 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Does What in Deep Learning? Multidimensional Game-Theoretic Attribution of Function of Neural Units
Jun 24, 2025Neural networks now generate text, images, and speech with billions of parameters, producing a need to know how each neural unit contributes to these high-dimensional outputs. Existing explainable-AI methods, such as SHAP, attribute importance to inputs, but cannot quantify the contributions of neural units across thousands of output pixels, tokens, or logits. Here we close that gap with Multiperturbation Shapley-value Analysis (MSA), a model-agnostic game-theoretic framework. By systematically lesioning combinations of units, MSA yields Shapley Modes, unit-wise contribution maps that share the exact dimensionality of the model's output. We apply MSA across scales, from multi-layer perceptrons to the 56-billion-parameter Mixtral-8x7B and Generative Adversarial Networks (GAN). The approach demonstrates how regularisation concentrates computation in a few hubs, exposes language-specific experts inside the LLM, and reveals an inverted pixel-generation hierarchy in GANs. Together, these results showcase MSA as a powerful approach for interpreting, editing, and compressing deep neural networks.
Heterogeneous Reservoir Computing Models for Persian Speech Recognition
May 25, 2022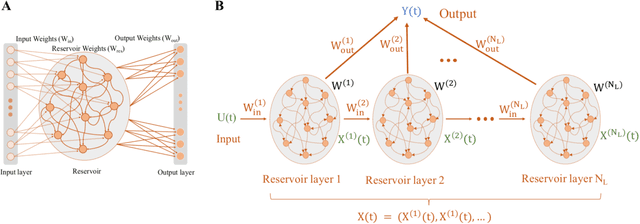
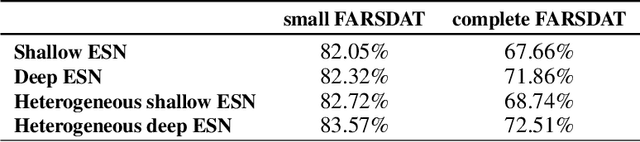
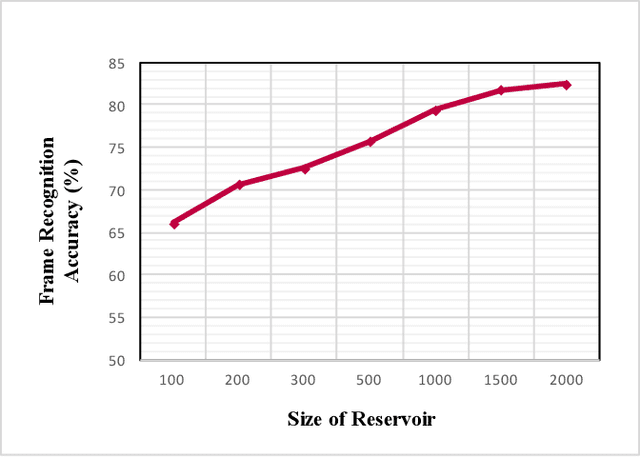
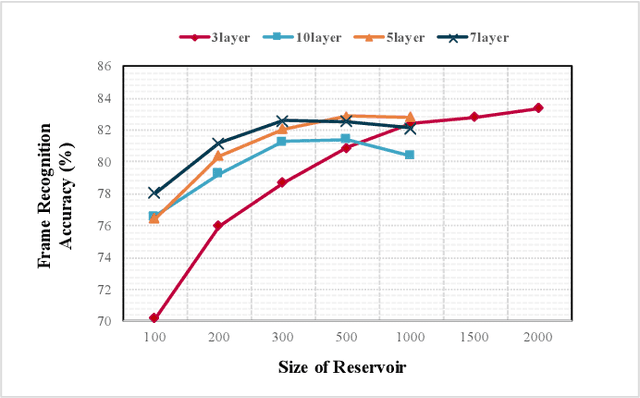
Over the last decade, deep-learning methods have been gradually incorporated into conventional automatic speech recognition (ASR) frameworks to create acoustic, pronunciation, and language models. Although it led to significant improvements in ASRs' recognition accuracy, due to their hard constraints related to hardware requirements (e.g., computing power and memory usage), it is unclear if such approaches are the most computationally- and energy-efficient options for embedded ASR applications. Reservoir computing (RC) models (e.g., echo state networks (ESNs) and liquid state machines (LSMs)), on the other hand, have been proven inexpensive to train, have vastly fewer parameters, and are compatible with emergent hardware technologies. However, their performance in speech processing tasks is relatively inferior to that of the deep-learning-based models. To enhance the accuracy of the RC in ASR applications, we propose heterogeneous single and multi-layer ESNs to create non-linear transformations of the inputs that capture temporal context at different scales. To test our models, we performed a speech recognition task on the Farsdat Persian dataset. Since, to the best of our knowledge, standard RC has not yet been employed to conduct any Persian ASR tasks, we also trained conventional single-layer and deep ESNs to provide baselines for comparison. Besides, we compared the RC performance with a standard long-short-term memory (LSTM) model. Heterogeneous RC models (1) show improved performance to the standard RC models; (2) perform on par in terms of recognition accuracy with the LSTM, and (3) reduce the training time considerably.
Causal Influences Decouple From Their Underlying Network Structure In Echo State Networks
May 24, 2022
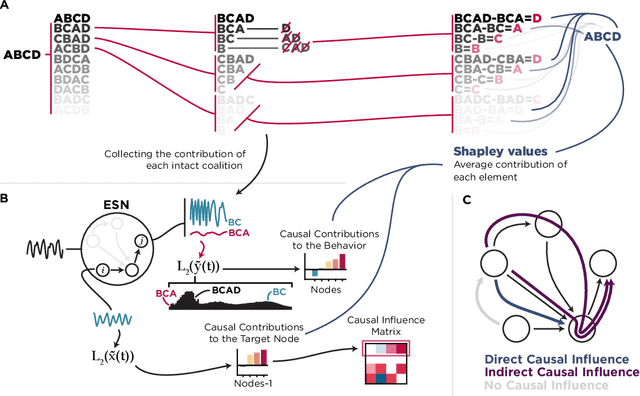


Echo State Networks (ESN) are versatile recurrent neural network models in which the hidden layer remains unaltered during training. Interactions among nodes of this static backbone produce diverse representations of the given stimuli that are harnessed by a read-out mechanism to perform computations needed for solving a given task. ESNs are accessible models of neuronal circuits, since they are relatively inexpensive to train. Therefore, ESNs have become attractive for neuroscientists studying the relationship between neural structure, function, and behavior. For instance, it is not yet clear how distinctive connectivity patterns of brain networks support effective interactions among their nodes and how these patterns of interactions give rise to computation. To address this question, we employed an ESN with a biologically inspired structure and used a systematic multi-site lesioning framework to quantify the causal contribution of each node to the network's output, thus providing a causal link between network structure and behavior. We then focused on the structure-function relationship and decomposed the causal influence of each node on all other nodes, using the same lesioning framework. We found that nodes in a properly engineered ESN interact largely irrespective of the network's underlying structure. However, in a network with the same topology and a non-optimal parameter set, the underlying connectivity patterns determine the node interactions. Our results suggest that causal structure-function relations in ESNs can be decomposed into two components, direct and indirect interactions. The former are based on influences relying on structural connections. The latter describe the effective communication between any two nodes through other intermediate nodes. These widely distributed indirect interactions may crucially contribute to the efficient performance of ESNs.
Neuromorphic Electronic Systems for Reservoir Computing
Aug 26, 2019


This chapter provides a comprehensive survey of the researches and motivations for hardware implementation of reservoir computing (RC) on neuromorphic electronic systems. Due to its computational efficiency and the fact that training amounts to a simple linear regression, both spiking and non-spiking implementations of reservoir computing on neuromorphic hardware have been developed. Here, a review of these experimental studies is provided to illustrate the progress in this area and to address the technical challenges which arise from this specific hardware implementation. Moreover, to deal with challenges of computation on such unconventional substrates, several lines of potential solutions are presented based on advances in other computational approaches in machine learning. keywords: Analog Microchips, FPGA, Memristors, Neuromorphic Architectures, Reservoir Computing
Reservoir Computing Models for Patient-Adaptable ECG Monitoring in Wearable Devices
Jul 22, 2019
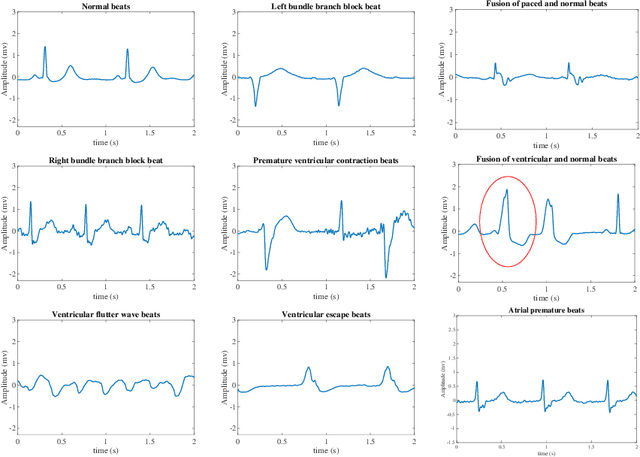


The reservoir computing paradigm is employed to classify heartbeat anomalies online based on electrocardiogram signals. Inspired by the principles of information processing in the brain, reservoir computing provides a framework to design, train, and analyze recurrent neural networks (RNNs) for processing time-dependent information. Due to its computational efficiency and the fact that training amounts to a simple linear regression, this supervised learning algorithm has been variously considered as a strategy to implement useful computations not only on digital computers but also on emerging unconventional hardware platforms such as neuromorphic microchips. Here, this biological-inspired learning framework is exploited to devise an accurate patient-adaptive model that has the potential to be integrated into wearable cardiac events monitoring devices. The proposed patient-customized model was trained and tested on ECG recordings selected from the MIT-BIH arrhythmia database. Restrictive inclusion criteria were used to conduct the study only on ECGs including, at least, two classes of heartbeats with highly unequal number of instances. The results of extensive simulations showed this model not only provides accurate, cheap and fast patient-customized heartbeat classifier but also circumvents the problem of "imbalanced classes" when the readout weights are trained using weighted ridge-regression.