 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning Approach for Arabic Offensive Language Detection System -- BERT-Based Model
Feb 09, 2021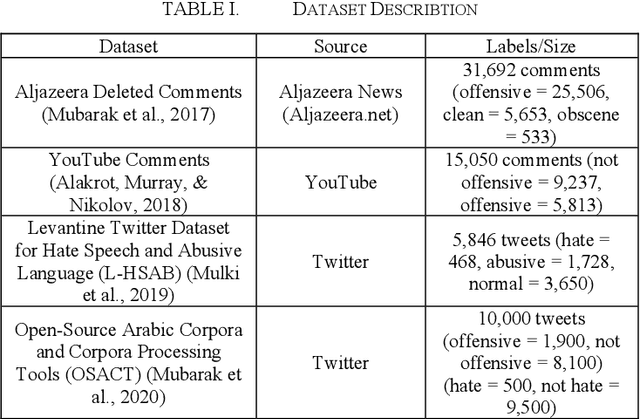
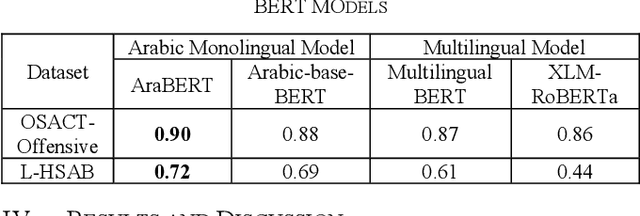
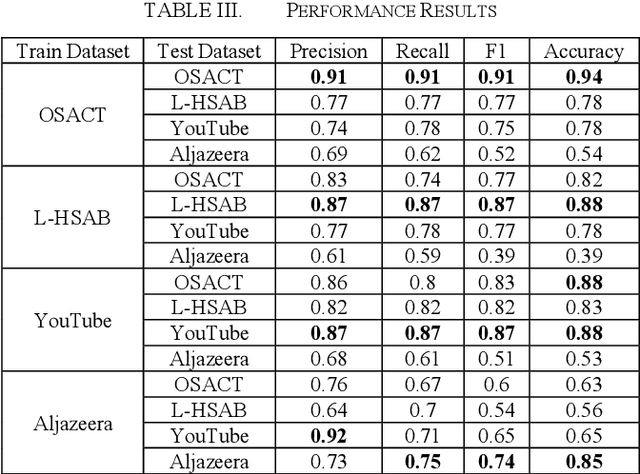
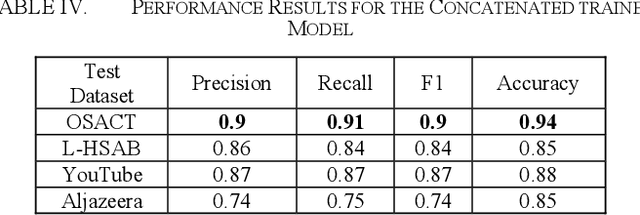
Developing a system to detect online offensive language is very important to the health and the security of online users. Studies have shown that cyberhate, online harassment and other misuses of technology are on the rise, particularly during the global Coronavirus pandemic in 2020. According to the latest report by the Anti-Defamation League (ADL), 35% of online users reported online harassment related to their identity-based characteristics, which is a 3% increase over 2019. Applying advanced techniques from the Natural Language Processing (NLP) field to support the development of an online hate-free community is a critical task for social justice. Transfer learning enhances the performance of the classifier by allowing the transfer of knowledge from one domain or one dataset to others that have not been seen before, thus, supporting the classifier to be more generalizable. In our study, we apply the principles of transfer learning cross multiple Arabic offensive language datasets to compare the effects on system performance. This study aims at investigating the effects of fine-tuning and training Bidirectional Encoder Representations from Transformers (BERT) model on multiple Arabic offensive language datasets individually and testing it using other datasets individually. Our experiment starts with a comparison among multiple BERT models to guide the selection of the main model that is used for our study. The study also investigates the effects of concatenating all datasets to be used for fine-tuning and training BERT model. Our results demonstrate the limited effects of transfer learning on the performance of the classifiers, particularly for highly dialectic comments.
Exploratory Arabic Offensive Language Dataset Analysis
Jan 20, 2021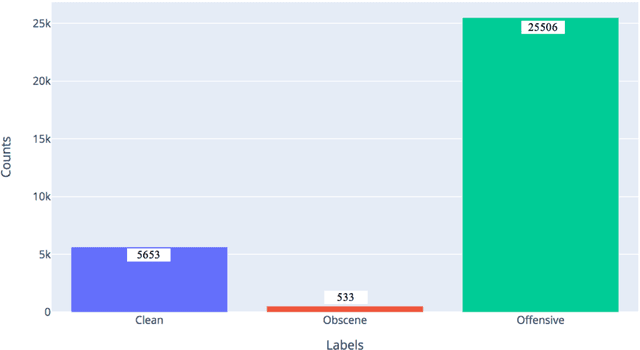
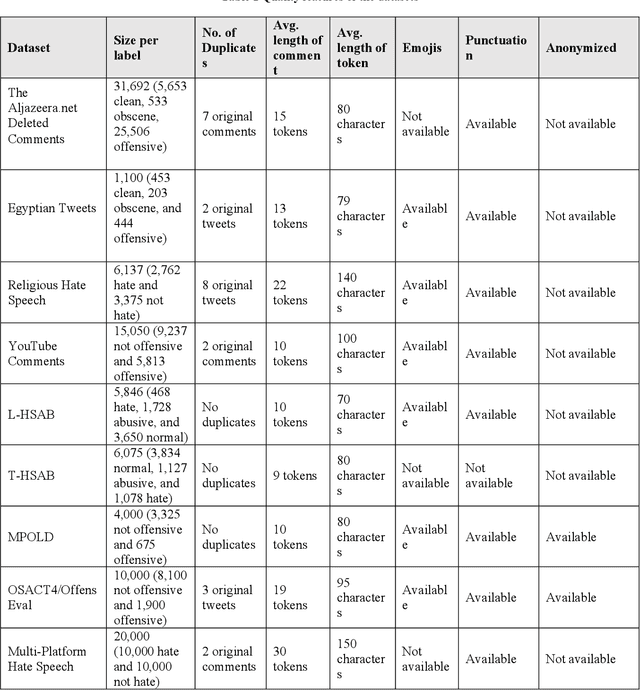

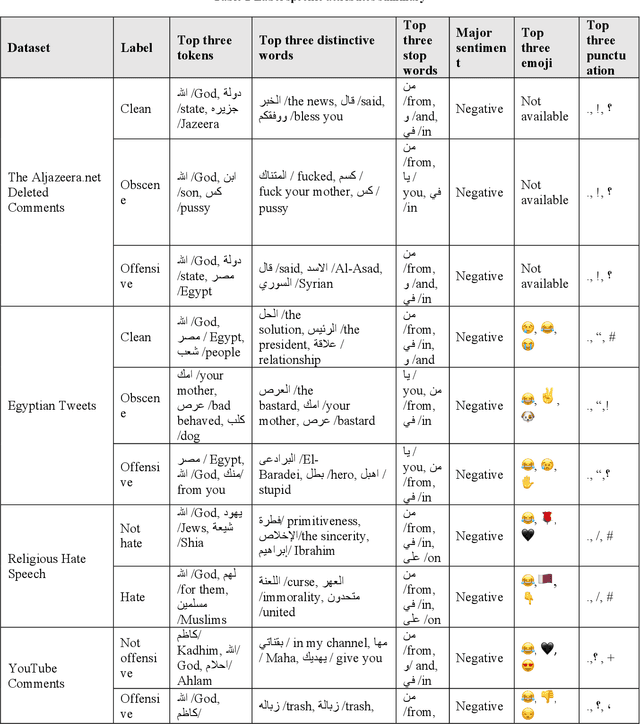
This paper adding more insights towards resources and datasets used in Arabic offensive language research. The main goal of this paper is to guide researchers in Arabic offensive language in selecting appropriate datasets based on their content, and in creating new Arabic offensive language resources to support and complement the available ones.
SalamNET at SemEval-2020 Task12: Deep Learning Approach for Arabic Offensive Language Detection
Jul 28, 2020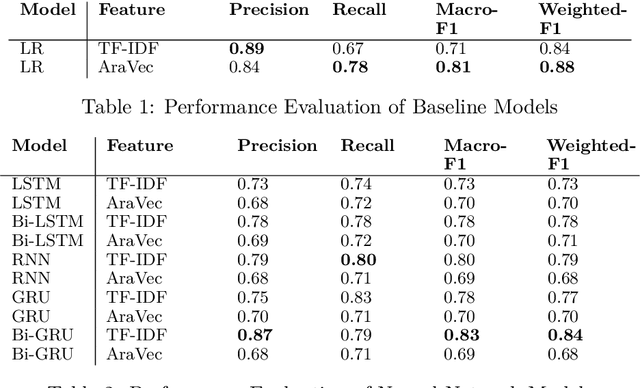
This paper describes SalamNET, an Arabic offensive language detection system that has been submitted to SemEval 2020 shared task 12: Multilingual Offensive Language Identification in Social Media. Our approach focuses on applying multiple deep learning models and conducting in depth error analysis of results to provide system implications for future development considerations. To pursue our goal, a Recurrent Neural Network (RNN), a Gated Recurrent Unit (GRU), and Long-Short Term Memory (LSTM) models with different design architectures have been developed and evaluated. The SalamNET, a Bi-directional Gated Recurrent Unit (Bi-GRU) based model, reports a macro-F1 score of 0.83.
Arabic Offensive Language Detection Using Machine Learning and Ensemble Machine Learning Approaches
May 16, 2020
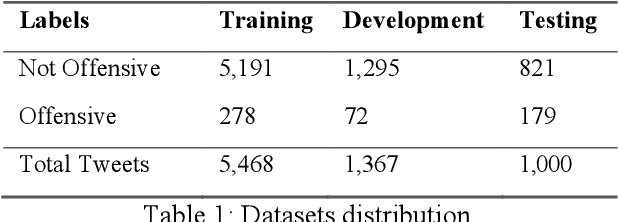
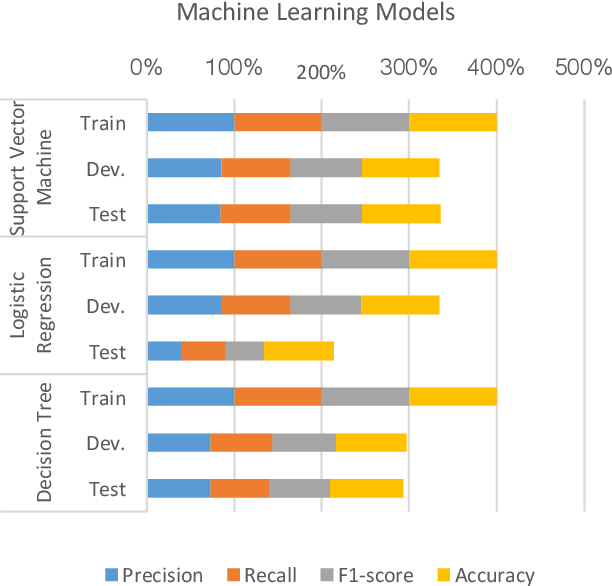
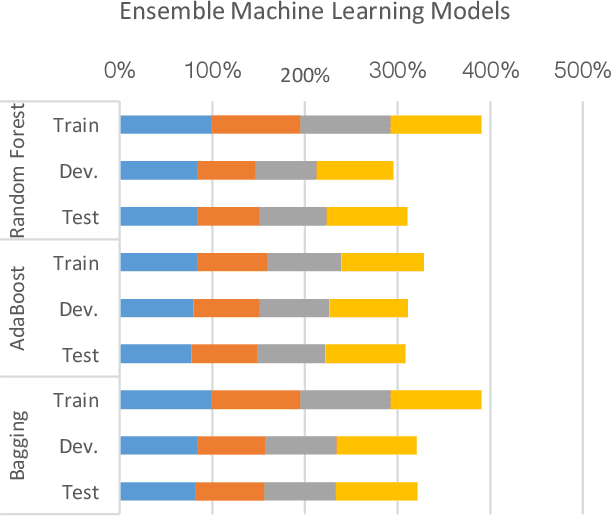
This study aims at investigating the effect of applying single learner machine learning approach and ensemble machine learning approach for offensive language detection on Arabic language. Classifying Arabic social media text is a very challenging task due to the ambiguity and informality of the written format of the text. Arabic language has multiple dialects with diverse vocabularies and structures, which increase the complexity of obtaining high classification performance. Our study shows significant impact for applying ensemble machine learning approach over the single learner machine learning approach. Among the trained ensemble machine learning classifiers, bagging performs the best in offensive language detection with F1 score of 88%, which exceeds the score obtained by the best single learner classifier by 6%. Our findings highlight the great opportunities of investing more efforts in promoting the ensemble machine learning approach solutions for offensive language detection models.
OSACT4 Shared Task on Offensive Language Detection: Intensive Preprocessing-Based Approach
May 14, 2020
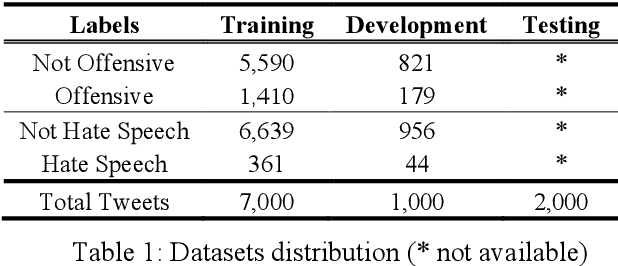

The preprocessing phase is one of the key phases within the text classification pipeline. This study aims at investigating the impact of the preprocessing phase on text classification, specifically on offensive language and hate speech classification for Arabic text. The Arabic language used in social media is informal and written using Arabic dialects, which makes the text classification task very complex. Preprocessing helps in dimensionality reduction and removing useless content. We apply intensive preprocessing techniques to the dataset before processing it further and feeding it into the classification model. An intensive preprocessing-based approach demonstrates its significant impact on offensive language detection and hate speech detection shared tasks of the fourth workshop on Open-Source Arabic Corpora and Corpora Processing Tools (OSACT). Our team wins the third place (3rd) in the Sub-Task A Offensive Language Detection division and wins the first place (1st) in the Sub-Task B Hate Speech Detection division, with an F1 score of 89% and 95%, respectively, by providing the state-of-the-art performance in terms of F1, accuracy, recall, and precision for Arabic hate speech detection.