 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Fusion: Return of the Language Model
Sep 01, 2018
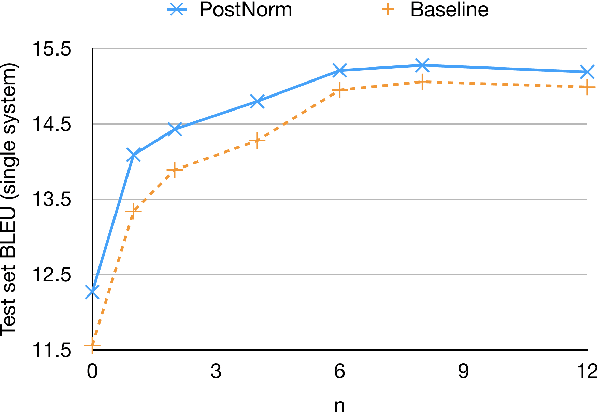
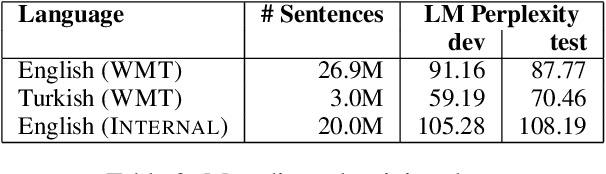
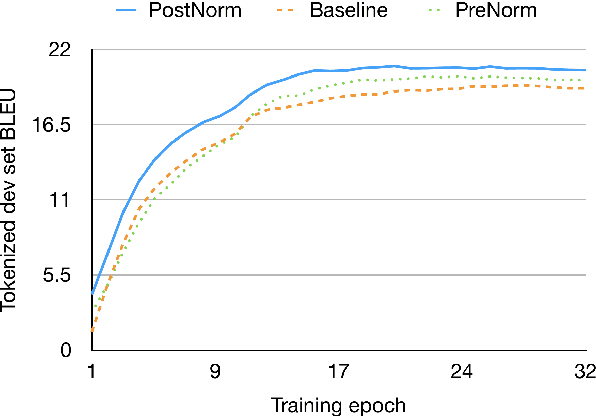
Neural Machine Translation (NMT) typically leverages monolingual data in training through backtranslation. We investigate an alternative simple method to use monolingual data for NMT training: We combine the scores of a pre-trained and fixed language model (LM) with the scores of a translation model (TM) while the TM is trained from scratch. To achieve that, we train the translation model to predict the residual probability of the training data added to the prediction of the LM. This enables the TM to focus its capacity on modeling the source sentence since it can rely on the LM for fluency. We show that our method outperforms previous approaches to integrate LMs into NMT while the architecture is simpler as it does not require gating networks to balance TM and LM. We observe gains of between +0.24 and +2.36 BLEU on all four test sets (English-Turkish, Turkish-English, Estonian-English, Xhosa-English) on top of ensembles without LM. We compare our method with alternative ways to utilize monolingual data such as backtranslation, shallow fusion, and cold fusion.
An Operation Sequence Model for Explainable Neural Machine Translation
Aug 29, 2018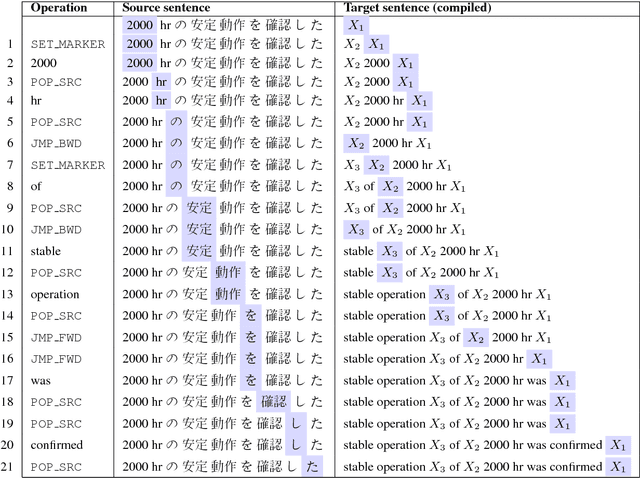
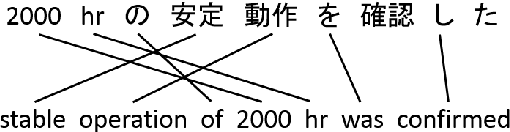
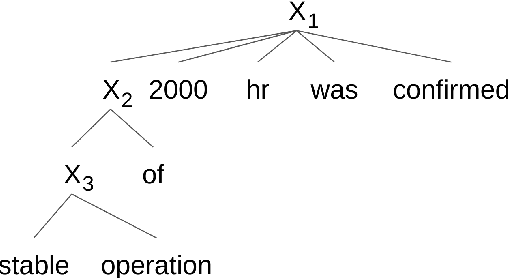

We propose to achieve explainable neural machine translation (NMT) by changing the output representation to explain itself. We present a novel approach to NMT which generates the target sentence by monotonically walking through the source sentence. Word reordering is modeled by operations which allow setting markers in the target sentence and move a target-side write head between those markers. In contrast to many modern neural models, our system emits explicit word alignment information which is often crucial to practical machine translation as it improves explainability. Our technique can outperform a plain text system in terms of BLEU score under the recent Transformer architecture on Japanese-English and Portuguese-English, and is within 0.5 BLEU difference on Spanish-English.
The University of Cambridge's Machine Translation Systems for WMT18
Aug 28, 2018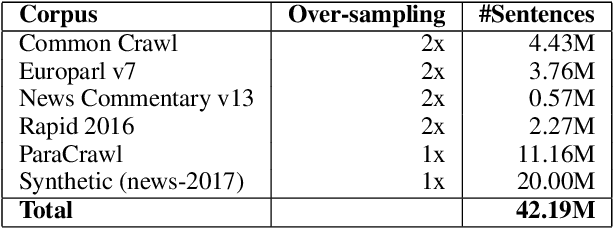
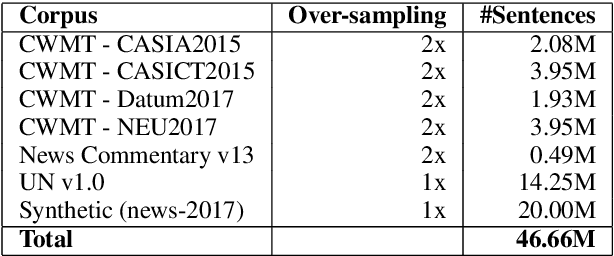

The University of Cambridge submission to the WMT18 news translation task focuses on the combination of diverse models of translation. We compare recurrent, convolutional, and self-attention-based neural models on German-English, English-German, and Chinese-English. Our final system combines all neural models together with a phrase-based SMT system in an MBR-based scheme. We report small but consistent gains on top of strong Transformer ensembles.
Multi-representation Ensembles and Delayed SGD Updates Improve Syntax-based NMT
May 11, 2018
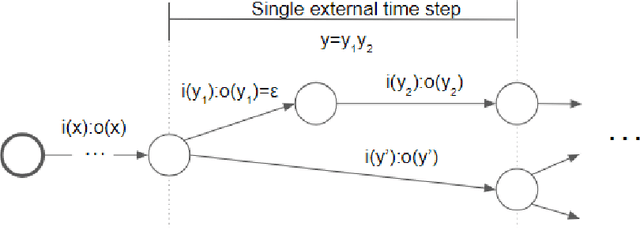

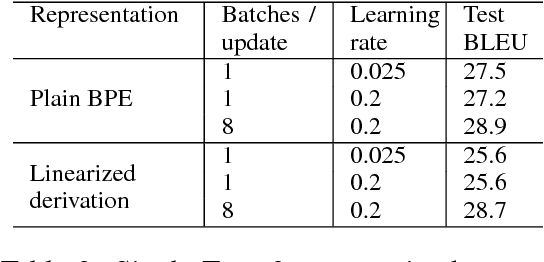
We explore strategies for incorporating target syntax into Neural Machine Translation. We specifically focus on syntax in ensembles containing multiple sentence representations. We formulate beam search over such ensembles using WFSTs, and describe a delayed SGD update training procedure that is especially effective for long representations like linearized syntax. Our approach gives state-of-the-art performance on a difficult Japanese-English task.
Why not be Versatile? Applications of the SGNMT Decoder for Machine Translation
Mar 20, 2018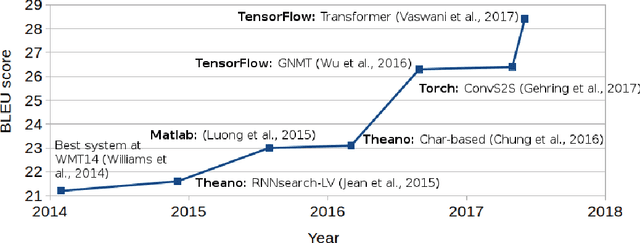
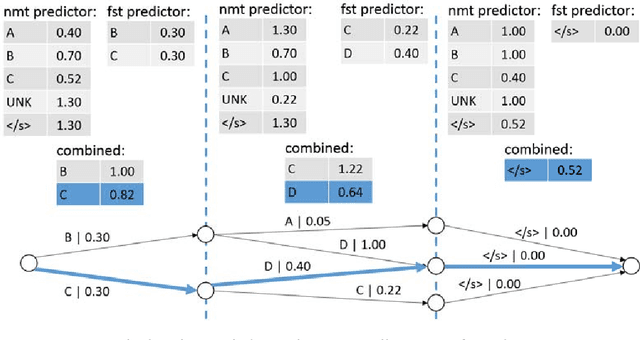

SGNMT is a decoding platform for machine translation which allows paring various modern neural models of translation with different kinds of constraints and symbolic models. In this paper, we describe three use cases in which SGNMT is currently playing an active role: (1) teaching as SGNMT is being used for course work and student theses in the MPhil in Machine Learning, Speech and Language Technology at the University of Cambridge, (2) research as most of the research work of the Cambridge MT group is based on SGNMT, and (3) technology transfer as we show how SGNMT is helping to transfer research findings from the laboratory to the industry, eg. into a product of SDL plc.
A Comparison of Neural Models for Word Ordering
Aug 05, 2017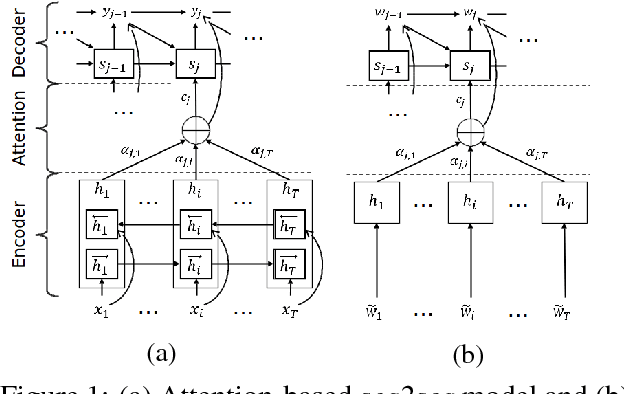


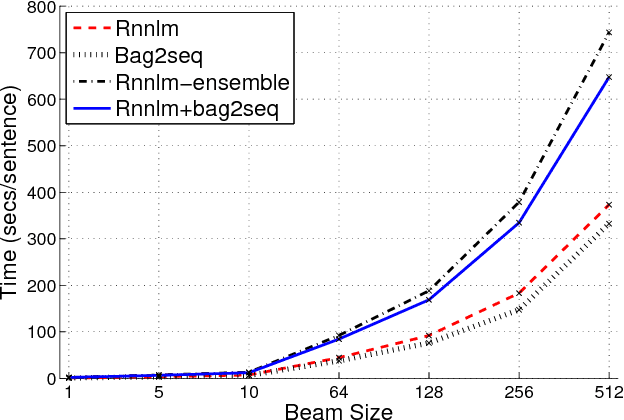
We compare several language models for the word-ordering task and propose a new bag-to-sequence neural model based on attention-based sequence-to-sequence models. We evaluate the model on a large German WMT data set where it significantly outperforms existing models. We also describe a novel search strategy for LM-based word ordering and report results on the English Penn Treebank. Our best model setup outperforms prior work both in terms of speed and quality.
SGNMT -- A Flexible NMT Decoding Platform for Quick Prototyping of New Models and Search Strategies
Jul 21, 2017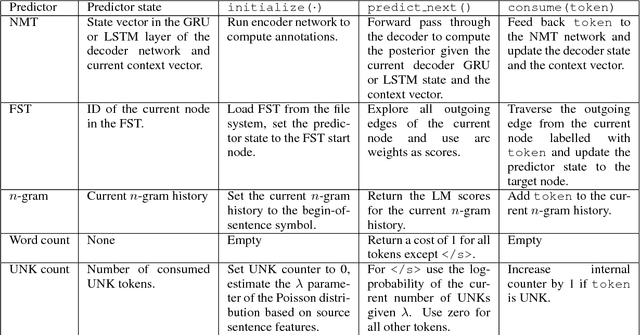

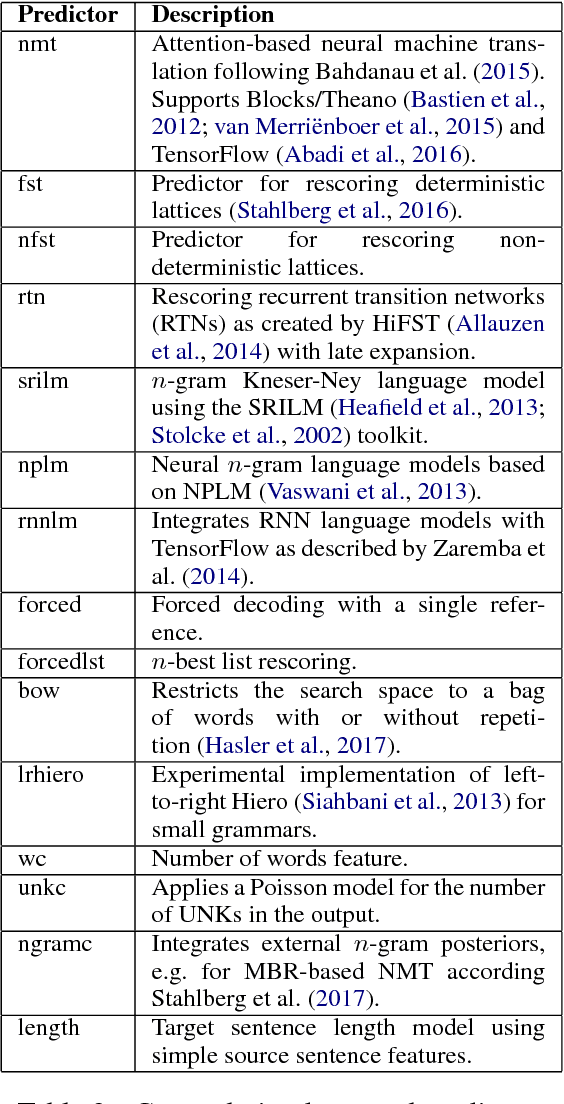
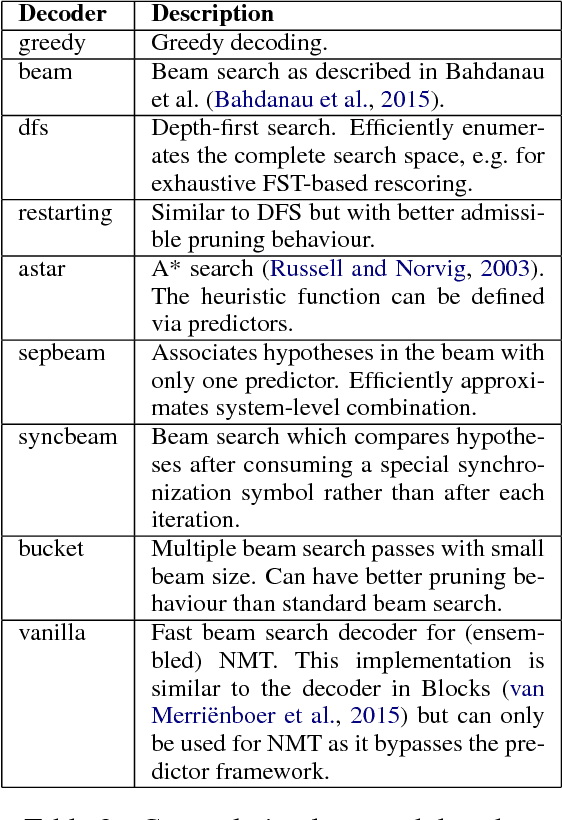
This paper introduces SGNMT, our experimental platform for machine translation research. SGNMT provides a generic interface to neural and symbolic scoring modules (predictors) with left-to-right semantic such as translation models like NMT, language models, translation lattices, $n$-best lists or other kinds of scores and constraints. Predictors can be combined with other predictors to form complex decoding tasks. SGNMT implements a number of search strategies for traversing the space spanned by the predictors which are appropriate for different predictor constellations. Adding new predictors or decoding strategies is particularly easy, making it a very efficient tool for prototyping new research ideas. SGNMT is actively being used by students in the MPhil program in Machine Learning, Speech and Language Technology at the University of Cambridge for course work and theses, as well as for most of the research work in our group.
Unfolding and Shrinking Neural Machine Translation Ensembles
Jul 21, 2017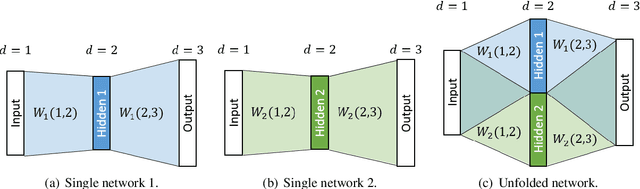
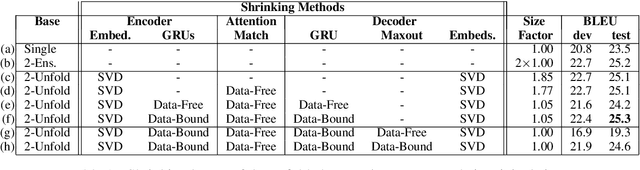
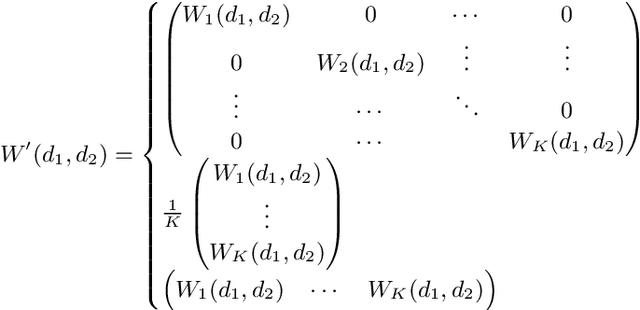
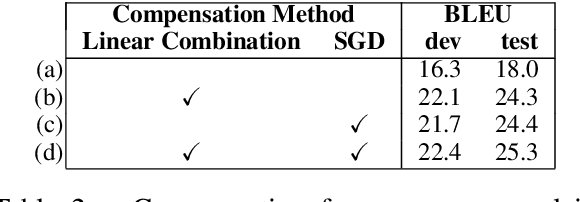
Ensembling is a well-known technique in neural machine translation (NMT) to improve system performance. Instead of a single neural net, multiple neural nets with the same topology are trained separately, and the decoder generates predictions by averaging over the individual models. Ensembling often improves the quality of the generated translations drastically. However, it is not suitable for production systems because it is cumbersome and slow. This work aims to reduce the runtime to be on par with a single system without compromising the translation quality. First, we show that the ensemble can be unfolded into a single large neural network which imitates the output of the ensemble system. We show that unfolding can already improve the runtime in practice since more work can be done on the GPU. We proceed by describing a set of techniques to shrink the unfolded network by reducing the dimensionality of layers. On Japanese-English we report that the resulting network has the size and decoding speed of a single NMT network but performs on the level of a 3-ensemble system.
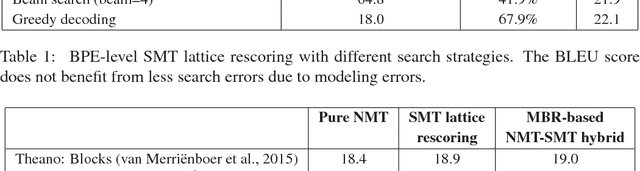
Neural Machine Translation by Minimising the Bayes-risk with Respect to Syntactic Translation Lattices
Feb 13, 2017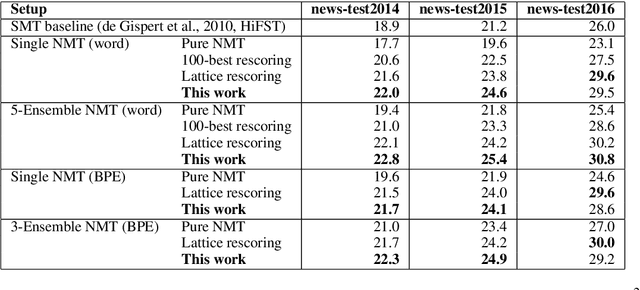
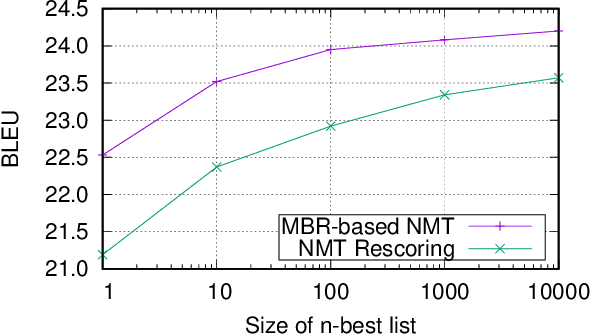
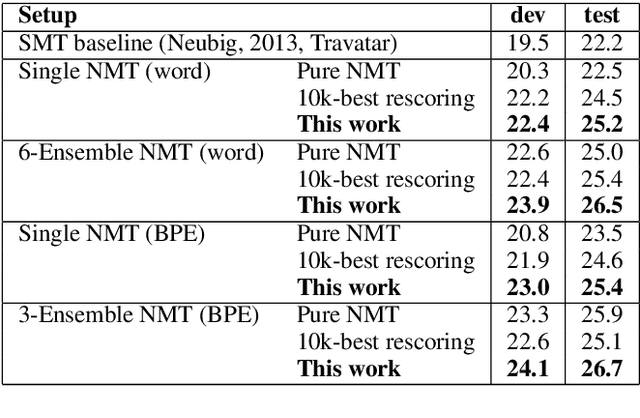
We present a novel scheme to combine neural machine translation (NMT) with traditional statistical machine translation (SMT). Our approach borrows ideas from linearised lattice minimum Bayes-risk decoding for SMT. The NMT score is combined with the Bayes-risk of the translation according the SMT lattice. This makes our approach much more flexible than $n$-best list or lattice rescoring as the neural decoder is not restricted to the SMT search space. We show an efficient and simple way to integrate risk estimation into the NMT decoder which is suitable for word-level as well as subword-unit-level NMT. We test our method on English-German and Japanese-English and report significant gains over lattice rescoring on several data sets for both single and ensembled NMT. The MBR decoder produces entirely new hypotheses far beyond simply rescoring the SMT search space or fixing UNKs in the NMT output.
The Edit Distance Transducer in Action: The University of Cambridge English-German System at WMT16
Jun 15, 2016
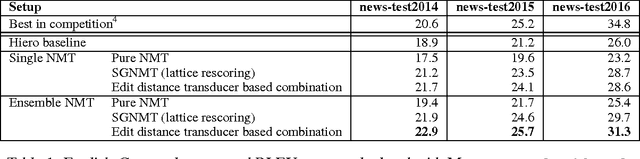
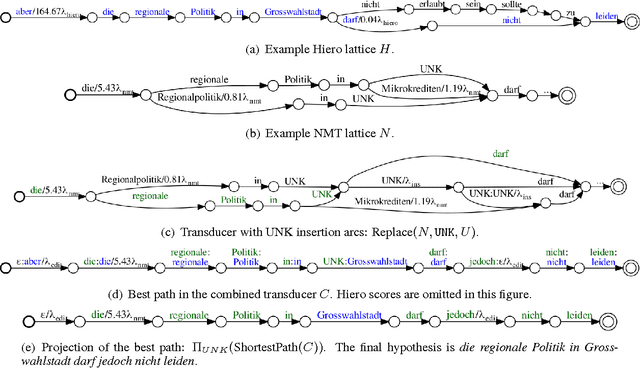

This paper presents the University of Cambridge submission to WMT16. Motivated by the complementary nature of syntactical machine translation and neural machine translation (NMT), we exploit the synergies of Hiero and NMT in different combination schemes. Starting out with a simple neural lattice rescoring approach, we show that the Hiero lattices are often too narrow for NMT ensembles. Therefore, instead of a hard restriction of the NMT search space to the lattice, we propose to loosely couple NMT and Hiero by composition with a modified version of the edit distance transducer. The loose combination outperforms lattice rescoring, especially when using multiple NMT systems in an ensemble.