 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-line approximate dynamic programming for the vehicle routing problem with stochastic customers and demands via decentralized decision-making
Sep 21, 2021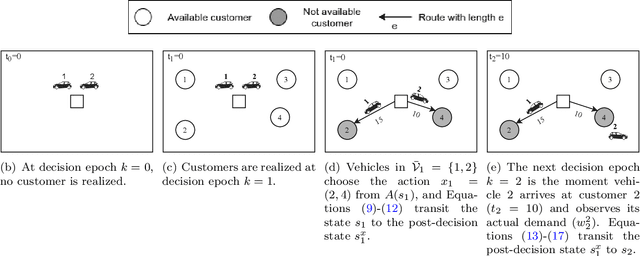
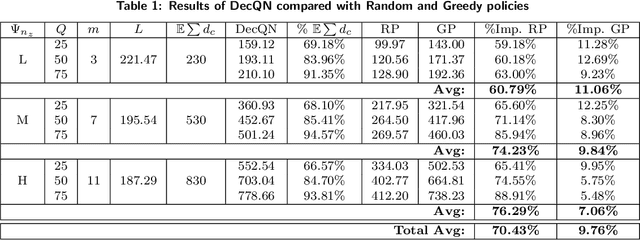
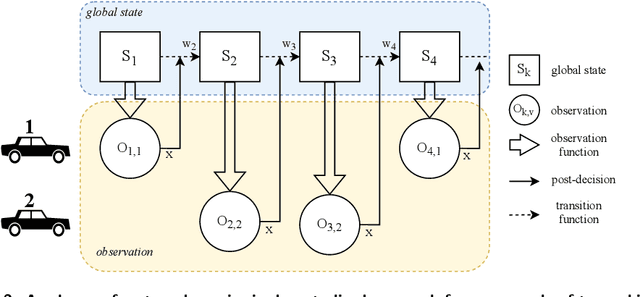

This paper studies a stochastic variant of the vehicle routing problem (VRP) where both customer locations and demands are uncertain. In particular, potential customers are not restricted to a predefined customer set but are continuously spatially distributed in a given service area. The objective is to maximize the served demands while fulfilling vehicle capacities and time restrictions. We call this problem the VRP with stochastic customers and demands (VRPSCD). For this problem, we first propose a Markov Decision Process (MDP) formulation representing the classical centralized decision-making perspective where one decision-maker establishes the routes of all vehicles. While the resulting formulation turns out to be intractable, it provides us with the ground to develop a new MDP formulation of the VRPSCD representing a decentralized decision-making framework, where vehicles autonomously establish their own routes. This new formulation allows us to develop several strategies to reduce the dimension of the state and action spaces, resulting in a considerably more tractable problem. We solve the decentralized problem via Reinforcement Learning, and in particular, we develop a Q-learning algorithm featuring state-of-the-art acceleration techniques such as Replay Memory and Double Q Network. Computational results show that our method considerably outperforms two commonly adopted benchmark policies (random and heuristic). Moreover, when comparing with existing literature, we show that our approach can compete with specialized methods developed for the particular case of the VRPSCD where customer locations and expected demands are known in advance. Finally, we show that the value functions and policies obtained by our algorithm can be easily embedded in Rollout algorithms, thus further improving their performances.
A computational study on imputation methods for missing environmental data
Aug 21, 2021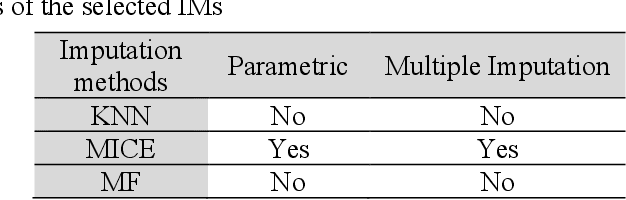

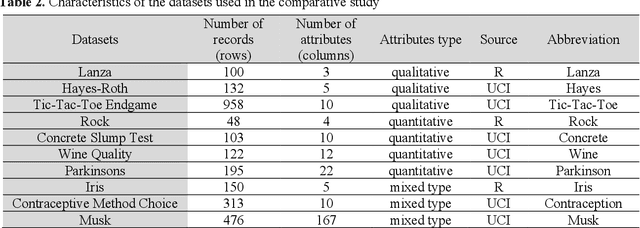
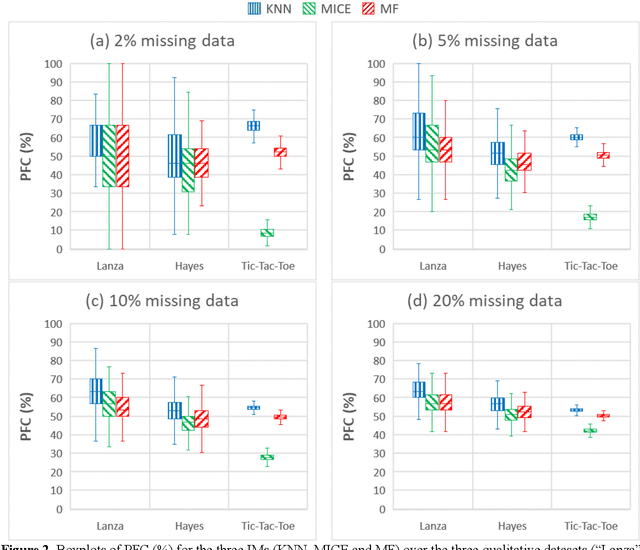
Data acquisition and recording in the form of databases are routine operations. The process of collecting data, however, may experience irregularities, resulting in databases with missing data. Missing entries might alter analysis efficiency and, consequently, the associated decision-making process. This paper focuses on databases collecting information related to the natural environment. Given the broad spectrum of recorded activities, these databases typically are of mixed nature. It is therefore relevant to evaluate the performance of missing data processing methods considering this characteristic. In this paper we investigate the performances of several missing data imputation methods and their application to the problem of missing data in environment. A computational study was performed to compare the method missForest (MF) with two other imputation methods, namely Multivariate Imputation by Chained Equations (MICE) and K-Nearest Neighbors (KNN). Tests were made on 10 pretreated datasets of various types. Results revealed that MF generally outperformed MICE and KNN in terms of imputation errors, with a more pronounced performance gap for mixed typed databases where MF reduced the imputation error up to 150%, when compared to the other methods. KNN was usually the fastest method. MF was then successfully applied to a case study on Quebec wastewater treatment plants performance monitoring. We believe that the present study demonstrates the pertinence of using MF as imputation method when dealing with missing environmental data.