 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Approach for Joint Video Frame and Reward Prediction in Atari Games
Aug 17, 2017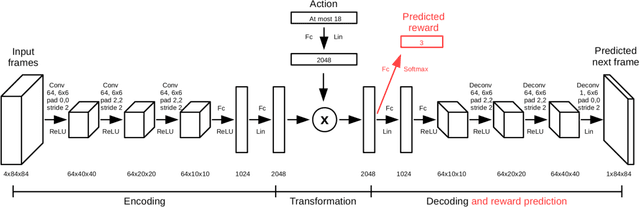
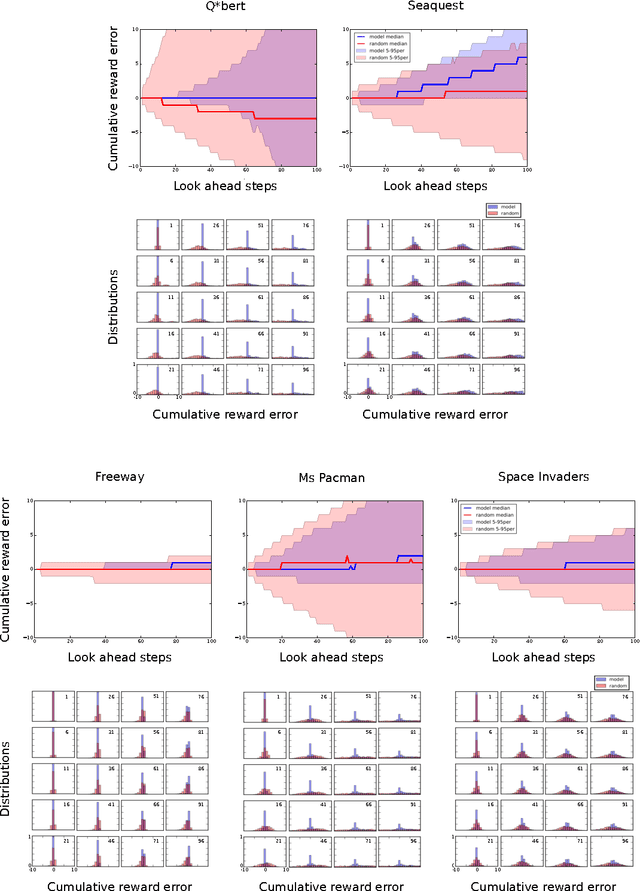

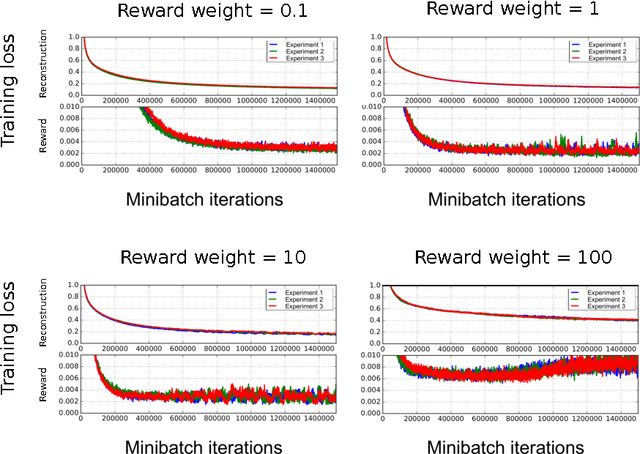
Reinforcement learning is concerned with identifying reward-maximizing behaviour policies in environments that are initially unknown. State-of-the-art reinforcement learning approaches, such as deep Q-networks, are model-free and learn to act effectively across a wide range of environments such as Atari games, but require huge amounts of data. Model-based techniques are more data-efficient, but need to acquire explicit knowledge about the environment. In this paper, we take a step towards using model-based techniques in environments with a high-dimensional visual state space by demonstrating that it is possible to learn system dynamics and the reward structure jointly. Our contribution is to extend a recently developed deep neural network for video frame prediction in Atari games to enable reward prediction as well. To this end, we phrase a joint optimization problem for minimizing both video frame and reward reconstruction loss, and adapt network parameters accordingly. Empirical evaluations on five Atari games demonstrate accurate cumulative reward prediction of up to 200 frames. We consider these results as opening up important directions for model-based reinforcement learning in complex, initially unknown environments.
Bounded Rational Decision-Making in Feedforward Neural Networks
May 23, 2016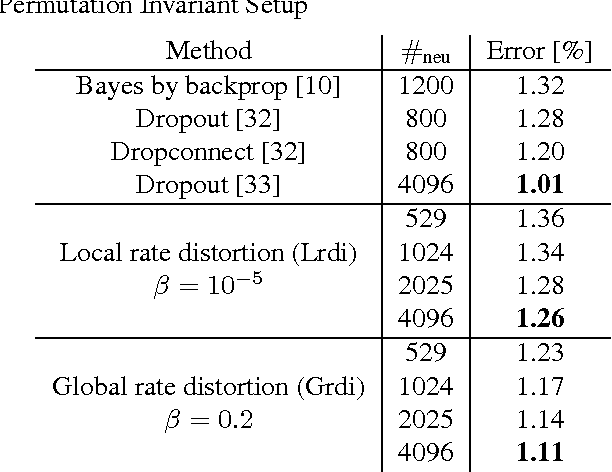
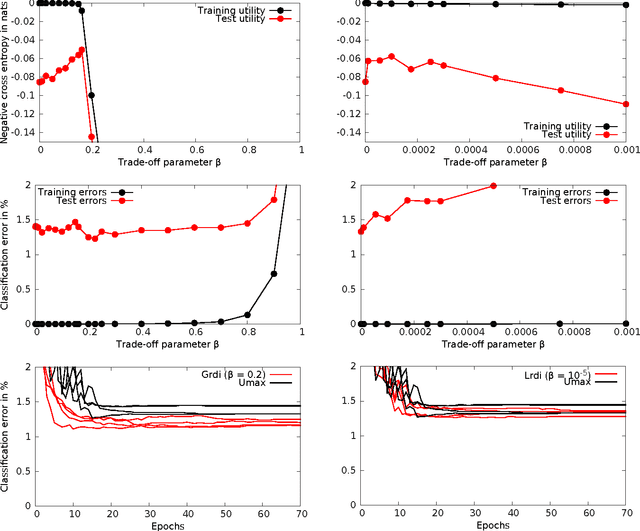

Bounded rational decision-makers transform sensory input into motor output under limited computational resources. Mathematically, such decision-makers can be modeled as information-theoretic channels with limited transmission rate. Here, we apply this formalism for the first time to multilayer feedforward neural networks. We derive synaptic weight update rules for two scenarios, where either each neuron is considered as a bounded rational decision-maker or the network as a whole. In the update rules, bounded rationality translates into information-theoretically motivated types of regularization in weight space. In experiments on the MNIST benchmark classification task for handwritten digits, we show that such information-theoretic regularization successfully prevents overfitting across different architectures and attains results that are competitive with other recent techniques like dropout, dropconnect and Bayes by backprop, for both ordinary and convolutional neural networks.
Planning with Information-Processing Constraints and Model Uncertainty in Markov Decision Processes
Apr 07, 2016
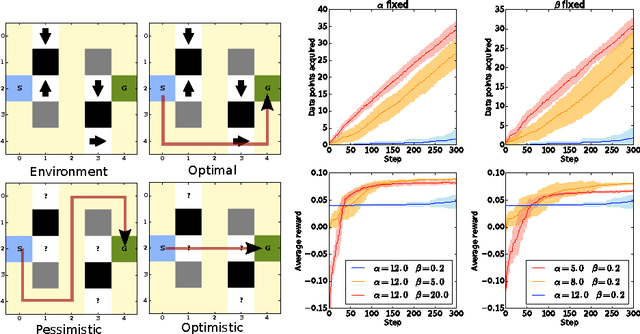
Information-theoretic principles for learning and acting have been proposed to solve particular classes of Markov Decision Problems. Mathematically, such approaches are governed by a variational free energy principle and allow solving MDP planning problems with information-processing constraints expressed in terms of a Kullback-Leibler divergence with respect to a reference distribution. Here we consider a generalization of such MDP planners by taking model uncertainty into account. As model uncertainty can also be formalized as an information-processing constraint, we can derive a unified solution from a single generalized variational principle. We provide a generalized value iteration scheme together with a convergence proof. As limit cases, this generalized scheme includes standard value iteration with a known model, Bayesian MDP planning, and robust planning. We demonstrate the benefits of this approach in a grid world simulation.