 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Learning Algorithms on Data, a useful step for optimizing performances and their comparison
Jul 14, 2021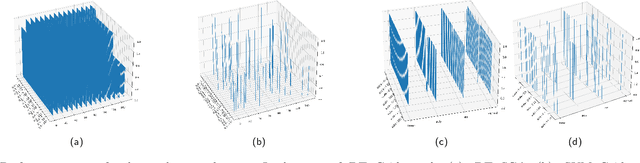
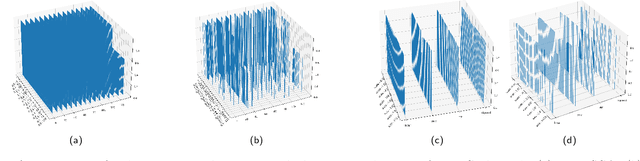
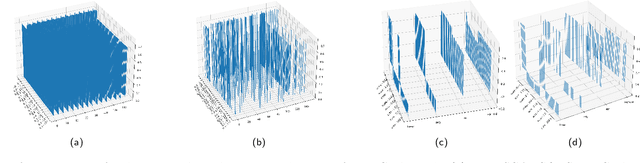
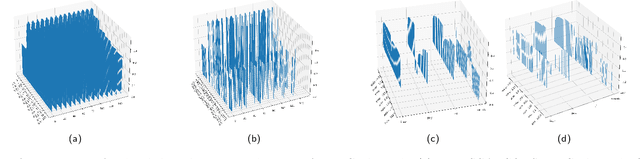
In the paper, we propose a novel methodology to map learning algorithms on data (performance map) in order to gain more insights in the distribution of their performances across their parameter space. This methodology provides useful information when selecting a learner's best configuration for the data at hand, and it also enhances the comparison of learners across learning contexts. In order to explain the proposed methodology, the study introduces the notions of learning context, performance map, and high performance function. It then applies these concepts to a variety of learning contexts to show how their use can provide more insights in a learner's behavior, and can enhance the comparison of learners across learning contexts. The study is completed by an extensive experimental study describing how the proposed methodology can be applied.
Domain Specific Concept Drift Detectors for Predicting Financial Time Series
Mar 22, 2021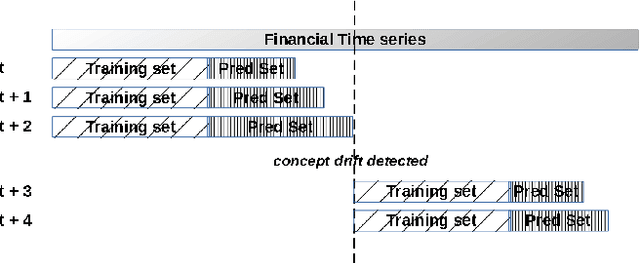
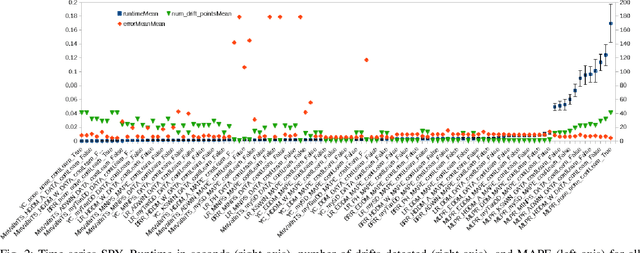
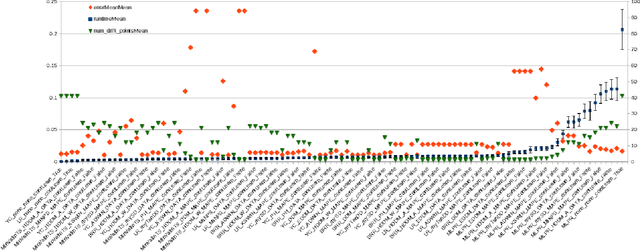
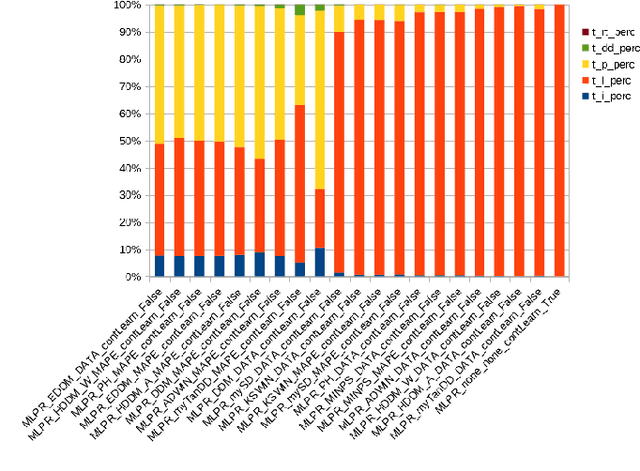
Concept drift detectors allow learning systems to maintain good accuracy on non-stationary data streams. Financial time series are an instance of non-stationary data streams whose concept drifts (market phases) are so important to affect investment decisions worldwide. This paper studies how concept drift detectors behave when applied to financial time series. General results are: a) concept drift detectors usually improve the runtime over continuous learning, b) their computational cost is usually a fraction of the learning and prediction steps of even basic learners, c) it is important to study concept drift detectors in combination with the learning systems they will operate with, and d) concept drift detectors can be directly applied to the time series of raw financial data and not only to the model's accuracy one. Moreover, the study introduces three simple concept drift detectors, tailored to financial time series, and shows that two of them can be at least as effective as the most sophisticated ones from the state of the art when applied to financial time series.
How to Identify Investor's types in real financial markets by means of agent based simulation
Dec 31, 2020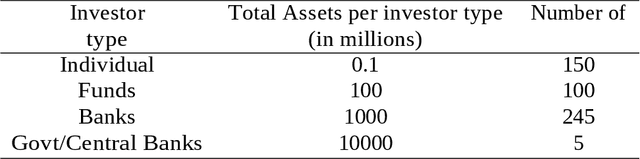
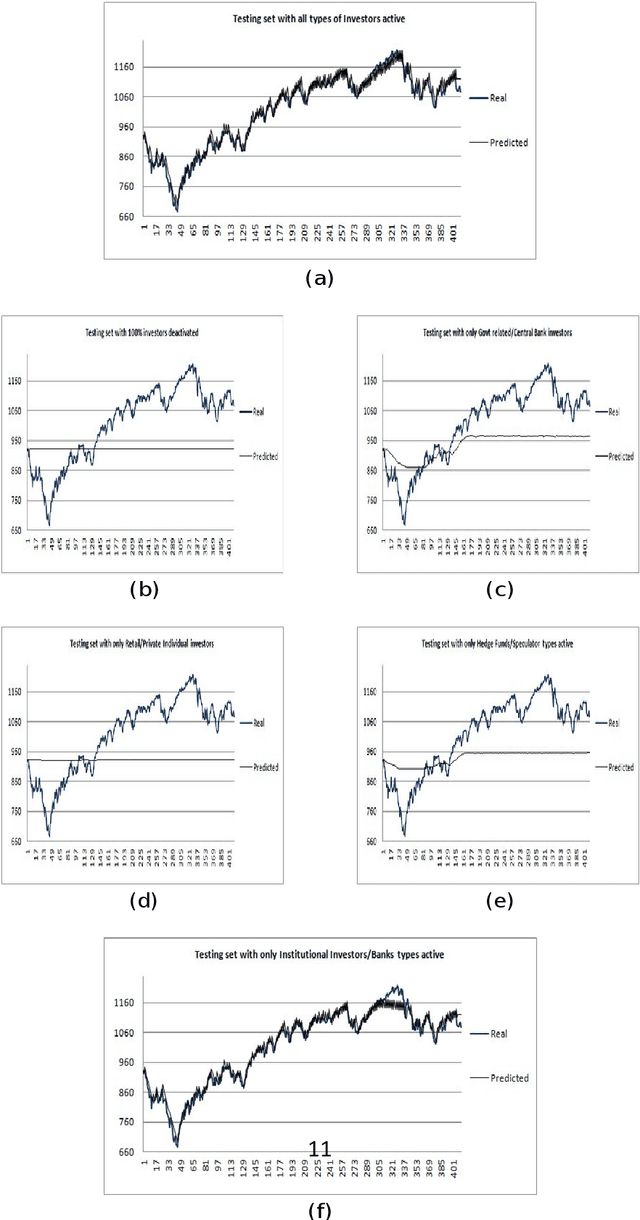
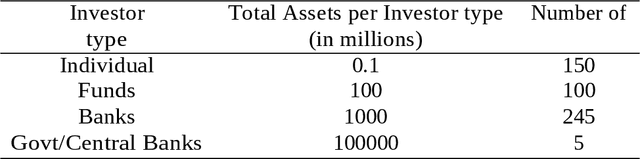
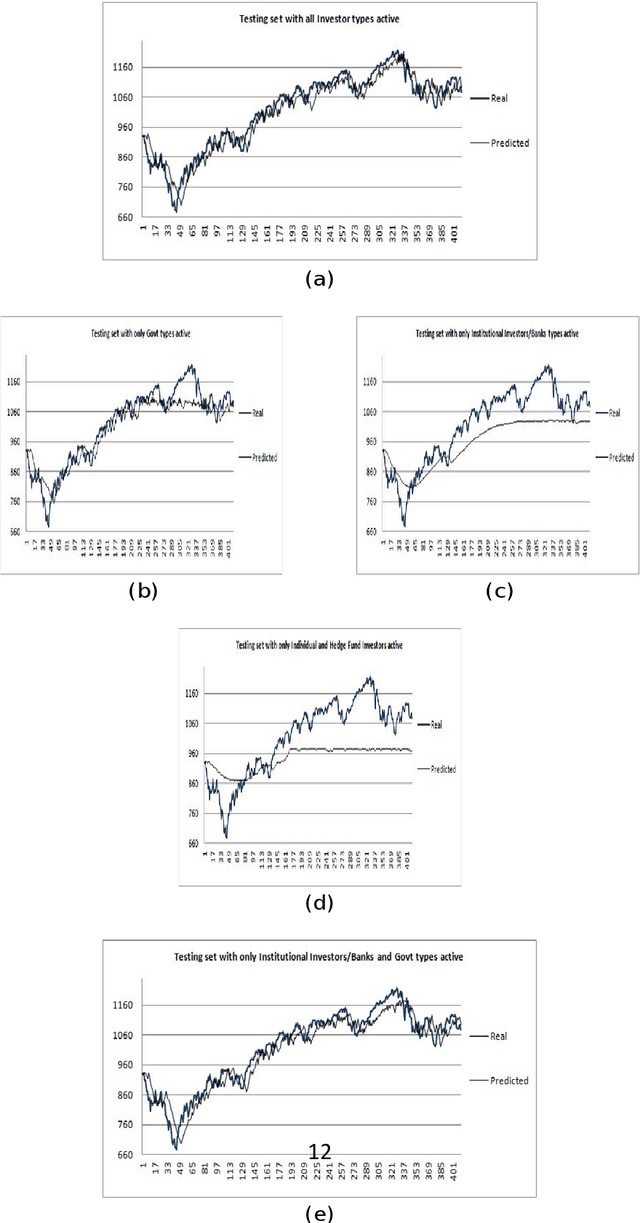
The paper proposes a computational adaptation of the principles underlying principal component analysis with agent based simulation in order to produce a novel modeling methodology for financial time series and financial markets. Goal of the proposed methodology is to find a reduced set of investor s models (agents) which is able to approximate or explain a target financial time series. As computational testbed for the study, we choose the learning system L FABS which combines simulated annealing with agent based simulation for approximating financial time series. We will also comment on how L FABS s architecture could exploit parallel computation to scale when dealing with massive agent simulations. Two experimental case studies showing the efficacy of the proposed methodology are reported.