 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulatory modeling of the S-shaped F2 trajectories observed in Öhman's spectrographic analysis of VCV syllables
May 28, 2025The synthesis of Ohman's VCV sequences with intervocalic plosive consonants was first achieved 30 years ago using the DRM model. However, this approach remains primarily acoustic and lacks articulatory constraints. In this study, the same 75 VCVs are analyzed, but generated with the Maeda model, using trajectory planning that differentiates vowel-to-vowel transitions from consonantal influences. Synthetic data exhibit similar characteristics to Ohman's sequences, including the presence of S-shaped F2 trajectories. Furthermore, locus equations (LEs) for F2 and F3 are computed from synthetic CV data to investigate their underlying determinism, leading to a reassessment of conventional interpretations. The findings indicate that, although articulatory planning is structured separately for vowel and consonant groups, S-shaped F2 trajectories emerge from a composite mechanism governed by the coordinated synergy of all articulators.
Why can big.bi be changed to bi.gbi? A mathematical model of syllabification and articulatory synthesis
Jul 05, 2023A simplified model of articulatory synthesis involving four stages is presented. The planning of articulatory gestures is based on syllable graphs with arcs and nodes that are implemented in a complex representation. This was first motivated by a reduction in the many-to-one relationship between articulatory parameters and formant space. This allows for consistent trajectory planning and computation of articulation dynamics with coordination and selection operators. The flow of articulatory parameters is derived from these graphs with four equations. Many assertions of Articulatory Phonology have been abandoned. This framework is adapted to synthesis using VLAM (a Maeda's model) and simulations are performed with syllables including main vowels and the plosives /b,d,g/ only. The model is able to describe consonant-vowel coarticulation, articulation of consonant clusters, and verbal transformations are seen as transitions of the syllable graph structure.
A mathematical model of the vowel space
Nov 02, 2021
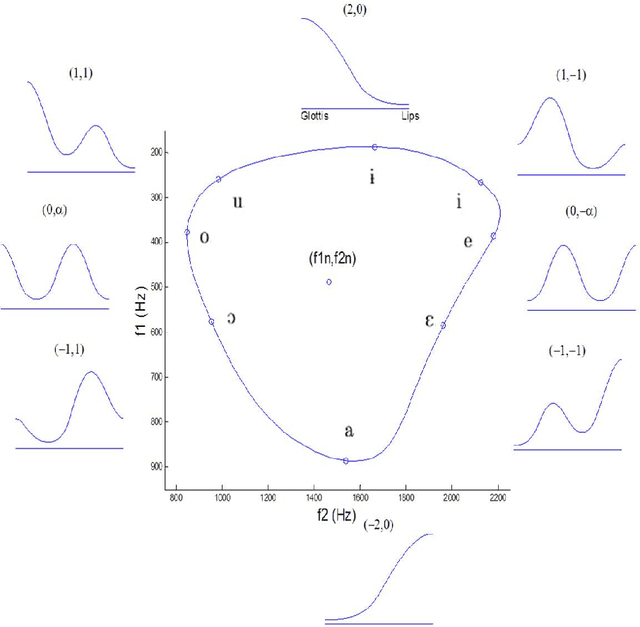

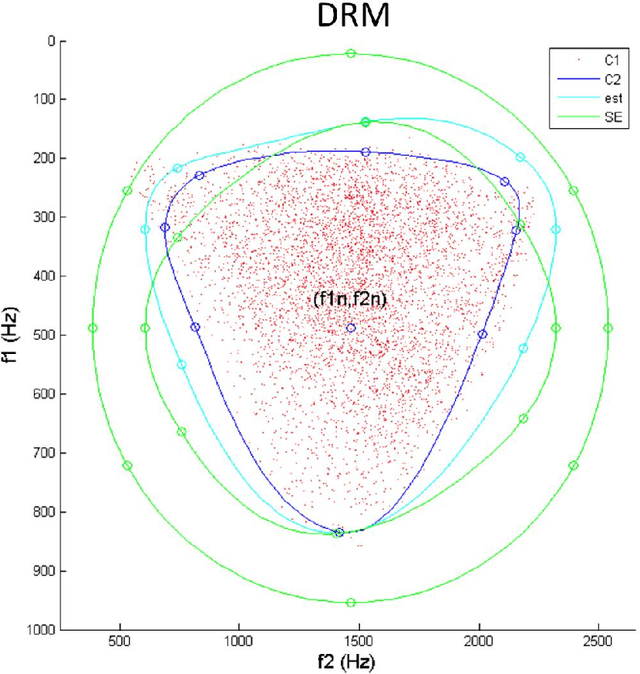
The articulatory-acoustic relationship is many-to-one and non linear and this is a great limitation for studying speech production. A simplification is proposed to set a bijection between the vowel space (f1, f2) and the parametric space of different vocal tract models. The generic area function model is based on mixtures of cosines allowing the generation of main vowels with two formulas. Then the mixture function is transformed into a coordination function able to deal with articulatory parameters. This is shown that the coordination function acts similarly with the Fant's model and with the 4-Tube DRM derived from the generic model.