 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan predictive models be used for causal inference?
Jun 18, 2023Supervised machine learning (ML) and deep learning (DL) algorithms excel at predictive tasks, but it is commonly assumed that they often do so by exploiting non-causal correlations, which may limit both interpretability and generalizability. Here, we show that this trade-off between explanation and prediction is not as deep and fundamental as expected. Whereas ML and DL algorithms will indeed tend to use non-causal features for prediction when fed indiscriminately with all data, it is possible to constrain the learning process of any ML and DL algorithm by selecting features according to Pearl's backdoor adjustment criterion. In such a situation, some algorithms, in particular deep neural networks, can provide near unbiased effect estimates under feature collinearity. Remaining biases are explained by the specific algorithmic structures as well as hyperparameter choice. Consequently, optimal hyperparameter settings are different when tuned for prediction or inference, confirming the general expectation of a trade-off between prediction and explanation. However, the effect of this trade-off is small compared to the effect of a causally constrained feature selection. Thus, once the causal relationship between the features is accounted for, the difference between prediction and explanation may be much smaller than commonly assumed. We also show that such causally constrained models generalize better to new data with altered collinearity structures, suggesting generalization failure may often be due to a lack of causal learning. Our results not only provide a perspective for using ML for inference of (causal) effects but also help to improve the generalizability of fitted ML and DL models to new data.
cito: An R package for training neural networks using torch
Mar 16, 20231. Deep neural networks (DNN) have become a central class of algorithms for regression and classification tasks. Although some packages exist that allow users to specify DNN in R, those are rather limited in their functionality. Most current deep learning applications therefore rely on one of the major deep learning frameworks, PyTorch or TensorFlow, to build and train DNN. However, using these frameworks requires substantially more training and time than comparable regression or machine learning packages in the R environment. 2. Here, we present cito, an user-friendly R package for deep learning. cito allows R users to specify deep neural networks in the familiar formula syntax used by most modeling functions in R. In the background, cito uses torch to fit the models, taking advantage of all the numerical optimizations of the torch library, including the ability to switch between training models on CPUs or GPUs. Moreover, cito includes many user-friendly functions for predictions and an explainable Artificial Intelligence (xAI) pipeline for the fitted models. 3. We showcase a typical analysis pipeline using cito, including its built-in xAI features to explore the trained DNN, by building a species distribution model of the African elephant. 4. In conclusion, cito provides a user-friendly R framework to specify, deploy and interpret deep neural networks based on torch. The current stable CRAN version mainly supports fully connected DNNs, but it is planned that future versions will also include CNNs and RNNs.
Machine Learning and Deep Learning -- A review for Ecologists
Apr 11, 2022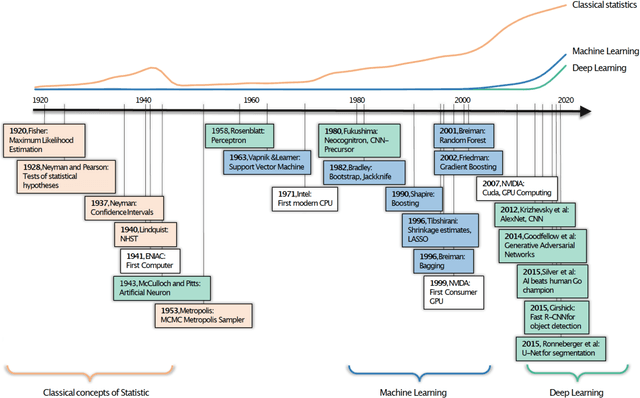
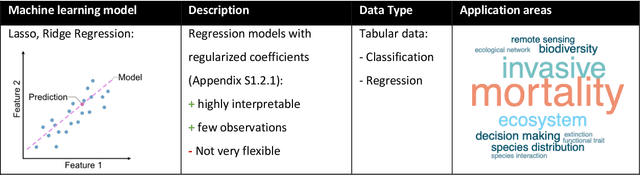
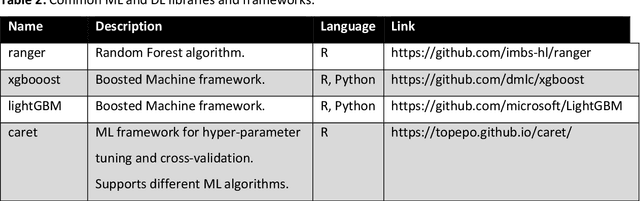
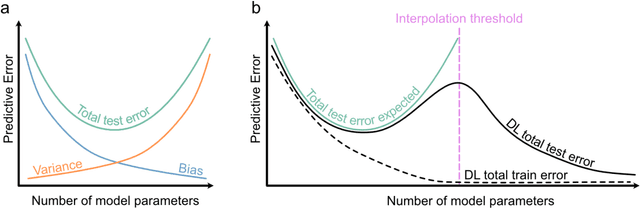
The popularity of Machine learning (ML), Deep learning (DL), and Artificial intelligence (AI) has sharply risen in recent years. Despite their spike in popularity, the inner workings of ML and DL algorithms are perceived as opaque, and their relationship to classical data analysis tools remains debated. It is often assumed that ML and DL excel primarily at making predictions. Recently, however, they have been increasingly used for classical analytical tasks traditionally covered by statistical models. Moreover, recent reviews on ML have focused exclusively on DL, missing out on synthesizing the wealth of ML algorithms with different advantages and general principles. Here, we provide a comprehensive overview of ML and DL, starting with their historical developments, their algorithm families, their differences from traditional statistical tools, and universal ML principles. We then discuss why and when ML and DL excel at prediction tasks, and where they could offer alternatives to traditional statistical methods for inference, highlighting current and emerging applications for ecological problems. Finally, we summarize emerging trends, particularly scientific and causal ML, explainable AI, and responsible AI that may significantly impact ecological data analysis in the future.
Machine learning algorithms to infer trait matching and predict species interactions in ecological networks
Aug 26, 2019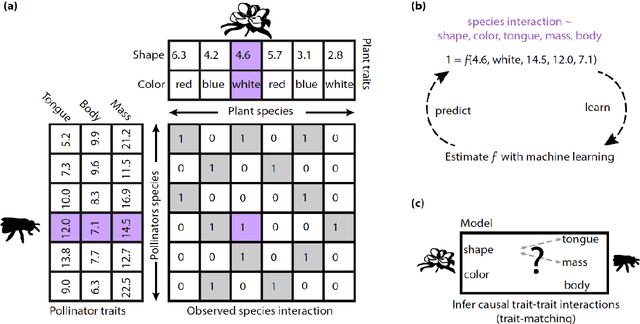
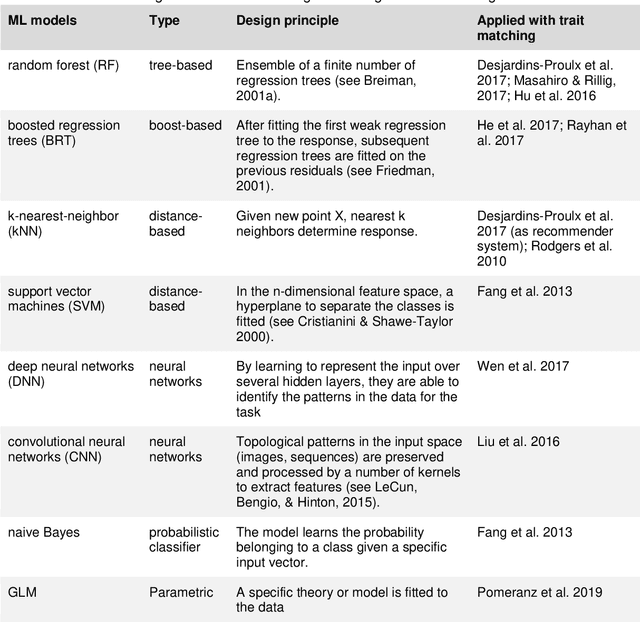
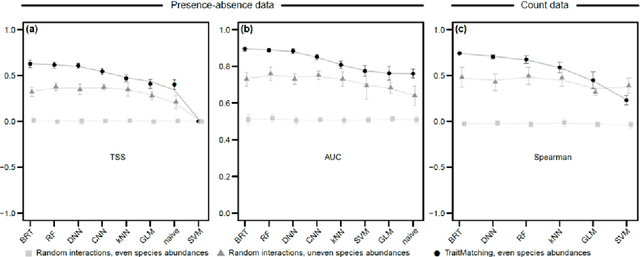
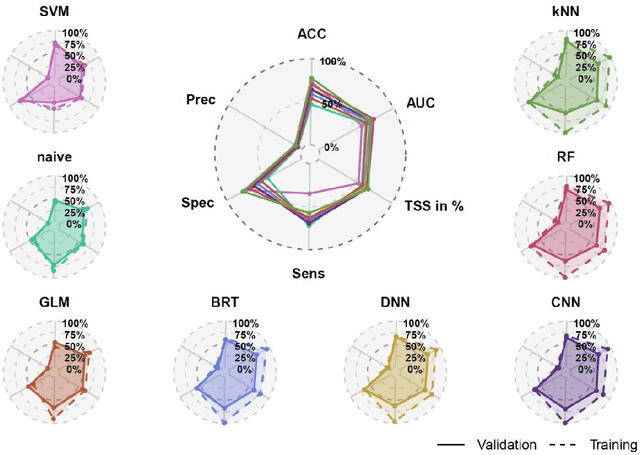
Ecologists have long suspected that species are more likely to interact if their traits match in a particular way. For example, a pollination interaction may be particularly likely if the proportions of a bee's tongue match flower shape in a beneficial way. Empirical evidence for trait matching, however, varies significantly in strength among different types of ecological networks. Here, we show that ambiguity among empirical trait matching studies may have arisen at least in parts from using overly simple statistical models. Using simulated and real data, we contrast conventional regression models with Machine Learning (ML) models (Random Forest, Boosted Regression Trees, Deep Neural Networks, Convolutional Neural Networks, Support Vector Machines, naive Bayes, and k-Nearest-Neighbor), testing their ability to predict species interactions based on traits, and infer trait combinations causally responsible for species interactions. We find that the best ML models can successfully predict species interactions in plant-pollinator networks (up to 0.93 AUC) and outperform conventional regression models. Our results also demonstrate that ML models can better identify the causally responsible trait matching combinations than GLMs. In two case studies, the best ML models could successfully predict species interactions in a global plant-pollinator database and infer ecologically plausible trait matching rules for a plant-hummingbird network from Costa Rica, without any prior assumptions about the system. We conclude that flexible ML models offer many advantages over traditional regression models for understanding interaction networks. We anticipate that these results extrapolate to other network types, such as trophic or competitive networks. More generally, our results highlight the potential of ML and artificial intelligence for inference beyond standard tasks such as pattern recognition.