 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Image Transformer
May 03, 2021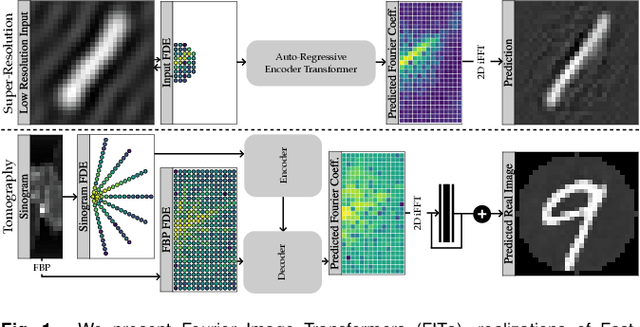
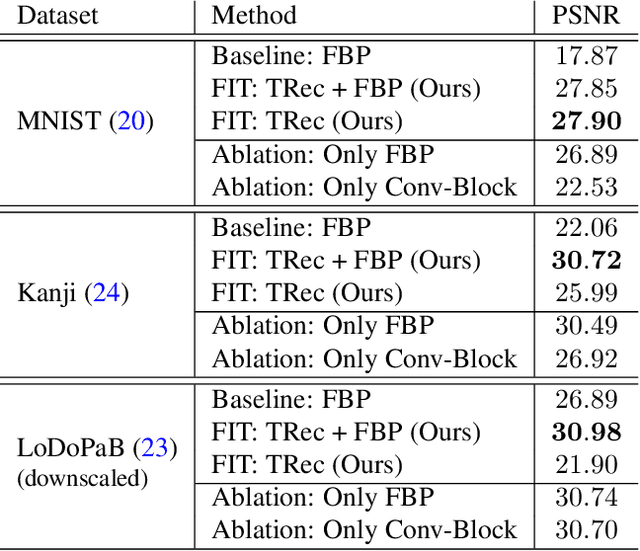
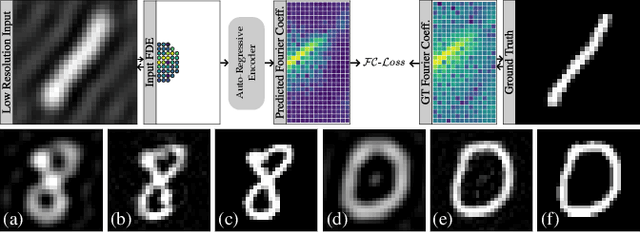
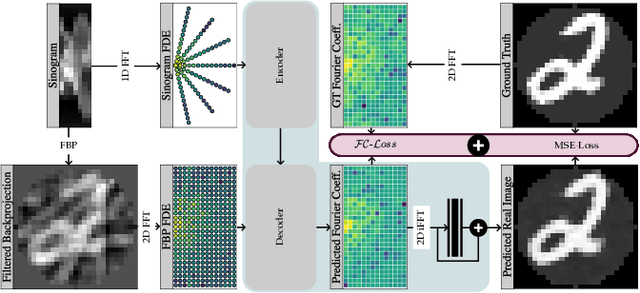
Transformer architectures show spectacular performance on NLP tasks and have recently also been used for tasks such as image completion or image classification. Here we propose to use a sequential image representation, where each prefix of the complete sequence describes the whole image at reduced resolution. Using such Fourier Domain Encodings (FDEs), an auto-regressive image completion task is equivalent to predicting a higher resolution output given a low-resolution input. Additionally, we show that an encoder-decoder setup can be used to query arbitrary Fourier coefficients given a set of Fourier domain observations. We demonstrate the practicality of this approach in the context of computed tomography (CT) image reconstruction. In summary, we show that Fourier Image Transformer (FIT) can be used to solve relevant image analysis tasks in Fourier space, a domain inherently inaccessible to convolutional architectures.
Removing Pixel Noises and Spatial Artifacts with Generative Diversity Denoising Methods
Apr 03, 2021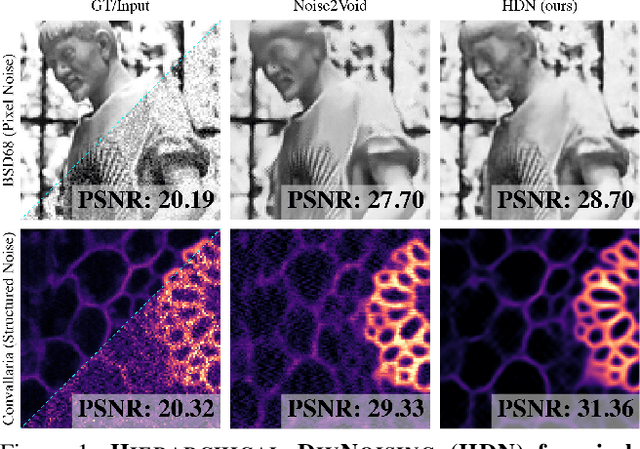
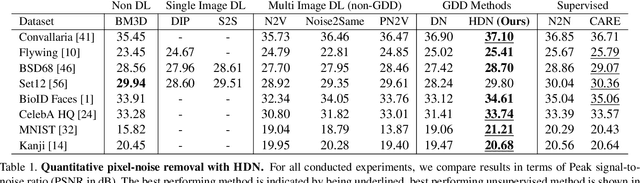
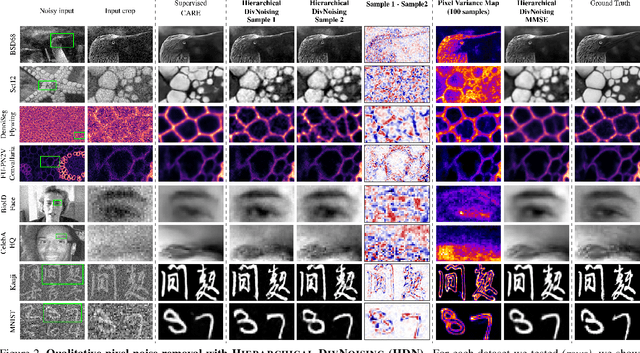

Image denoising and artefact removal are complex inverse problems admitting many potential solutions. Variational Autoencoders (VAEs) can be used to learn a whole distribution of sensible solutions, from which one can sample efficiently. However, such a generative approach to image restoration is only studied in the context of pixel-wise noise removal (e.g. Poisson or Gaussian noise). While important, a plethora of application domains suffer from imaging artefacts (structured noises) that alter groups of pixels in correlated ways. In this work we show, for the first time, that generative diversity denoising (GDD) approaches can learn to remove structured noises without supervision. To this end, we investigate two existing GDD architectures, introduce a new one based on hierarchical VAEs, and compare their performances against a total of seven state-of-the-art baseline methods on five sources of structured noise (including tomography reconstruction artefacts and microscopy artefacts). We find that GDD methods outperform all unsupervised baselines and in many cases not lagging far behind supervised results (in some occasions even superseding them). In addition to structured noise removal, we also show that our new GDD method produces new state-of-the-art (SOTA) results on seven out of eight benchmark datasets for pixel-noise removal. Finally, we offer insights into the daunting question of how GDD methods distinguish structured noise, which we like to see removed, from image signals, which we want to see retained.
Embedding-based Instance Segmentation of Microscopy Images
Jan 25, 2021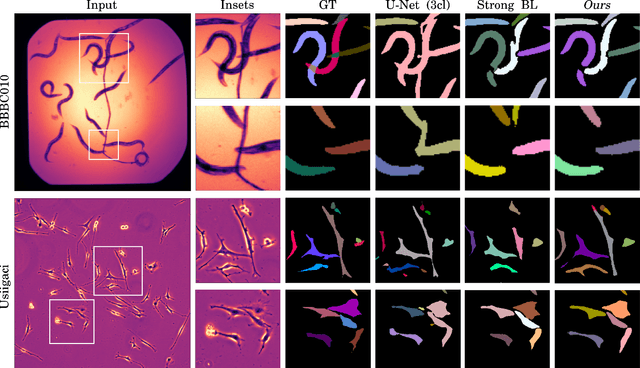
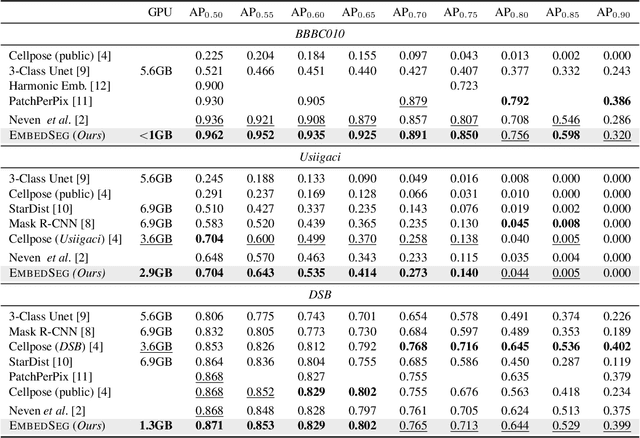
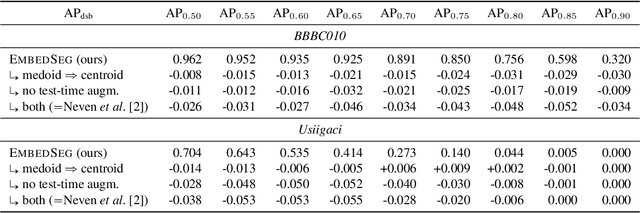
Automatic detection and segmentation of objects in microscopy images is important for many biological applications. In the domain of natural images, and in particular in the context of city street scenes, embedding-based instance segmentation leads to high-quality results. Inspired by this line of work, we introduce EmbedSeg, an end-to-end trainable deep learning method based on the work by Neven et al. While their approach embeds each pixel to the centroid of any given instance, in EmbedSeg, motivated by the complex shapes of biological objects, we propose to use the medoid instead. Additionally, we make use of a test-time augmentation scheme, and show that both suggested modifications improve the instance segmentation performance on biological microscopy datasets notably. We demonstrate that embedding-based instance segmentation achieves competitive results in comparison to state-of-the-art methods on diverse and biologically relevant microscopy datasets. Finally, we show that the overall pipeline has a small enough memory footprint to be used on virtually all CUDA enabled laptop hardware. Our open-source implementation is available at github.com/juglab/EmbedSeg.
Improving Blind Spot Denoising for Microscopy
Aug 19, 2020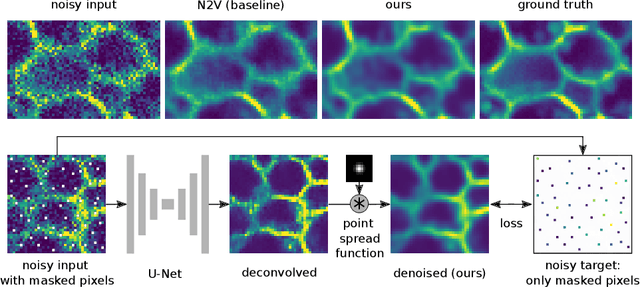
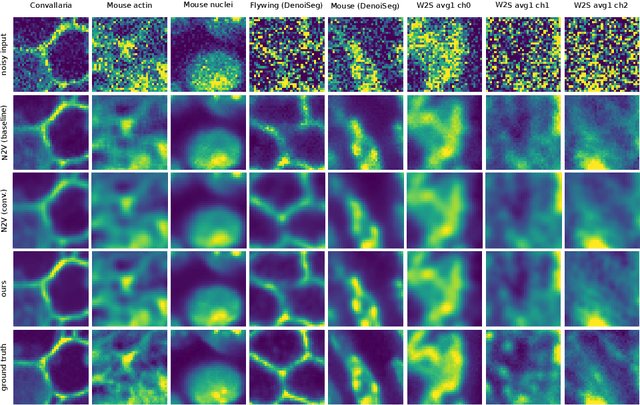
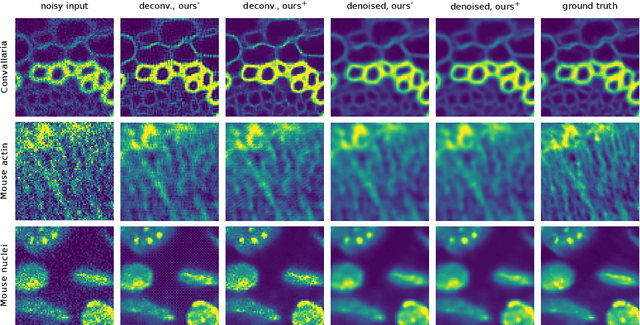
Many microscopy applications are limited by the total amount of usable light and are consequently challenged by the resulting levels of noise in the acquired images. This problem is often addressed via (supervised) deep learning based denoising. Recently, by making assumptions about the noise statistics, self-supervised methods have emerged. Such methods are trained directly on the images that are to be denoised and do not require additional paired training data. While achieving remarkable results, self-supervised methods can produce high-frequency artifacts and achieve inferior results compared to supervised approaches. Here we present a novel way to improve the quality of self-supervised denoising. Considering that light microscopy images are usually diffraction-limited, we propose to include this knowledge in the denoising process. We assume the clean image to be the result of a convolution with a point spread function (PSF) and explicitly include this operation at the end of our neural network. As a consequence, we are able to eliminate high-frequency artifacts and achieve self-supervised results that are very close to the ones achieved with traditional supervised methods.
DivNoising: Diversity Denoising with Fully Convolutional Variational Autoencoders
Jun 10, 2020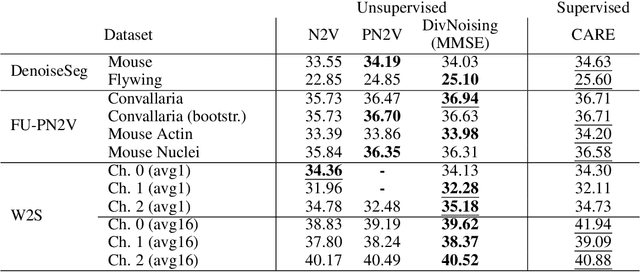
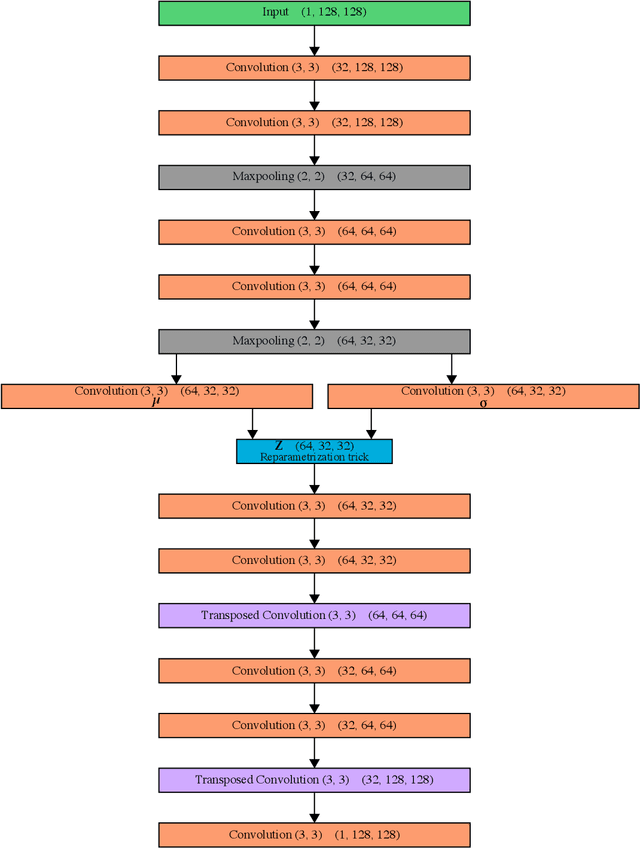
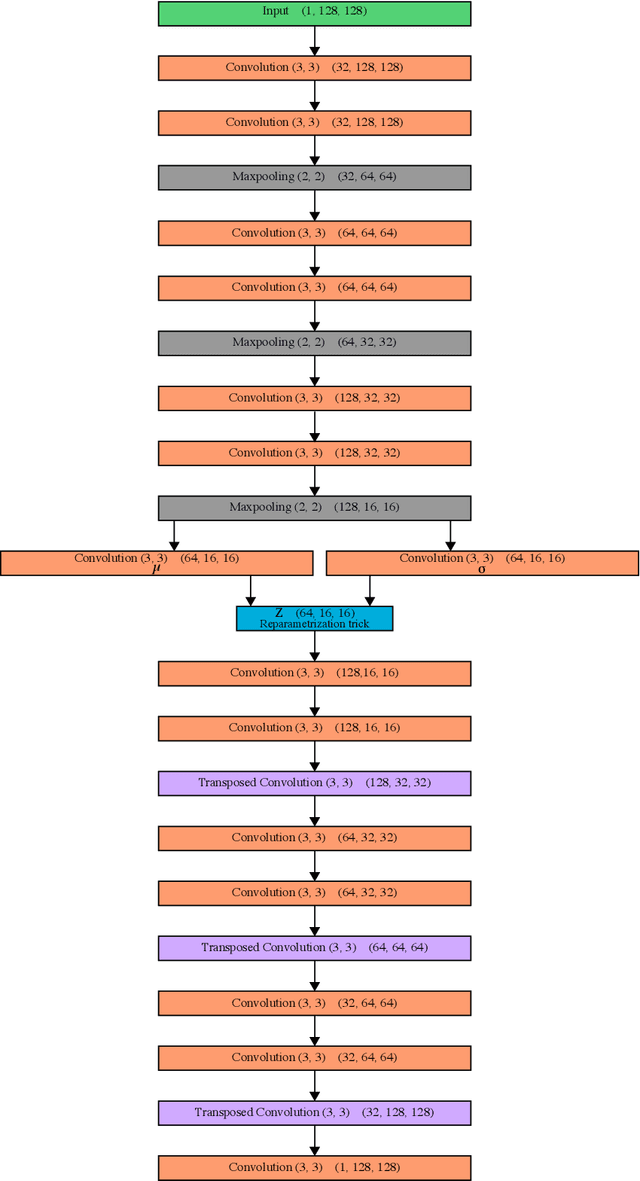
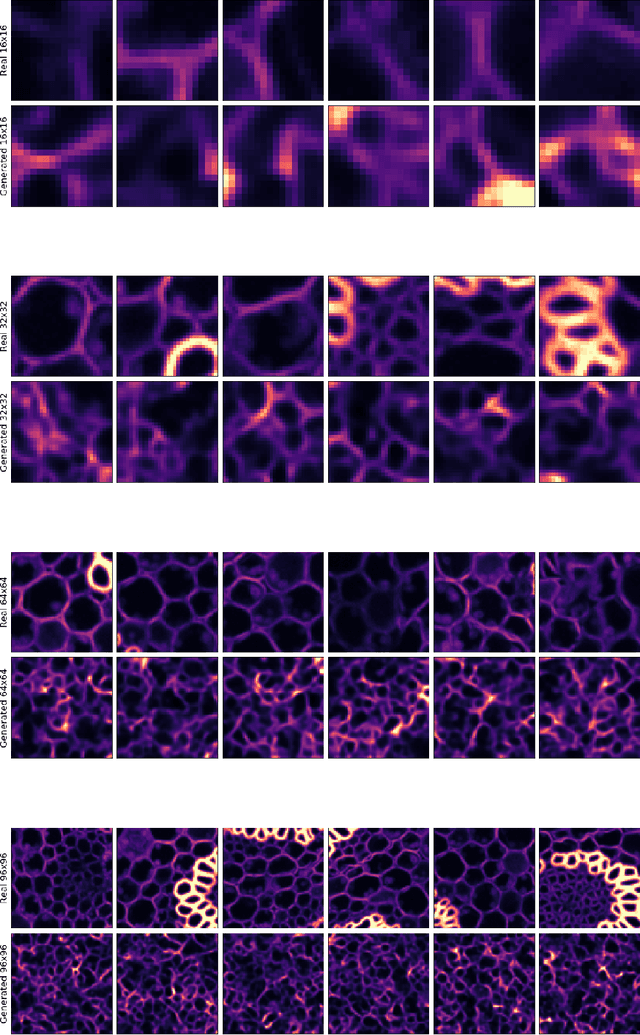
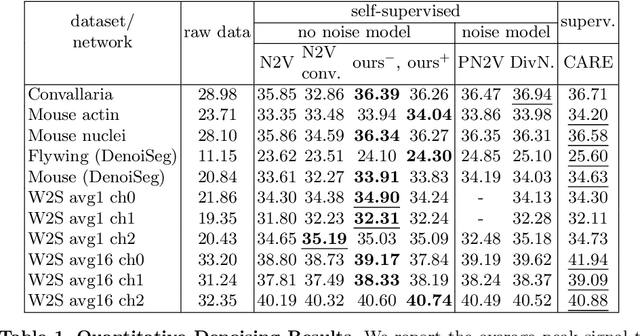
Deep Learning based methods have emerged as the indisputable leaders for virtually all image restoration tasks. Especially in the domain of microscopy images, various content-aware image restoration (CARE) approaches are now used to improve the interpretability of acquired data. But there are limitations to what can be restored in corrupted images, and any given method needs to make a sensible compromise between many possible clean signals when predicting a restored image. Here, we propose DivNoising -- a denoising approach based on fully-convolutional variational autoencoders, overcoming this problem by predicting a whole distribution of denoised images. Our method is unsupervised, requiring only noisy images and a description of the imaging noise, which can be measured or bootstrapped from noisy data. If desired, consensus predictions can be inferred from a set of DivNoising predictions, leading to competitive results with other unsupervised methods and, on occasion, even with the supervised state-of-the-art. DivNoising samples from the posterior enable a plethora of useful applications. We are (i) discussing how optical character recognition (OCR) applications could benefit from diverse predictions on ambiguous data, and (ii) show in detail how instance cell segmentation gains performance when using diverse DivNoising predictions.
DenoiSeg: Joint Denoising and Segmentation
May 06, 2020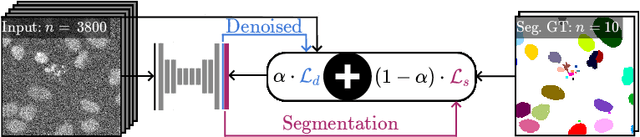

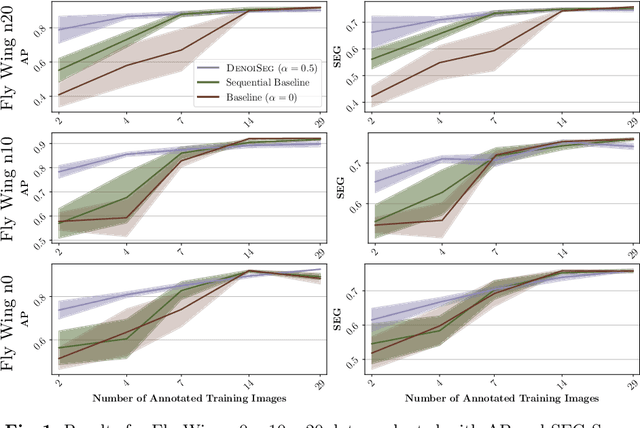
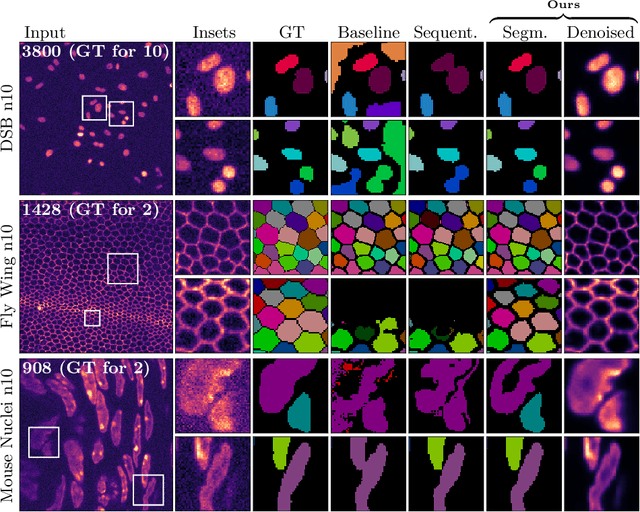
Microscopy image analysis often requires the segmentation of objects, but training data for this task is typically scarce and hard to obtain. Here we propose DenoiSeg, a new method that can be trained end-to-end on only a few annotated ground truth segmentations. We achieve this by extending Noise2Void, a self-supervised denoising scheme that can be trained on noisy images alone, to also predict dense 3-class segmentations. The reason for the success of our method is that segmentation can profit from denoising, especially when performed jointly within the same network. The network becomes a denoising expert by seeing all available raw data, while co-learning to segment, even if only a few segmentation labels are available. This hypothesis is additionally fueled by our observation that the best segmentation results on high quality (very low noise) raw data are obtained when moderate amounts of synthetic noise are added. This renders the denoising-task non-trivial and unleashes the desired co-learning effect. We believe that DenoiSeg offers a viable way to circumvent the tremendous hunger for high quality training data and effectively enables few-shot learning of dense segmentations.
A Primal-Dual Solver for Large-Scale Tracking-by-Assignment
Apr 14, 2020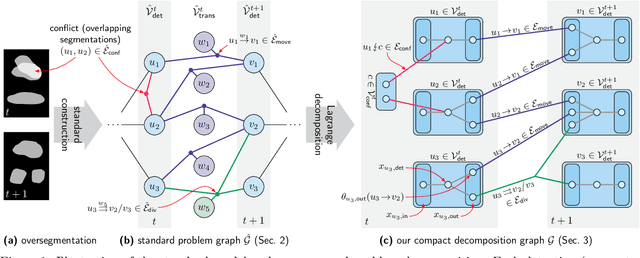
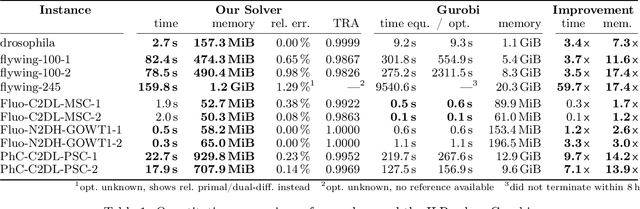
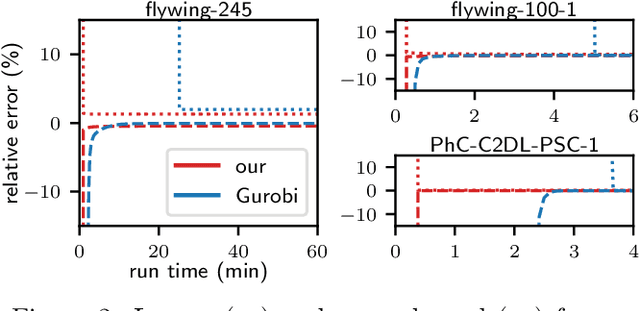
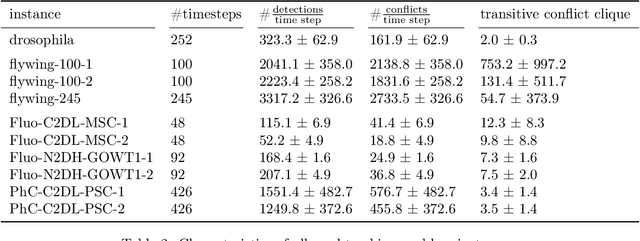
We propose a fast approximate solver for the combinatorial problem known as tracking-by-assignment, which we apply to cell tracking. The latter plays a key role in discovery in many life sciences, especially in cell and developmental biology. So far, in the most general setting this problem was addressed by off-the-shelf solvers like Gurobi, whose run time and memory requirements rapidly grow with the size of the input. In contrast, for our method this growth is nearly linear. Our contribution consists of a new (1) decomposable compact representation of the problem; (2) dual block-coordinate ascent method for optimizing the decomposition-based dual; and (3) primal heuristics that reconstructs a feasible integer solution based on the dual information. Compared to solving the problem with Gurobi, we observe an up to~60~times speed-up, while reducing the memory footprint significantly. We demonstrate the efficacy of our method on real-world tracking problems.
Leveraging Self-supervised Denoising for Image Segmentation
Dec 13, 2019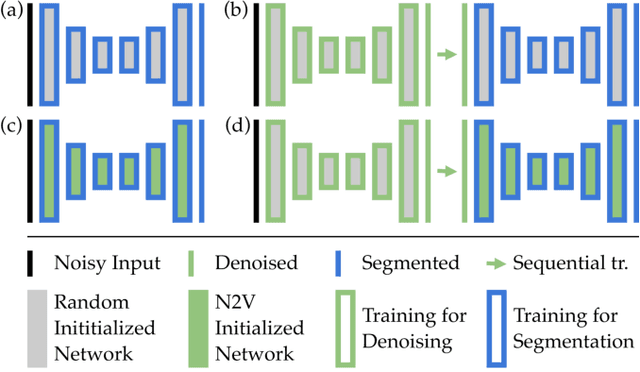
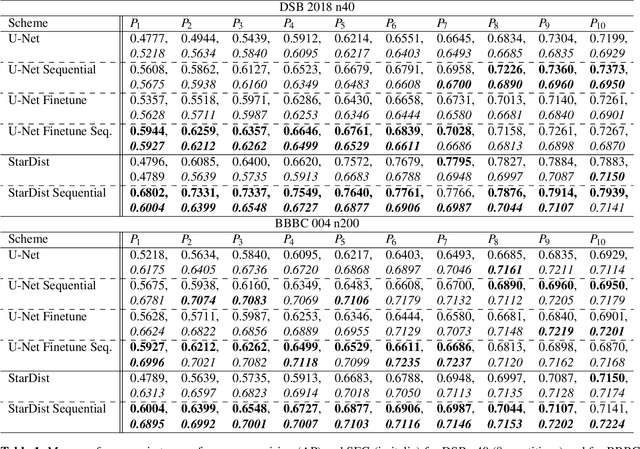
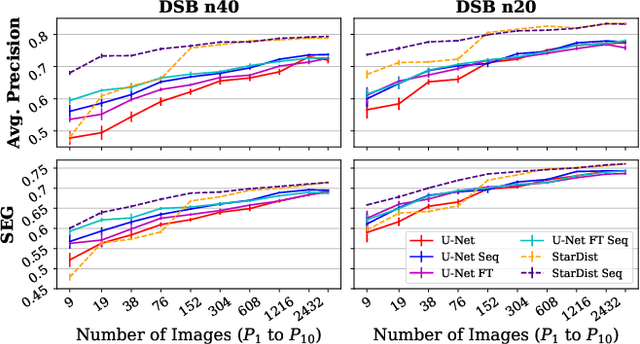
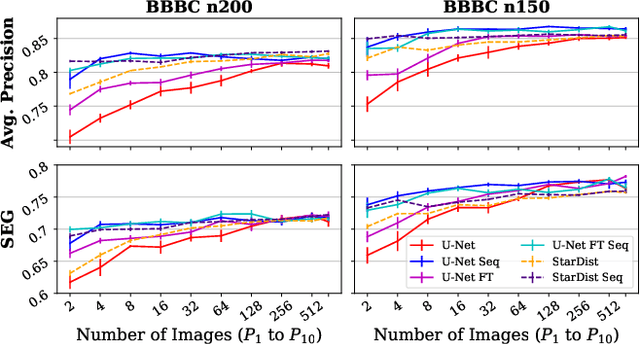
Deep learning (DL) has arguably emerged as the method of choice for the detection and segmentation of biological structures in microscopy images. However, DL typically needs copious amounts of annotated training data that is for biomedical projects typically not available and excessively expensive to generate. Additionally, tasks become harder in the presence of noise, requiring even more high-quality training data. Hence, we propose to use denoising networks to improve the performance of other DL-based image segmentation methods. More specifically, we present ideas on how state-of-the-art self-supervised CARE networks can improve cell/nuclei segmentation in microscopy data. Using two state-of-the-art baseline methods, U-Net and StarDist, we show that our ideas consistently improve the quality of resulting segmentations, especially when only limited training data for noisy micrographs are available.
Fully Unsupervised Probabilistic Noise2Void
Nov 27, 2019
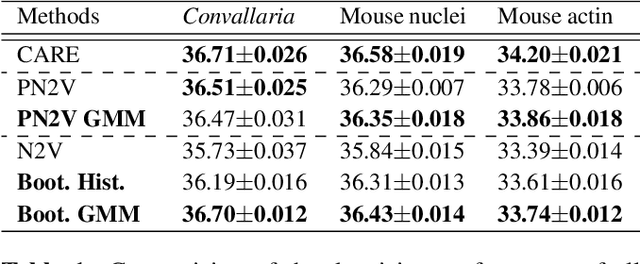

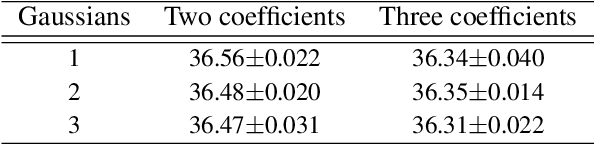
Image denoising is the first step in many biomedical image analysis pipelines and Deep Learning (DL) based methods are currently best performing. A new category of DL methods such as Noise2Void or Noise2Self can be used fully unsupervised, requiring nothing but the noisy data. However, this comes at the price of reduced reconstruction quality. The recently proposed Probabilistic Noise2Void (PN2V) improves results, but requires an additional noise model for which calibration data needs to be acquired. Here, we present improvements to PN2V that (i) replace histogram based noise models by parametric noise models, and (ii) show how suitable noise models can be created even in the absence of calibration data. This is a major step since it actually renders PN2V fully unsupervised. We demonstrate that all proposed improvements are not only academic but indeed relevant.
Probabilistic Noise2Void: Unsupervised Content-Aware Denoising
Jun 04, 2019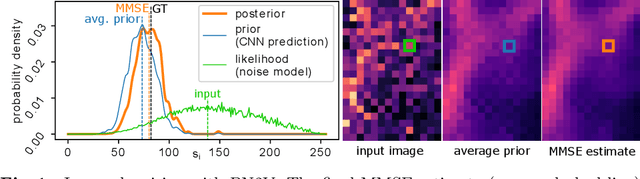
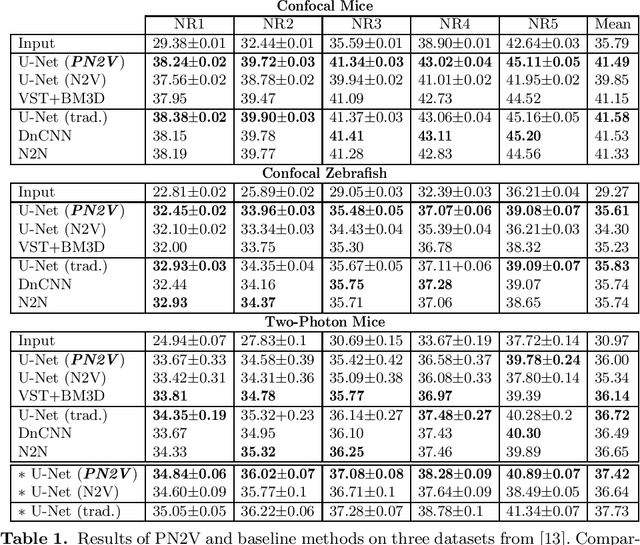

Today, Convolutional Neural Networks (CNNs) are the leading method for image denoising. They are traditionally trained on pairs of images, which are often hard to obtain for practical applications. This motivates self-supervised training methods such as Noise2Void~(N2V) that operate on single noisy images. Self-supervised methods are, unfortunately, not competitive with models trained on image pairs. Here, we present 'Probabilistic Noise2Void' (PN2V), a method to train CNNs to predict per-pixel intensity distributions. Combining these with a suitable description of the noise, we obtain a complete probabilistic model for the noisy observations and true signal in every pixel. We evaluate PN2V on publicly available microscopy datasets, under a broad range of noise regimes, and achieve competitive results with respect to supervised state-of-the-art methods.