 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrimming the Risk: Towards Reliable Continuous Training for Deep Learning Inspection Systems
Sep 13, 2024



The industry increasingly relies on deep learning (DL) technology for manufacturing inspections, which are challenging to automate with rule-based machine vision algorithms. DL-powered inspection systems derive defect patterns from labeled images, combining human-like agility with the consistency of a computerized system. However, finite labeled datasets often fail to encompass all natural variations necessitating Continuous Training (CT) to regularly adjust their models with recent data. Effective CT requires fresh labeled samples from the original distribution; otherwise, selfgenerated labels can lead to silent performance degradation. To mitigate this risk, we develop a robust CT-based maintenance approach that updates DL models using reliable data selections through a two-stage filtering process. The initial stage filters out low-confidence predictions, as the model inherently discredits them. The second stage uses variational auto-encoders and histograms to generate image embeddings that capture latent and pixel characteristics, then rejects the inputs of substantially shifted embeddings as drifted data with erroneous overconfidence. Then, a fine-tuning of the original DL model is executed on the filtered inputs while validating on a mixture of recent production and original datasets. This strategy mitigates catastrophic forgetting and ensures the model adapts effectively to new operational conditions. Evaluations on industrial inspection systems for popsicle stick prints and glass bottles using critical real-world datasets showed less than 9% of erroneous self-labeled data are retained after filtering and used for fine-tuning, improving model performance on production data by up to 14% without compromising its results on original validation data.
Assessing Programming Task Difficulty for Efficient Evaluation of Large Language Models
Jul 30, 2024
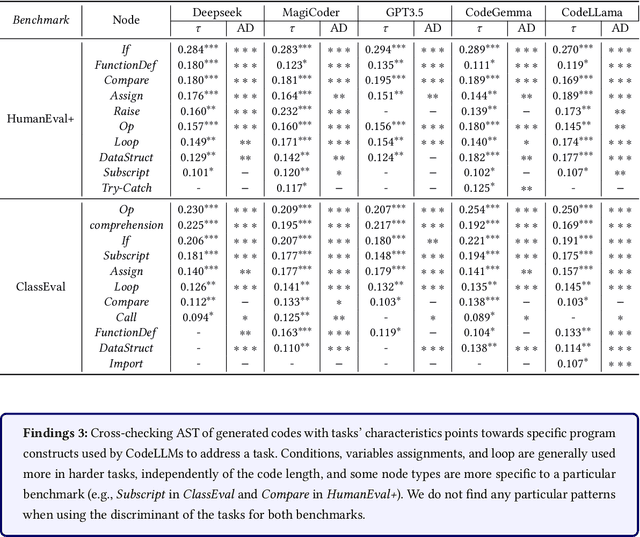
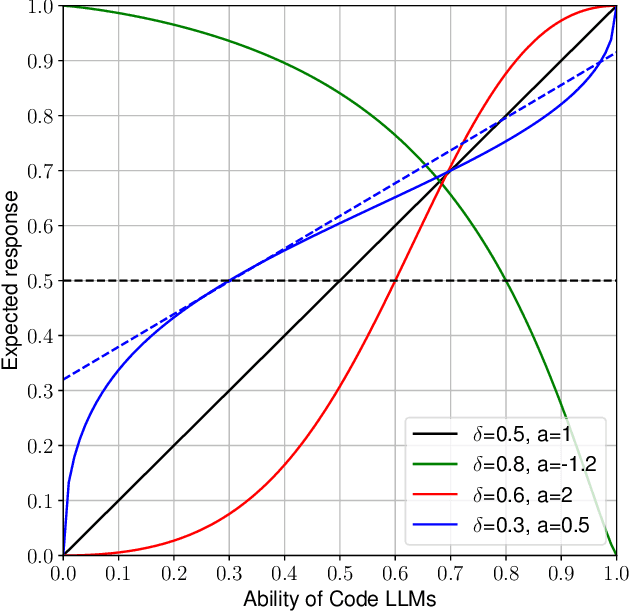
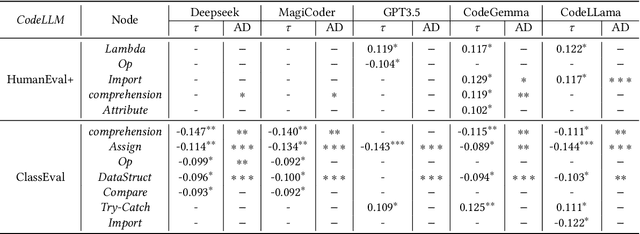
Large Language Models (LLMs) show promising potential in Software Engineering, especially for code-related tasks like code completion and code generation. LLMs' evaluation is generally centred around general metrics computed over benchmarks. While painting a macroscopic view of the benchmarks and of the LLMs' capacity, it is unclear how each programming task in these benchmarks assesses the capabilities of the LLMs. In particular, the difficulty level of the tasks in the benchmarks is not reflected in the score used to report the performance of the model. Yet, a model achieving a 90% score on a benchmark of predominantly easy tasks is likely less capable than a model achieving a 90% score on a benchmark containing predominantly difficult tasks. This paper devises a framework, HardEval, for assessing task difficulty for LLMs and crafting new tasks based on identified hard tasks. The framework uses a diverse array of prompts for a single task across multiple LLMs to obtain a difficulty score for each task of a benchmark. Using two code generation benchmarks, HumanEval+ and ClassEval, we show that HardEval can reliably identify the hard tasks within those benchmarks, highlighting that only 21% of HumanEval+ and 27% of ClassEval tasks are hard for LLMs. Through our analysis of task difficulty, we also characterize 6 practical hard task topics which we used to generate new hard tasks. Orthogonal to current benchmarking evaluation efforts, HardEval can assist researchers and practitioners in fostering better assessments of LLMs. The difficulty score can be used to identify hard tasks within existing benchmarks. This, in turn, can be leveraged to generate more hard tasks centred around specific topics either for evaluation or improvement of LLMs. HardEval generalistic approach can be applied to other domains such as code completion or Q/A.
DeepCodeProbe: Towards Understanding What Models Trained on Code Learn
Jul 11, 2024



Machine learning models trained on code and related artifacts offer valuable support for software maintenance but suffer from interpretability issues due to their complex internal variables. These concerns are particularly significant in safety-critical applications where the models' decision-making processes must be reliable. The specific features and representations learned by these models remain unclear, adding to the hesitancy in adopting them widely. To address these challenges, we introduce DeepCodeProbe, a probing approach that examines the syntax and representation learning abilities of ML models designed for software maintenance tasks. Our study applies DeepCodeProbe to state-of-the-art models for code clone detection, code summarization, and comment generation. Findings reveal that while small models capture abstract syntactic representations, their ability to fully grasp programming language syntax is limited. Increasing model capacity improves syntax learning but introduces trade-offs such as increased training time and overfitting. DeepCodeProbe also identifies specific code patterns the models learn from their training data. Additionally, we provide best practices for training models on code to enhance performance and interpretability, supported by an open-source replication package for broader application of DeepCodeProbe in interpreting other code-related models.
Mining Action Rules for Defect Reduction Planning
May 22, 2024



Defect reduction planning plays a vital role in enhancing software quality and minimizing software maintenance costs. By training a black box machine learning model and "explaining" its predictions, explainable AI for software engineering aims to identify the code characteristics that impact maintenance risks. However, post-hoc explanations do not always faithfully reflect what the original model computes. In this paper, we introduce CounterACT, a Counterfactual ACTion rule mining approach that can generate defect reduction plans without black-box models. By leveraging action rules, CounterACT provides a course of action that can be considered as a counterfactual explanation for the class (e.g., buggy or not buggy) assigned to a piece of code. We compare the effectiveness of CounterACT with the original action rule mining algorithm and six established defect reduction approaches on 9 software projects. Our evaluation is based on (a) overlap scores between proposed code changes and actual developer modifications; (b) improvement scores in future releases; and (c) the precision, recall, and F1-score of the plans. Our results show that, compared to competing approaches, CounterACT's explainable plans achieve higher overlap scores at the release level (median 95%) and commit level (median 85.97%), and they offer better trade-off between precision and recall (median F1-score 88.12%). Finally, we venture beyond planning and explore leveraging Large Language models (LLM) for generating code edits from our generated plans. Our results show that suggested LLM code edits supported by our plans are actionable and are more likely to pass relevant test cases than vanilla LLM code recommendations.
Chain of Targeted Verification Questions to Improve the Reliability of Code Generated by LLMs
May 22, 2024



LLM-based assistants, such as GitHub Copilot and ChatGPT, have the potential to generate code that fulfills a programming task described in a natural language description, referred to as a prompt. The widespread accessibility of these assistants enables users with diverse backgrounds to generate code and integrate it into software projects. However, studies show that code generated by LLMs is prone to bugs and may miss various corner cases in task specifications. Presenting such buggy code to users can impact their reliability and trust in LLM-based assistants. Moreover, significant efforts are required by the user to detect and repair any bug present in the code, especially if no test cases are available. In this study, we propose a self-refinement method aimed at improving the reliability of code generated by LLMs by minimizing the number of bugs before execution, without human intervention, and in the absence of test cases. Our approach is based on targeted Verification Questions (VQs) to identify potential bugs within the initial code. These VQs target various nodes within the Abstract Syntax Tree (AST) of the initial code, which have the potential to trigger specific types of bug patterns commonly found in LLM-generated code. Finally, our method attempts to repair these potential bugs by re-prompting the LLM with the targeted VQs and the initial code. Our evaluation, based on programming tasks in the CoderEval dataset, demonstrates that our proposed method outperforms state-of-the-art methods by decreasing the number of targeted errors in the code between 21% to 62% and improving the number of executable code instances to 13%.
PathOCL: Path-Based Prompt Augmentation for OCL Generation with GPT-4
May 21, 2024



The rapid progress of AI-powered programming assistants, such as GitHub Copilot, has facilitated the development of software applications. These assistants rely on large language models (LLMs), which are foundation models (FMs) that support a wide range of tasks related to understanding and generating language. LLMs have demonstrated their ability to express UML model specifications using formal languages like the Object Constraint Language (OCL). However, the context size of the prompt is limited by the number of tokens an LLM can process. This limitation becomes significant as the size of UML class models increases. In this study, we introduce PathOCL, a novel path-based prompt augmentation technique designed to facilitate OCL generation. PathOCL addresses the limitations of LLMs, specifically their token processing limit and the challenges posed by large UML class models. PathOCL is based on the concept of chunking, which selectively augments the prompts with a subset of UML classes relevant to the English specification. Our findings demonstrate that PathOCL, compared to augmenting the complete UML class model (UML-Augmentation), generates a higher number of valid and correct OCL constraints using the GPT-4 model. Moreover, the average prompt size crafted using PathOCL significantly decreases when scaling the size of the UML class models.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Machine Learning Robustness: A Primer
Apr 01, 2024This chapter explores the foundational concept of robustness in Machine Learning (ML) and its integral role in establishing trustworthiness in Artificial Intelligence (AI) systems. The discussion begins with a detailed definition of robustness, portraying it as the ability of ML models to maintain stable performance across varied and unexpected environmental conditions. ML robustness is dissected through several lenses: its complementarity with generalizability; its status as a requirement for trustworthy AI; its adversarial vs non-adversarial aspects; its quantitative metrics; and its indicators such as reproducibility and explainability. The chapter delves into the factors that impede robustness, such as data bias, model complexity, and the pitfalls of underspecified ML pipelines. It surveys key techniques for robustness assessment from a broad perspective, including adversarial attacks, encompassing both digital and physical realms. It covers non-adversarial data shifts and nuances of Deep Learning (DL) software testing methodologies. The discussion progresses to explore amelioration strategies for bolstering robustness, starting with data-centric approaches like debiasing and augmentation. Further examination includes a variety of model-centric methods such as transfer learning, adversarial training, and randomized smoothing. Lastly, post-training methods are discussed, including ensemble techniques, pruning, and model repairs, emerging as cost-effective strategies to make models more resilient against the unpredictable. This chapter underscores the ongoing challenges and limitations in estimating and achieving ML robustness by existing approaches. It offers insights and directions for future research on this crucial concept, as a prerequisite for trustworthy AI systems.
Bugs in Large Language Models Generated Code: An Empirical Study
Mar 18, 2024



Large Language Models (LLMs) for code have gained significant attention recently. They can generate code in different programming languages based on provided prompts, fulfilling a long-lasting dream in Software Engineering (SE), i.e., automatic code generation. Similar to human-written code, LLM-generated code is prone to bugs, and these bugs have not yet been thoroughly examined by the community. Given the increasing adoption of LLM-based code generation tools (e.g., GitHub Copilot) in SE activities, it is critical to understand the characteristics of bugs contained in code generated by LLMs. This paper examines a sample of 333 bugs collected from code generated using three leading LLMs (i.e., CodeGen, PanGu-Coder, and Codex) and identifies the following 10 distinctive bug patterns: Misinterpretations, Syntax Error, Silly Mistake, Prompt-biased code, Missing Corner Case, Wrong Input Type, Hallucinated Object, Wrong Attribute, Incomplete Generation, and Non-Prompted Consideration. The bug patterns are presented in the form of a taxonomy. The identified bug patterns are validated using an online survey with 34 LLM practitioners and researchers. The surveyed participants generally asserted the significance and prevalence of the bug patterns. Researchers and practitioners can leverage these findings to develop effective quality assurance techniques for LLM-generated code. This study sheds light on the distinctive characteristics of LLM-generated code.
Trained Without My Consent: Detecting Code Inclusion In Language Models Trained on Code
Feb 14, 2024



Code auditing ensures that the developed code adheres to standards, regulations, and copyright protection by verifying that it does not contain code from protected sources. The recent advent of Large Language Models (LLMs) as coding assistants in the software development process poses new challenges for code auditing. The dataset for training these models is mainly collected from publicly available sources. This raises the issue of intellectual property infringement as developers' codes are already included in the dataset. Therefore, auditing code developed using LLMs is challenging, as it is difficult to reliably assert if an LLM used during development has been trained on specific copyrighted codes, given that we do not have access to the training datasets of these models. Given the non-disclosure of the training datasets, traditional approaches such as code clone detection are insufficient for asserting copyright infringement. To address this challenge, we propose a new approach, TraWiC; a model-agnostic and interpretable method based on membership inference for detecting code inclusion in an LLM's training dataset. We extract syntactic and semantic identifiers unique to each program to train a classifier for detecting code inclusion. In our experiments, we observe that TraWiC is capable of detecting 83.87% of codes that were used to train an LLM. In comparison, the prevalent clone detection tool NiCad is only capable of detecting 47.64%. In addition to its remarkable performance, TraWiC has low resource overhead in contrast to pair-wise clone detection that is conducted during the auditing process of tools like CodeWhisperer reference tracker, across thousands of code snippets.