 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecting Agentic Communities using Design Patterns
Jan 07, 2026The rapid evolution of Large Language Models (LLM) and subsequent Agentic AI technologies requires systematic architectural guidance for building sophisticated, production-grade systems. This paper presents an approach for architecting such systems using design patterns derived from enterprise distributed systems standards, formal methods, and industry practice. We classify these patterns into three tiers: LLM Agents (task-specific automation), Agentic AI (adaptive goal-seekers), and Agentic Communities (organizational frameworks where AI agents and human participants coordinate through formal roles, protocols, and governance structures). We focus on Agentic Communities - coordination frameworks encompassing LLM Agents, Agentic AI entities, and humans - most relevant for enterprise and industrial applications. Drawing on established coordination principles from distributed systems, we ground these patterns in a formal framework that specifies collaboration agreements where AI agents and humans fill roles within governed ecosystems. This approach provides both practical guidance and formal verification capabilities, enabling expression of organizational, legal, and ethical rules through accountability mechanisms that ensure operational and verifiable governance of inter-agent communication, negotiation, and intent modeling. We validate this framework through a clinical trial matching case study. Our goal is to provide actionable guidance to practitioners while maintaining the formal rigor essential for enterprise deployment in dynamic, multi-agent ecosystems.
New Money: A Systematic Review of Synthetic Data Generation for Finance
Oct 30, 2025



Synthetic data generation has emerged as a promising approach to address the challenges of using sensitive financial data in machine learning applications. By leveraging generative models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), it is possible to create artificial datasets that preserve the statistical properties of real financial records while mitigating privacy risks and regulatory constraints. Despite the rapid growth of this field, a comprehensive synthesis of the current research landscape has been lacking. This systematic review consolidates and analyses 72 studies published since 2018 that focus on synthetic financial data generation. We categorise the types of financial information synthesised, the generative methods employed, and the evaluation strategies used to assess data utility and privacy. The findings indicate that GAN-based approaches dominate the literature, particularly for generating time-series market data and tabular credit data. While several innovative techniques demonstrate potential for improved realism and privacy preservation, there remains a notable lack of rigorous evaluation of privacy safeguards across studies. By providing an integrated overview of generative techniques, applications, and evaluation methods, this review highlights critical research gaps and offers guidance for future work aimed at developing robust, privacy-preserving synthetic data solutions for the financial domain.
A Collaborative Data Analytics System with Recommender for Diverse Users
Jun 17, 2024This paper presents the SLEGO (Software-Lego) system, a collaborative analytics platform that bridges the gap between experienced developers and novice users using a cloud-based platform with modular, reusable microservices. These microservices enable developers to share their analytical tools and workflows, while a simple graphical user interface (GUI) allows novice users to build comprehensive analytics pipelines without programming skills. Supported by a knowledge base and a Large Language Model (LLM) powered recommendation system, SLEGO enhances the selection and integration of microservices, increasing the efficiency of analytics pipeline construction. Case studies in finance and machine learning illustrate how SLEGO promotes the sharing and assembly of modular microservices, significantly improving resource reusability and team collaboration. The results highlight SLEGO's role in democratizing data analytics by integrating modular design, knowledge bases, and recommendation systems, fostering a more inclusive and efficient analytical environment.
Credit risk prediction in an imbalanced social lending environment
Apr 28, 2018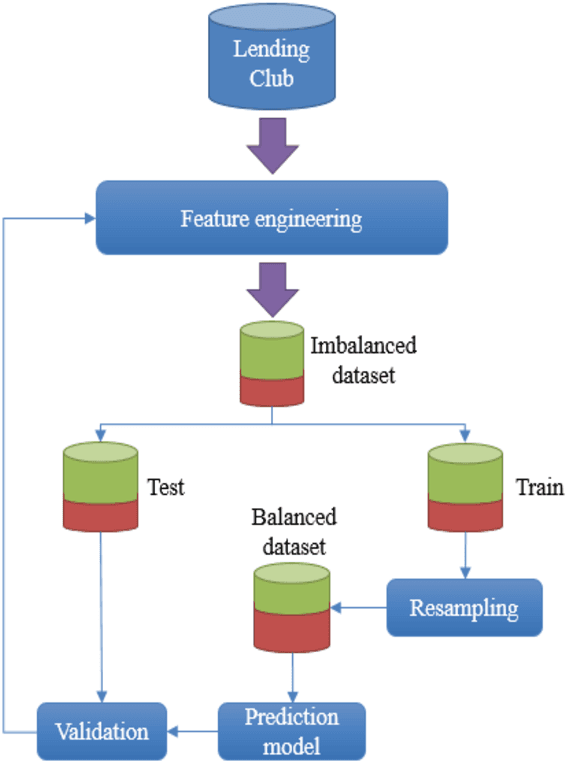
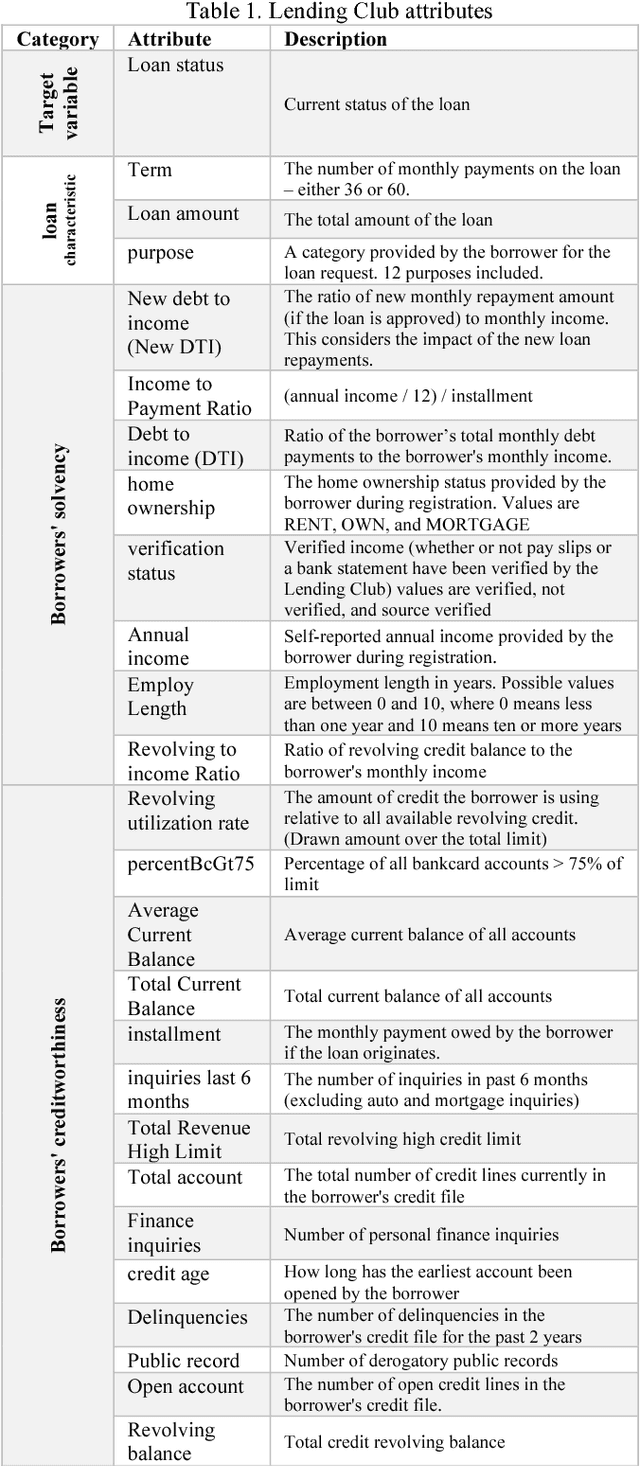
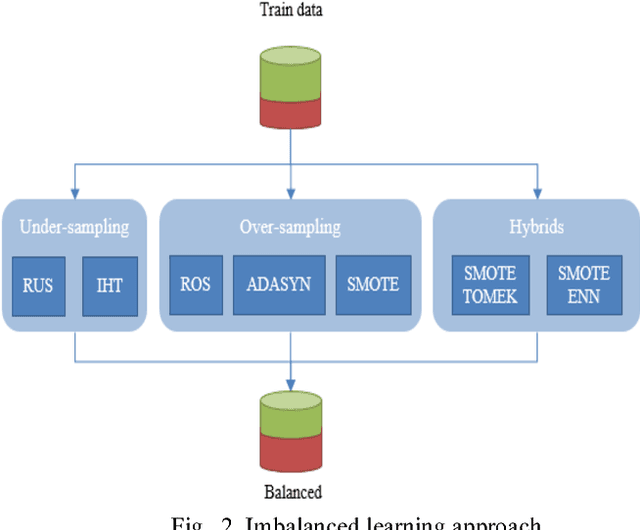
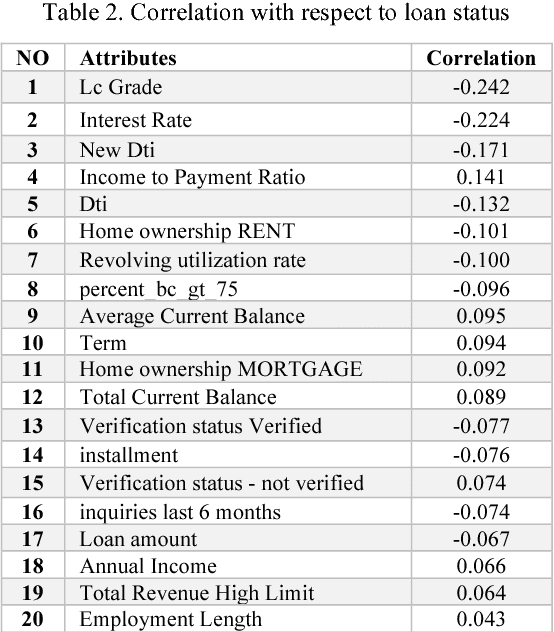
Credit risk prediction is an effective way of evaluating whether a potential borrower will repay a loan, particularly in peer-to-peer lending where class imbalance problems are prevalent. However, few credit risk prediction models for social lending consider imbalanced data and, further, the best resampling technique to use with imbalanced data is still controversial. In an attempt to address these problems, this paper presents an empirical comparison of various combinations of classifiers and resampling techniques within a novel risk assessment methodology that incorporates imbalanced data. The credit predictions from each combination are evaluated with a G-mean measure to avoid bias towards the majority class, which has not been considered in similar studies. The results reveal that combining random forest and random under-sampling may be an effective strategy for calculating the credit risk associated with loan applicants in social lending markets.
Enhancing Automated Decision Support across Medical and Oral Health Domains with Semantic Web Technologies
Mar 30, 2014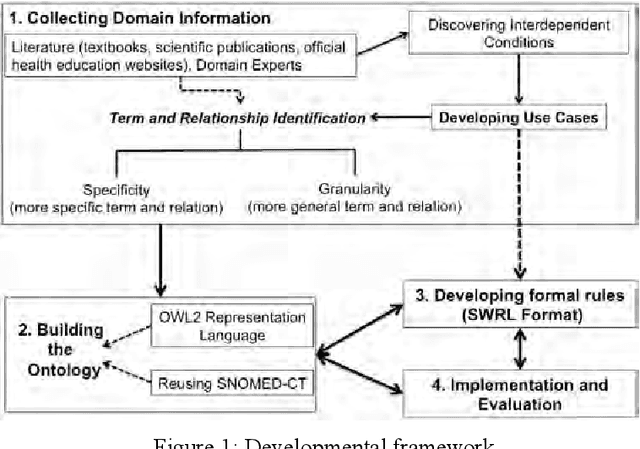
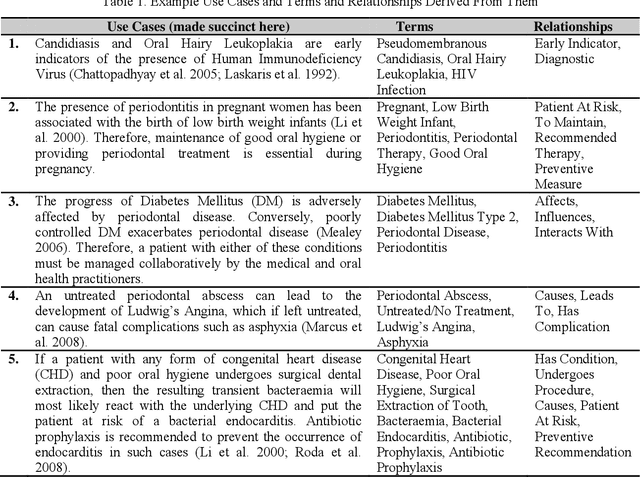
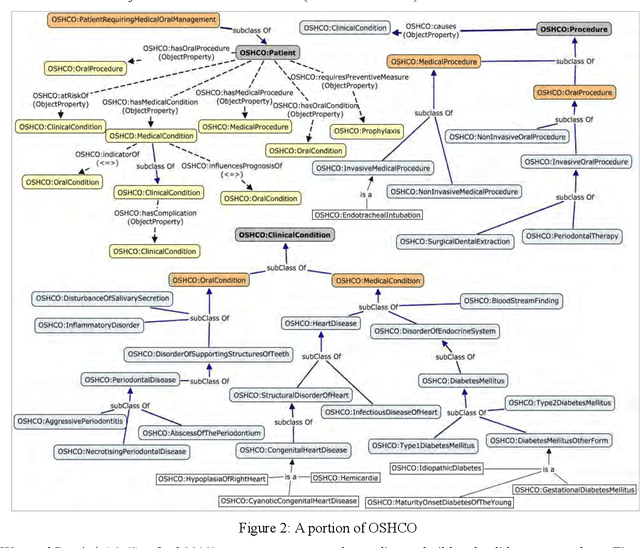

Research has shown that the general health and oral health of an individual are closely related. Accordingly, current practice of isolating the information base of medical and oral health domains can be dangerous and detrimental to the health of the individual. However, technical issues such as heterogeneous data collection and storage formats, limited sharing of patient information and lack of decision support over the shared information are the principal reasons for the current state of affairs. To address these issues, the following research investigates the development and application of a cross-domain ontology and rules to build an evidence-based and reusable knowledge base consisting of the inter-dependent conditions from the two domains. Through example implementation of the knowledge base in Protege, we demonstrate the effectiveness of our approach in reasoning over and providing decision support for cross-domain patient information.