 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning from Continuous Video in a Scalable Predictive Recurrent Network
Sep 30, 2016



Understanding visual reality involves acquiring common-sense knowledge about countless regularities in the visual world, e.g., how illumination alters the appearance of objects in a scene, and how motion changes their apparent spatial relationship. These regularities are hard to label for training supervised machine learning algorithms; consequently, algorithms need to learn these regularities from the real world in an unsupervised way. We present a novel network meta-architecture that can learn world dynamics from raw, continuous video. The components of this network can be implemented using any algorithm that possesses three key capabilities: prediction of a signal over time, reduction of signal dimensionality (compression), and the ability to use supplementary contextual information to inform the prediction. The presented architecture is highly-parallelized and scalable, and is implemented using localized connectivity, processing, and learning. We demonstrate an implementation of this architecture where the components are built from multi-layer perceptrons. We apply the implementation to create a system capable of stable and robust visual tracking of objects as seen by a moving camera. Results show performance on par with or exceeding state-of-the-art tracking algorithms. The tracker can be trained in either fully supervised or unsupervised-then-briefly-supervised regimes. Success of the briefly-supervised regime suggests that the unsupervised portion of the model extracts useful information about visual reality. The results suggest a new class of AI algorithms that uniquely combine prediction and scalability in a way that makes them suitable for learning from and --- and eventually acting within --- the real world.
Fundamental principles of cortical computation: unsupervised learning with prediction, compression and feedback
Aug 19, 2016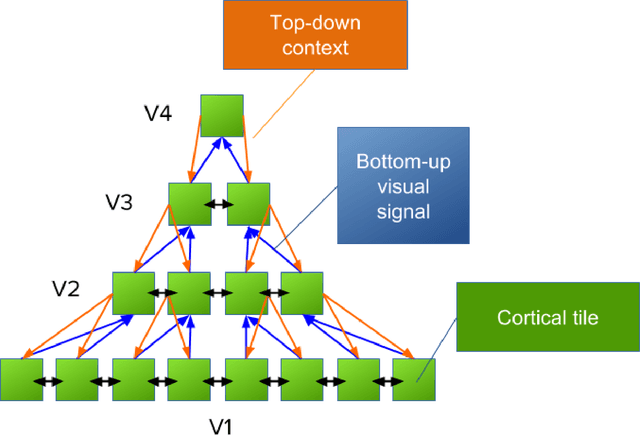



There has been great progress in understanding of anatomical and functional microcircuitry of the primate cortex. However, the fundamental principles of cortical computation - the principles that allow the visual cortex to bind retinal spikes into representations of objects, scenes and scenarios - have so far remained elusive. In an attempt to come closer to understanding the fundamental principles of cortical computation, here we present a functional, phenomenological model of the primate visual cortex. The core part of the model describes four hierarchical cortical areas with feedforward, lateral, and recurrent connections. The three main principles implemented in the model are information compression, unsupervised learning by prediction, and use of lateral and top-down context. We show that the model reproduces key aspects of the primate ventral stream of visual processing including Simple and Complex cells in V1, increasingly complicated feature encoding, and increased separability of object representations in higher cortical areas. The model learns representations of the visual environment that allow for accurate classification and state-of-the-art visual tracking performance on novel objects.