 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeither Private Nor Fair: Impact of Data Imbalance on Utility and Fairness in Differential Privacy
Oct 03, 2020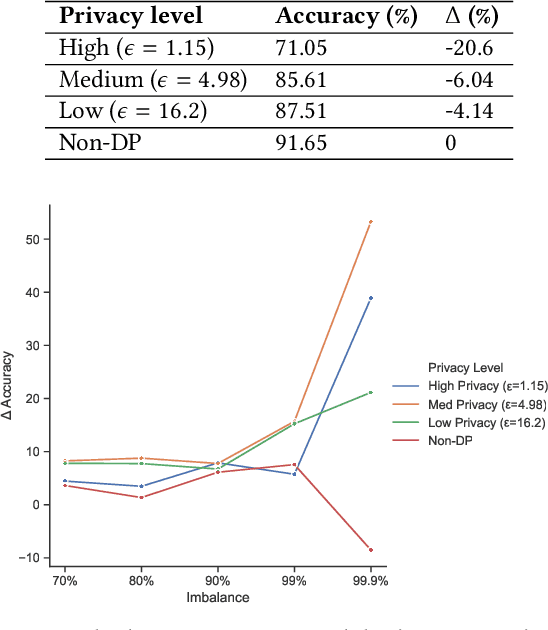
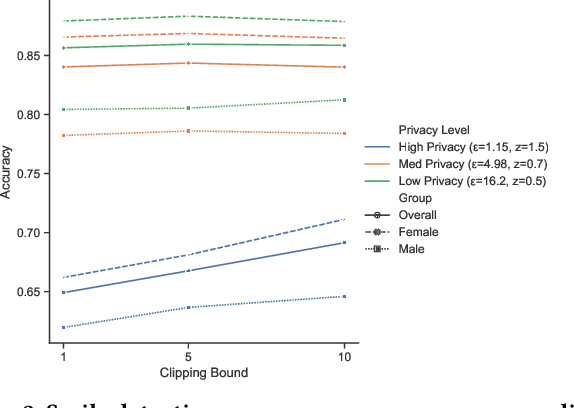
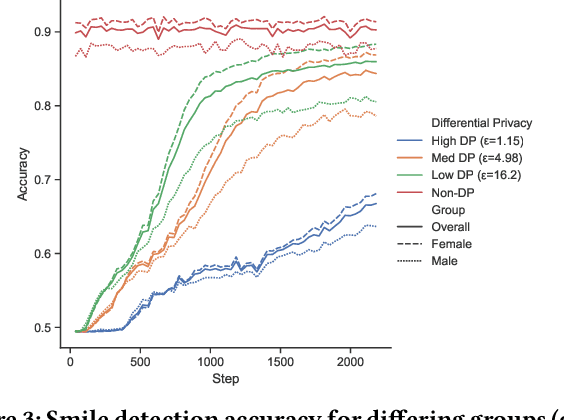
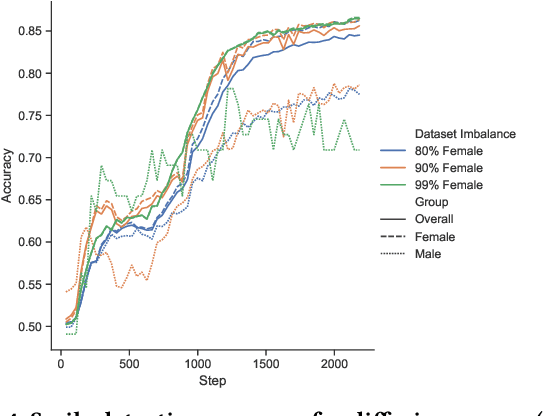
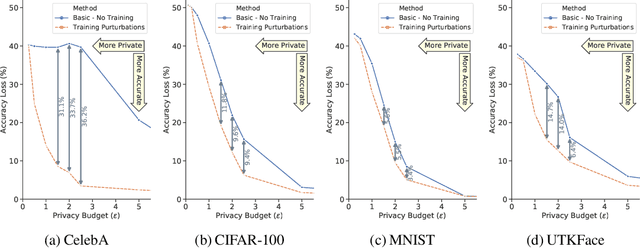
Deployment of deep learning in different fields and industries is growing day by day due to its performance, which relies on the availability of data and compute. Data is often crowd-sourced and contains sensitive information about its contributors, which leaks into models that are trained on it. To achieve rigorous privacy guarantees, differentially private training mechanisms are used. However, it has recently been shown that differential privacy can exacerbate existing biases in the data and have disparate impacts on the accuracy of different subgroups of data. In this paper, we aim to study these effects within differentially private deep learning. Specifically, we aim to study how different levels of imbalance in the data affect the accuracy and the fairness of the decisions made by the model, given different levels of privacy. We demonstrate that even small imbalances and loose privacy guarantees can cause disparate impacts.
Privacy in Deep Learning: A Survey
May 09, 2020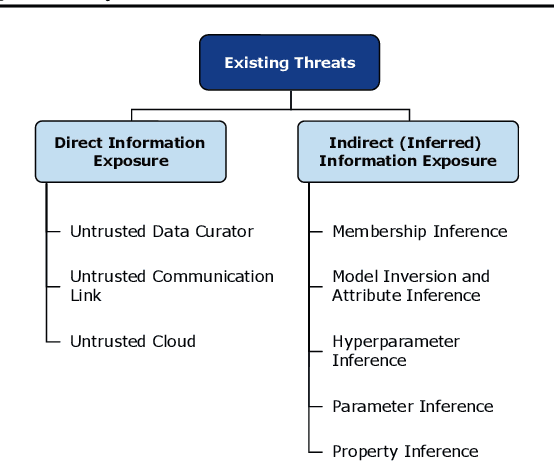


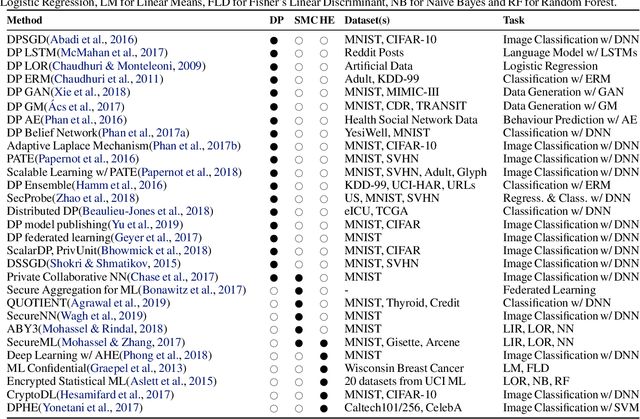
The ever-growing advances of deep learning in many areas including vision, recommendation systems, natural language processing, etc., have led to the adoption of Deep Neural Networks (DNNs) in production systems. The availability of large datasets and high computational power are the main contributors to these advances. The datasets are usually crowdsourced and may contain sensitive information. This poses serious privacy concerns as this data can be misused or leaked through various vulnerabilities. Even if the cloud provider and the communication link is trusted, there are still threats of inference attacks where an attacker could speculate properties of the data used for training, or find the underlying model architecture and parameters. In this survey, we review the privacy concerns brought by deep learning, and the mitigating techniques introduced to tackle these issues. We also show that there is a gap in the literature regarding test-time inference privacy, and propose possible future research directions.
A Principled Approach to Learning Stochastic Representations for Privacy in Deep Neural Inference
Mar 26, 2020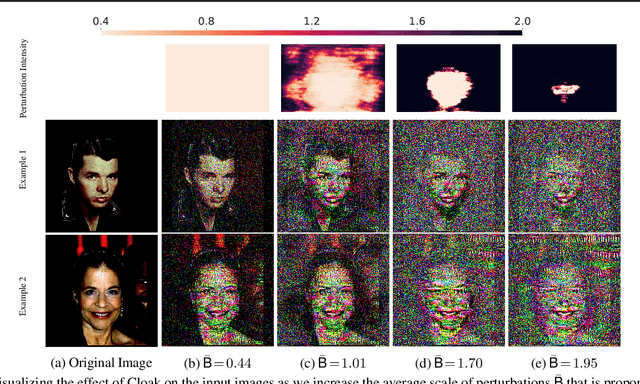
INFerence-as-a-Service (INFaaS) in the cloud has enabled the prevalent use of Deep Neural Networks (DNNs) in home automation, targeted advertising, machine vision, etc. The cloud receives the inference request as a raw input, containing a rich set of private information, that can be misused or leaked, possibly inadvertently. This prevalent setting can compromise the privacy of users during the inference phase. This paper sets out to provide a principled approach, dubbed Cloak, that finds optimal stochastic perturbations to obfuscate the private data before it is sent to the cloud. To this end, Cloak reduces the information content of the transmitted data while conserving the essential pieces that enable the request to be serviced accurately. The key idea is formulating the discovery of this stochasticity as an offline gradient-based optimization problem that reformulates a pre-trained DNN (with optimized known weights) as an analytical function of the stochastic perturbations. Using Laplace distribution as a parametric model for the stochastic perturbations, Cloak learns the optimal parameters using gradient descent and Monte Carlo sampling. This set of optimized Laplace distributions further guarantee that the injected stochasticity satisfies the -differential privacy criterion. Experimental evaluations with real-world datasets show that, on average, the injected stochasticity can reduce the information content in the input data by 80.07%, while incurring 7.12% accuracy loss.
Gradient-Based Deep Quantization of Neural Networks through Sinusoidal Adaptive Regularization
Feb 29, 2020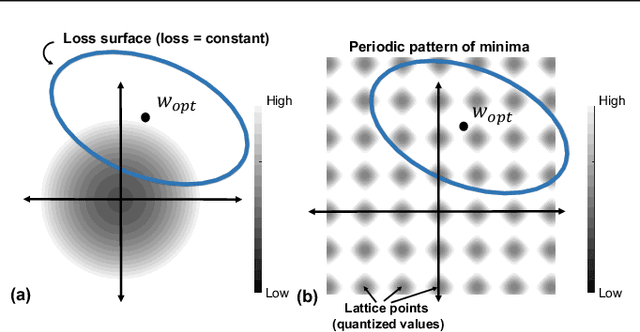
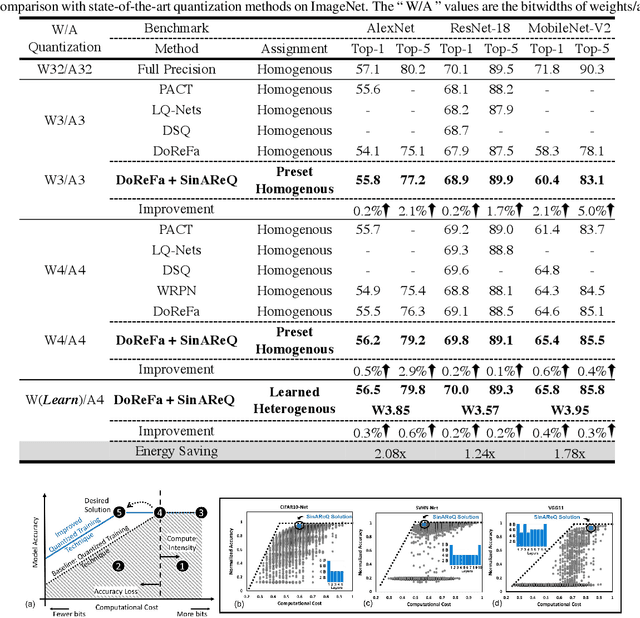
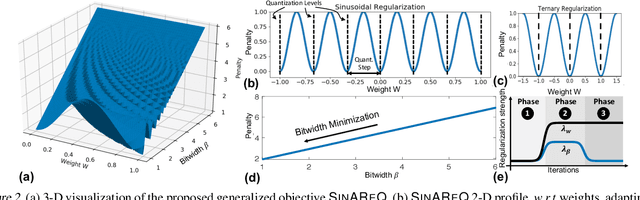
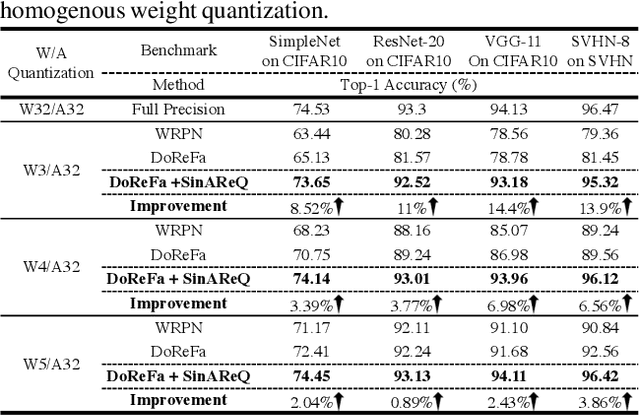
As deep neural networks make their ways into different domains, their compute efficiency is becoming a first-order constraint. Deep quantization, which reduces the bitwidth of the operations (below 8 bits), offers a unique opportunity as it can reduce both the storage and compute requirements of the network super-linearly. However, if not employed with diligence, this can lead to significant accuracy loss. Due to the strong inter-dependence between layers and exhibiting different characteristics across the same network, choosing an optimal bitwidth per layer granularity is not a straight forward. As such, deep quantization opens a large hyper-parameter space, the exploration of which is a major challenge. We propose a novel sinusoidal regularization, called SINAREQ, for deep quantized training. Leveraging the sinusoidal properties, we seek to learn multiple quantization parameterization in conjunction during gradient-based training process. Specifically, we learn (i) a per-layer quantization bitwidth along with (ii) a scale factor through learning the period of the sinusoidal function. At the same time, we exploit the periodicity, differentiability, and the local convexity profile in sinusoidal functions to automatically propel (iii) network weights towards values quantized at levels that are jointly determined. We show how SINAREQ balance compute efficiency and accuracy, and provide a heterogeneous bitwidth assignment for quantization of a large variety of deep networks (AlexNet, CIFAR-10, MobileNet, ResNet-18, ResNet-20, SVHN, and VGG-11) that virtually preserves the accuracy. Furthermore, we carry out experimentation using fixed homogenous bitwidths with 3- to 5-bit assignment and show the versatility of SINAREQ in enhancing quantized training algorithms (DoReFa and WRPN) with about 4.8% accuracy improvements on average, and then outperforming multiple state-of-the-art techniques.
Shredder: Learning Noise to Protect Privacy with Partial DNN Inference on the Edge
May 26, 2019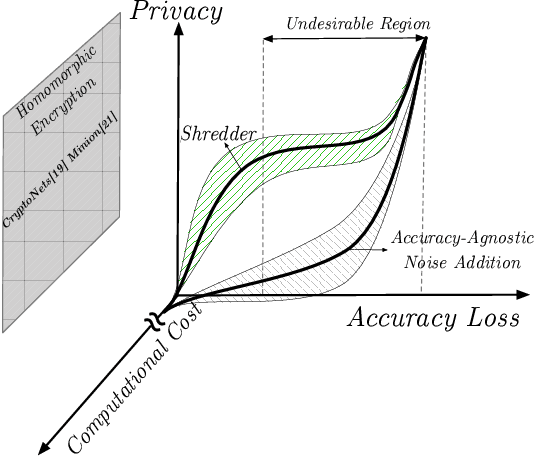
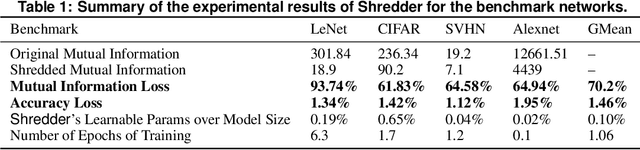
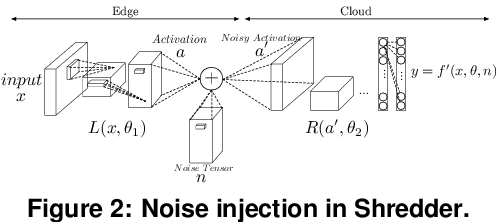
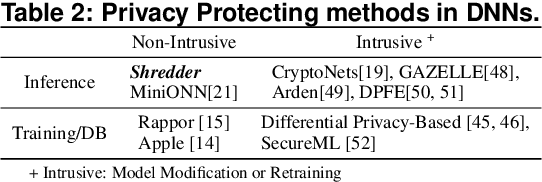
A wide variety of DNN applications increasingly rely on the cloud to perform their huge computation. This heavy trend toward cloud-hosted inference services raises serious privacy concerns. This model requires the sending of private and privileged data over the network to remote servers, exposing it to the service provider. Even if the provider is trusted, the data can still be vulnerable over communication channels or via side-channel attacks [1,2] at the provider. To that end, this paper aims to reduce the information content of the communicated data without compromising the cloud service's ability to provide a DNN inference with acceptably high accuracy. This paper presents an end-to-end framework, called Shredder, that, without altering the topology or the weights of a pre-trained network, learns an additive noise distribution that significantly reduces the information content of communicated data while maintaining the inference accuracy. Shredder learns the additive noise by casting it as a tensor of trainable parameters enabling us to devise a loss functions that strikes a balance between accuracy and information degradation. The loss function exposes a knob for a disciplined and controlled asymmetric trade-off between privacy and accuracy. While keeping the DNN intact, Shredder enables inference on noisy data without the need to update the model or the cloud. Experimentation with real-world DNNs shows that Shredder reduces the mutual information between the input and the communicated data to the cloud by 70.2% compared to the original execution while only sacrificing 1.46% loss in accuracy.