 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGigaChat Family: Efficient Russian Language Modeling Through Mixture of Experts Architecture
Jun 11, 2025



Generative large language models (LLMs) have become crucial for modern NLP research and applications across various languages. However, the development of foundational models specifically tailored to the Russian language has been limited, primarily due to the significant computational resources required. This paper introduces the GigaChat family of Russian LLMs, available in various sizes, including base models and instruction-tuned versions. We provide a detailed report on the model architecture, pre-training process, and experiments to guide design choices. In addition, we evaluate their performance on Russian and English benchmarks and compare GigaChat with multilingual analogs. The paper presents a system demonstration of the top-performing models accessible via an API, a Telegram bot, and a Web interface. Furthermore, we have released three open GigaChat models in open-source (https://huggingface.co/ai-sage), aiming to expand NLP research opportunities and support the development of industrial solutions for the Russian language.
Golos: Russian Dataset for Speech Research
Jun 18, 2021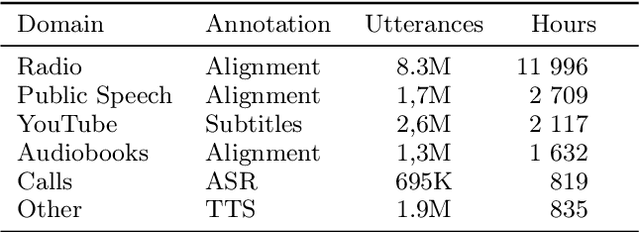
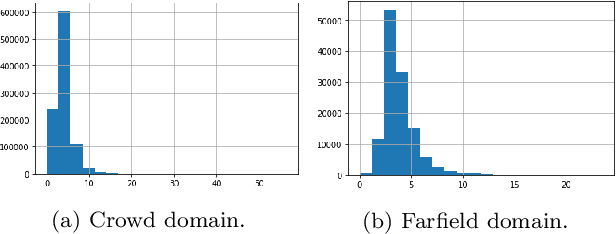

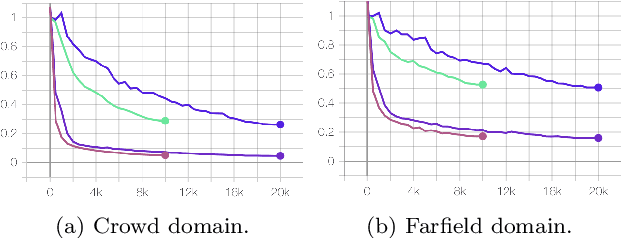
This paper introduces a novel Russian speech dataset called Golos, a large corpus suitable for speech research. The dataset mainly consists of recorded audio files manually annotated on the crowd-sourcing platform. The total duration of the audio is about 1240 hours. We have made the corpus freely available to download, along with the acoustic model with CTC loss prepared on this corpus. Additionally, transfer learning was applied to improve the performance of the acoustic model. In order to evaluate the quality of the dataset with the beam-search algorithm, we have built a 3-gram language model on the open Common Crawl dataset. The total word error rate (WER) metrics turned out to be about 3.3% and 11.5%.