 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning, Inference and Pragmatics in Sequential Language Games
May 30, 2018We study sequential language games in which two players, each with private information, communicate to achieve a common goal. In such games, a successful player must (i) infer the partner's private information from the partner's messages, (ii) generate messages that are most likely to help with the goal, and (iii) reason pragmatically about the partner's strategy. We propose a model that captures all three characteristics and demonstrate their importance in capturing human behavior on a new goal-oriented dataset we collected using crowdsourcing.
Unanimous Prediction for 100% Precision with Application to Learning Semantic Mappings
Jun 23, 2016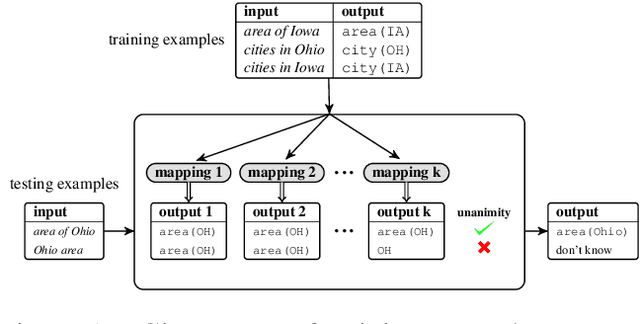

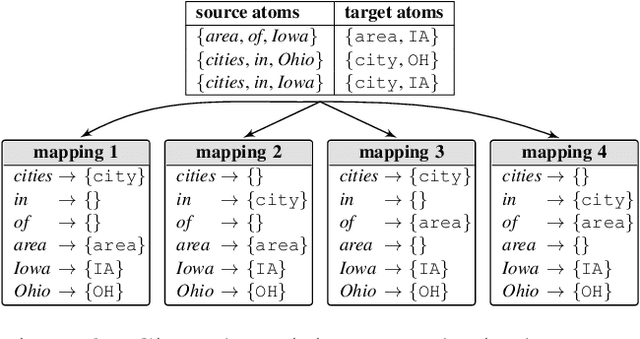
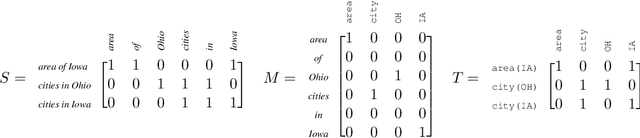
Can we train a system that, on any new input, either says "don't know" or makes a prediction that is guaranteed to be correct? We answer the question in the affirmative provided our model family is well-specified. Specifically, we introduce the unanimity principle: only predict when all models consistent with the training data predict the same output. We operationalize this principle for semantic parsing, the task of mapping utterances to logical forms. We develop a simple, efficient method that reasons over the infinite set of all consistent models by only checking two of the models. We prove that our method obtains 100% precision even with a modest amount of training data from a possibly adversarial distribution. Empirically, we demonstrate the effectiveness of our approach on the standard GeoQuery dataset.