 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching CUDA code autotuning spaces with hardware performance counters: data from benchmarks running on various GPU architectures
Feb 10, 2021


We have developed several autotuning benchmarks in CUDA that take into account performance-relevant source-code parameters and reach near peak-performance on various GPU architectures. We have used them during the development and evaluation of a novel search method for tuning space proposed in [1]. With our framework Kernel Tuning Toolkit, freely available at Github, we measured computation times and hardware performance counters on several GPUs for the complete tuning spaces of five benchmarks. These data, which we provide here, might benefit research of search algorithms for the tuning spaces of GPU codes or research of relation between applied code optimization, hardware performance counters, and GPU kernels' performance. Moreover, we describe the scripts we used for robust evaluation of our searcher and comparison to others in detail. In particular, the script that simulates the tuning, i.e., replaces time-demanding compiling and executing the tuned kernels with a quick reading of the computation time from our measured data, makes it possible to inspect the convergence of tuning search over a large number of experiments. These scripts, freely available with our other codes, make it easier to experiment with search algorithms and compare them in a robust way. During our research, we generated models for predicting values of performance counters from values of tuning parameters of our benchmarks. Here, we provide the models themselves and describe the scripts we implemented for their training. These data might benefit researchers who want to reproduce or build on our research.
Using hardware performance counters to speed up autotuning convergence on GPUs
Feb 10, 2021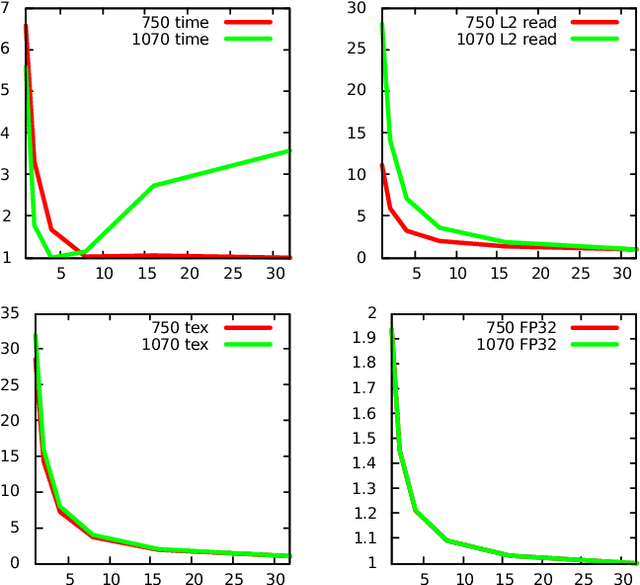

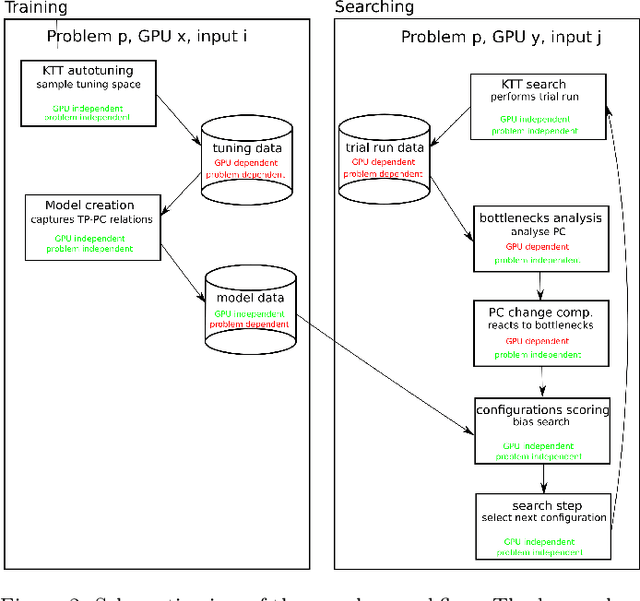
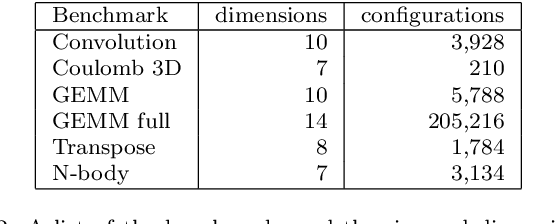
Nowadays, GPU accelerators are commonly used to speed up general-purpose computing tasks on a variety of hardware. However, due to the diversity of GPU architectures and processed data, optimization of codes for a particular type of hardware and specific data characteristics can be extremely challenging. The autotuning of performance-relevant source-code parameters allows for automatic optimization of applications and keeps their performance portable. Although the autotuning process typically results in code speed-up, searching the tuning space can bring unacceptable overhead if (i) the tuning space is vast and full of poorly-performing implementations, or (ii) the autotuning process has to be repeated frequently because of changes in processed data or migration to different hardware. In this paper, we introduce a novel method for searching tuning spaces. The method takes advantage of collecting hardware performance counters (also known as profiling counters) during empirical tuning. Those counters are used to navigate the searching process towards faster implementations. The method requires the tuning space to be sampled on any GPU. It builds a problem-specific model, which can be used during autotuning on various, even previously unseen inputs or GPUs. Using a set of five benchmarks, we experimentally demonstrate that our method can speed up autotuning when an application needs to be ported to different hardware or when it needs to process data with different characteristics. We also compared our method to state of the art and show that our method is superior in terms of the number of searching steps and typically outperforms other searches in terms of convergence time.