 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Multi-Party Computation Based Privacy Preserving Extreme Learning Machine Algorithm Over Vertically Distributed Data
Feb 09, 2016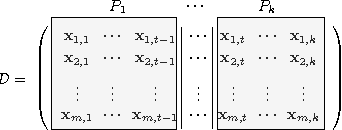
Especially in the Big Data era, the usage of different classification methods is increasing day by day. The success of these classification methods depends on the effectiveness of learning methods. Extreme learning machine (ELM) classification algorithm is a relatively new learning method built on feed-forward neural-network. ELM classification algorithm is a simple and fast method that can create a model from high-dimensional data sets. Traditional ELM learning algorithm implicitly assumes complete access to whole data set. This is a major privacy concern in most of cases. Sharing of private data (i.e. medical records) is prevented because of security concerns. In this research, we propose an efficient and secure privacy-preserving learning algorithm for ELM classification over data that is vertically partitioned among several parties. The new learning method preserves the privacy on numerical attributes, builds a classification model without sharing private data without disclosing the data of each party to others.
Robust Ensemble Classifier Combination Based on Noise Removal with One-Class SVM
Feb 09, 2016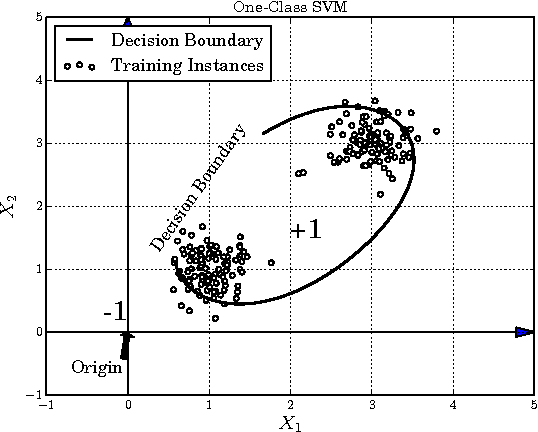
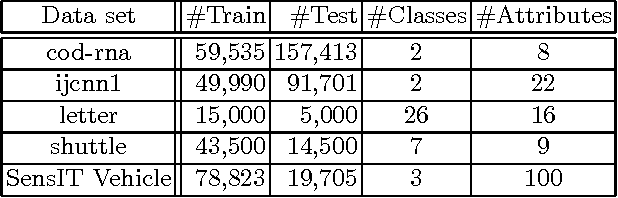
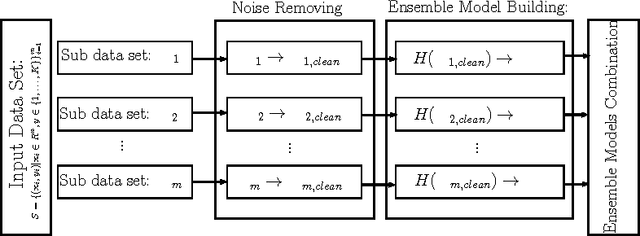
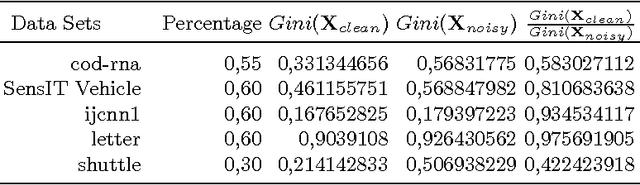
In machine learning area, as the number of labeled input samples becomes very large, it is very difficult to build a classification model because of input data set is not fit in a memory in training phase of the algorithm, therefore, it is necessary to utilize data partitioning to handle overall data set. Bagging and boosting based data partitioning methods have been broadly used in data mining and pattern recognition area. Both of these methods have shown a great possibility for improving classification model performance. This study is concerned with the analysis of data set partitioning with noise removal and its impact on the performance of multiple classifier models. In this study, we propose noise filtering preprocessing at each data set partition to increment classifier model performance. We applied Gini impurity approach to find the best split percentage of noise filter ratio. The filtered sub data set is then used to train individual ensemble models.
Classification with Boosting of Extreme Learning Machine Over Arbitrarily Partitioned Data
Feb 09, 2016
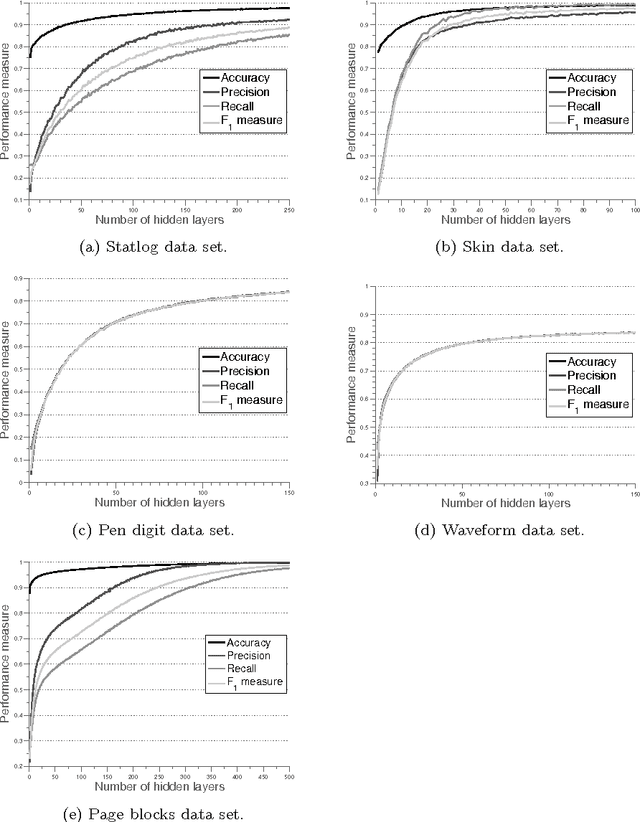
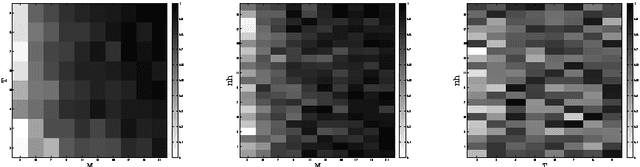
Machine learning based computational intelligence methods are widely used to analyze large scale data sets in this age of big data. Extracting useful predictive modeling from these types of data sets is a challenging problem due to their high complexity. Analyzing large amount of streaming data that can be leveraged to derive business value is another complex problem to solve. With high levels of data availability (\textit{i.e. Big Data}) automatic classification of them has become an important and complex task. Hence, we explore the power of applying MapReduce based Distributed AdaBoosting of Extreme Learning Machine (ELM) to build a predictive bag of classification models. Accordingly, (i) data set ensembles are created; (ii) ELM algorithm is used to build weak learners (classifier functions); and (iii) builds a strong learner from a set of weak learners. We applied this training model to the benchmark knowledge discovery and data mining data sets.
Classification with Extreme Learning Machine and Ensemble Algorithms Over Randomly Partitioned Data
Apr 12, 2015In this age of Big Data, machine learning based data mining methods are extensively used to inspect large scale data sets. Deriving applicable predictive modeling from these type of data sets is a challenging obstacle because of their high complexity. Opportunity with high data availability levels, automated classification of data sets has become a critical and complicated function. In this paper, the power of applying MapReduce based Distributed AdaBoosting of Extreme Learning Machine (ELM) are explored to build reliable predictive bag of classification models. Thus, (i) dataset ensembles are build; (ii) ELM algorithm is used to build weak classification models; and (iii) build a strong classification model from a set of weak classification models. This training model is applied to the publicly available knowledge discovery and data mining datasets.
Polarization Measurement of High Dimensional Social Media Messages With Support Vector Machine Algorithm Using Mapreduce
Mar 11, 2015In this article, we propose a new Support Vector Machine (SVM) training algorithm based on distributed MapReduce technique. In literature, there are a lots of research that shows us SVM has highest generalization property among classification algorithms used in machine learning area. Also, SVM classifier model is not affected by correlations of the features. But SVM uses quadratic optimization techniques in its training phase. The SVM algorithm is formulated as quadratic optimization problem. Quadratic optimization problem has $O(m^3)$ time and $O(m^2)$ space complexity, where m is the training set size. The computation time of SVM training is quadratic in the number of training instances. In this reason, SVM is not a suitable classification algorithm for large scale dataset classification. To solve this training problem we developed a new distributed MapReduce method developed. Accordingly, (i) SVM algorithm is trained in distributed dataset individually; (ii) then merge all support vectors of classifier model in every trained node; and (iii) iterate these two steps until the classifier model converges to the optimal classifier function. In the implementation phase, large scale social media dataset is presented in TFxIDF matrix. The matrix is used for sentiment analysis to get polarization value. Two and three class models are created for classification method. Confusion matrices of each classification model are presented in tables. Social media messages corpus consists of 108 public and 66 private universities messages in Turkey. Twitter is used for source of corpus. Twitter user messages are collected using Twitter Streaming API. Results are shown in graphics and tables.
A MapReduce based distributed SVM algorithm for binary classification
Dec 15, 2013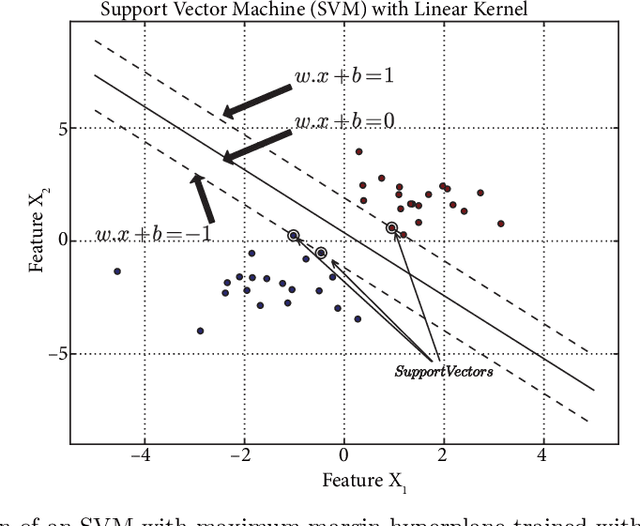

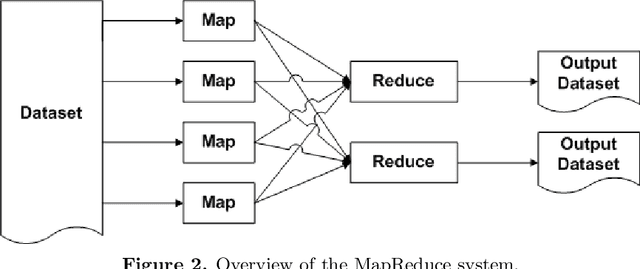
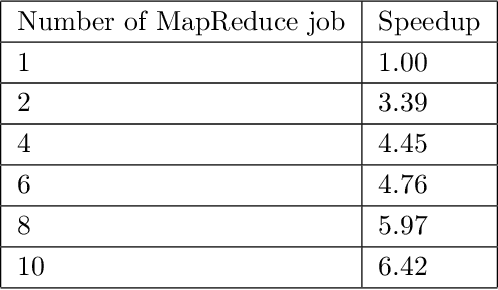
Although Support Vector Machine (SVM) algorithm has a high generalization property to classify for unseen examples after training phase and it has small loss value, the algorithm is not suitable for real-life classification and regression problems. SVMs cannot solve hundreds of thousands examples in training dataset. In previous studies on distributed machine learning algorithms, SVM is trained over a costly and preconfigured computer environment. In this research, we present a MapReduce based distributed parallel SVM training algorithm for binary classification problems. This work shows how to distribute optimization problem over cloud computing systems with MapReduce technique. In the second step of this work, we used statistical learning theory to find the predictive hypothesis that minimize our empirical risks from hypothesis spaces that created with reduce function of MapReduce. The results of this research are important for training of big datasets for SVM algorithm based classification problems. We provided that iterative training of split dataset with MapReduce technique; accuracy of the classifier function will converge to global optimal classifier function's accuracy in finite iteration size. The algorithm performance was measured on samples from letter recognition and pen-based recognition of handwritten digits dataset.