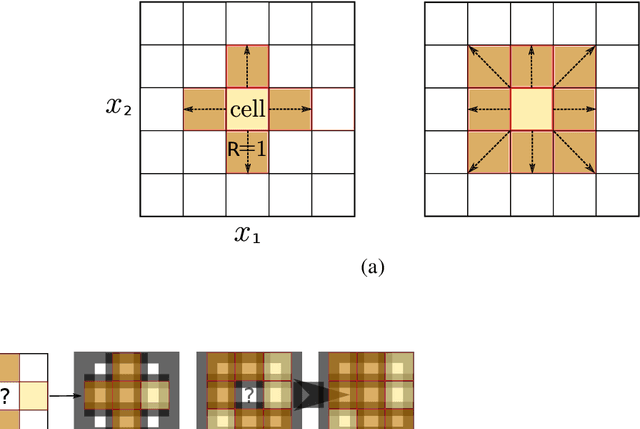
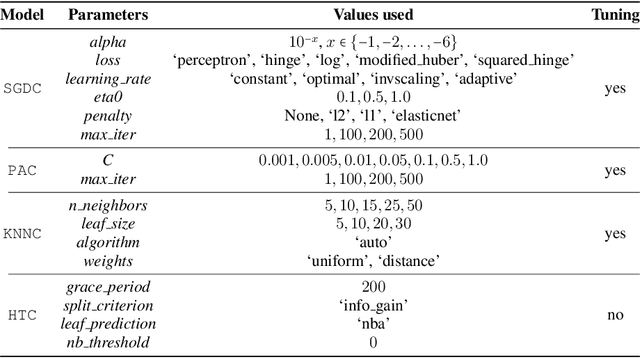
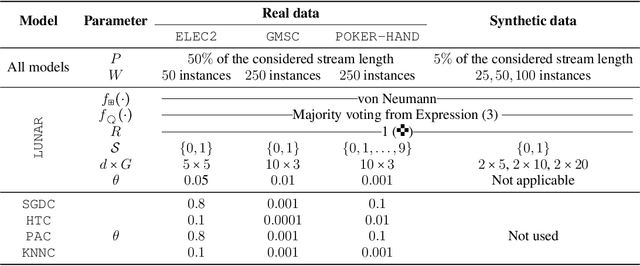
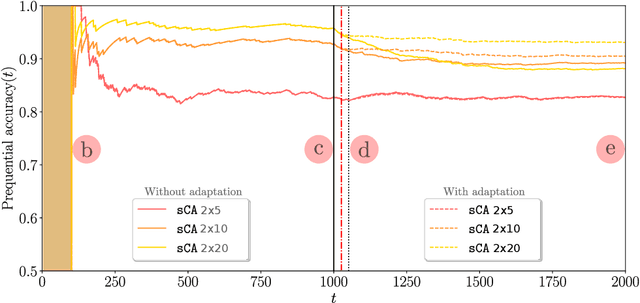
With the advent of huges volumes of data produced in the form of fast streams, real-time machine learning has become a challenge of relevance emerging in a plethora of real-world applications. Processing such fast streams often demands high memory and processing resources. In addition, they can be affected by non-stationary phenomena (concept drift), by which learning methods have to detect changes in the distribution of streaming data, and adapt to these evolving conditions. A lack of efficient and scalable solutions is particularly noted in real-time scenarios where computing resources are severely constrained, as it occurs in networks of small, numerous, interconnected processing units (such as the so-called Smart Dust, Utility Fog, or Swarm Robotics paradigms). In this work we propose LUNAR, a streamified version of cellular automata devised to successfully meet the aforementioned requirements. It is able to act as a real incremental learner while adapting to drifting conditions. Extensive simulations with synthetic and real data will provide evidence of its competitive behavior in terms of classification performance when compared to long-established and successful online learning methods.
Smart Data based Ensemble for Imbalanced Big Data Classification
Jan 16, 2020
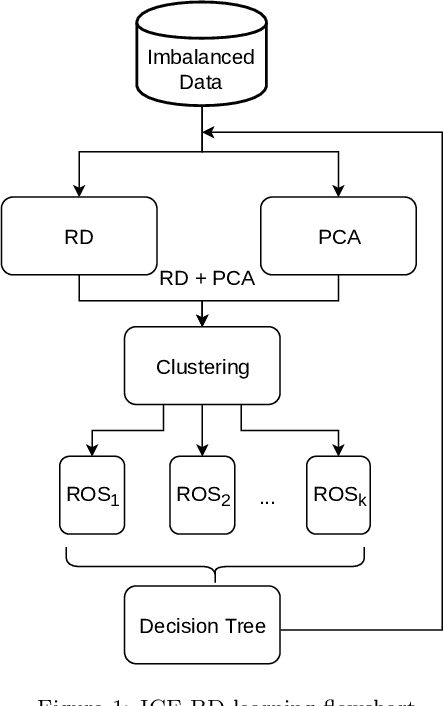
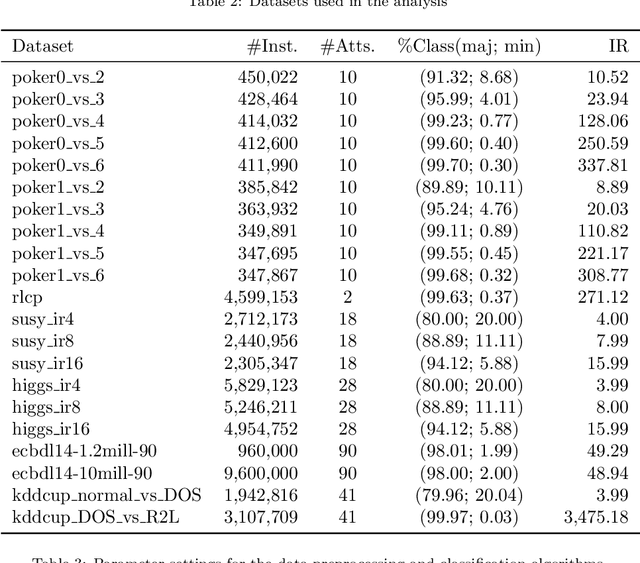
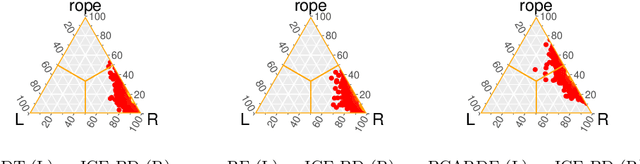
Big Data scenarios pose a new challenge to traditional data mining algorithms, since they are not prepared to work with such amount of data. Smart Data refers to data of enough quality to improve the outcome from a data mining algorithm. Existing data mining algorithms unability to handle Big Datasets prevents the transition from Big to Smart Data. Automation in data acquisition that characterizes Big Data also brings some problems, such as differences in data size per class. This will lead classifiers to lean towards the most represented classes. This problem is known as imbalanced data distribution, where one class is underrepresented in the dataset. Ensembles of classifiers are machine learning methods that improve the performance of a single base classifier by the combination of several of them. Ensembles are not exempt from the imbalanced classification problem. To deal with this issue, the ensemble method have to be designed specifically. In this paper, a data preprocessing ensemble for imbalanced Big Data classification is presented, with focus on two-class problems. Experiments carried out in 21 Big Datasets have proved that our ensemble classifier outperforms classic machine learning models with an added data balancing method, such as Random Forests.
Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI
Oct 22, 2019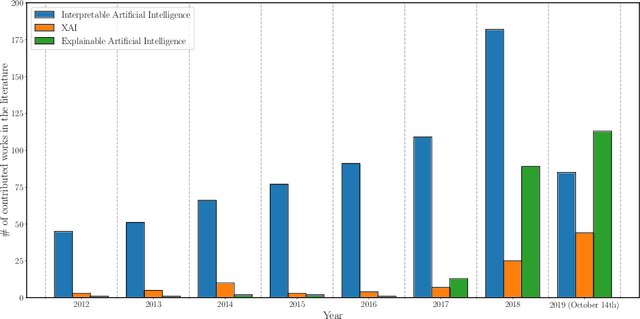
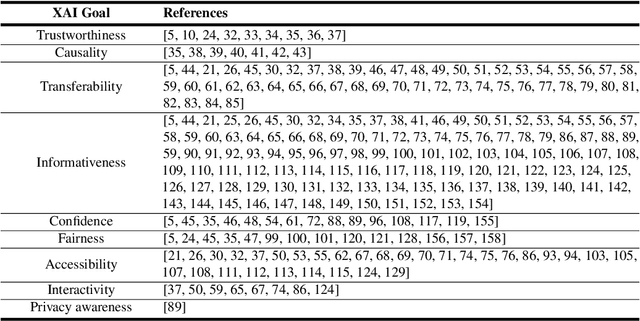
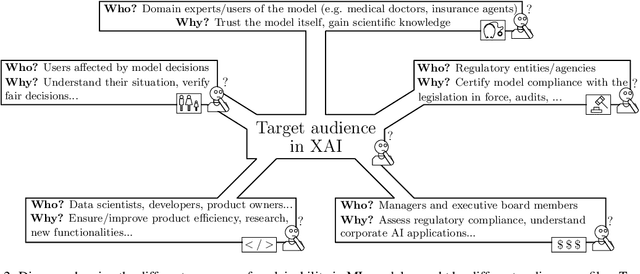
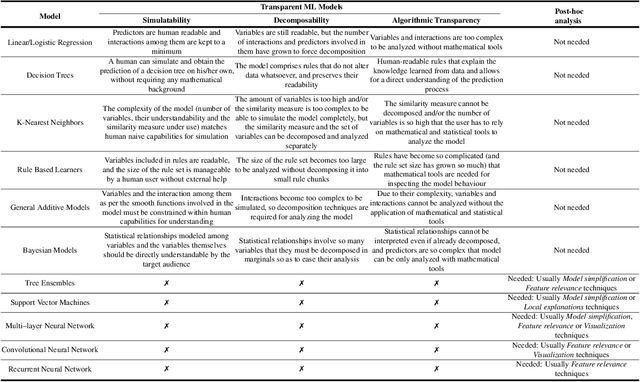
In the last years, Artificial Intelligence (AI) has achieved a notable momentum that may deliver the best of expectations over many application sectors across the field. For this to occur, the entire community stands in front of the barrier of explainability, an inherent problem of AI techniques brought by sub-symbolism (e.g. ensembles or Deep Neural Networks) that were not present in the last hype of AI. Paradigms underlying this problem fall within the so-called eXplainable AI (XAI) field, which is acknowledged as a crucial feature for the practical deployment of AI models. This overview examines the existing literature in the field of XAI, including a prospect toward what is yet to be reached. We summarize previous efforts to define explainability in Machine Learning, establishing a novel definition that covers prior conceptual propositions with a major focus on the audience for which explainability is sought. We then propose and discuss about a taxonomy of recent contributions related to the explainability of different Machine Learning models, including those aimed at Deep Learning methods for which a second taxonomy is built. This literature analysis serves as the background for a series of challenges faced by XAI, such as the crossroads between data fusion and explainability. Our prospects lead toward the concept of Responsible Artificial Intelligence, namely, a methodology for the large-scale implementation of AI methods in real organizations with fairness, model explainability and accountability at its core. Our ultimate goal is to provide newcomers to XAI with a reference material in order to stimulate future research advances, but also to encourage experts and professionals from other disciplines to embrace the benefits of AI in their activity sectors, without any prior bias for its lack of interpretability.