 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Fine-Tuning of GPT Architectures for Parameter-Efficient Clinical Text Classification
Mar 15, 2026The rapid expansion of electronic health record (EHR) systems has generated large volumes of unstructured clinical narratives that contain valuable information for disease identification, patient cohort discovery, and clinical decision support. Extracting structured knowledge from these free-text documents remains challenging because clinical language is highly specialized, labeled datasets are limited, and full fine-tuning of large pretrained language models can require substantial computational resources. Efficient adaptation strategies are therefore essential for practical clinical natural language processing applications. This study proposes a parameter-efficient selective fine-tuning framework for adapting GPT-2 to clinical text classification tasks. Instead of updating the entire pretrained model, the majority of network parameters are frozen, and only the final Transformer block, the final layer normalization module, and a lightweight classification head are updated during training. This design substantially reduces the number of trainable parameters while preserving the contextual representation capabilities learned during pretraining. The proposed approach is evaluated using radiology reports from the MIMIC-IV-Note dataset with automatically derived CheXpert-style labels. Experiments on 50,000 radiology reports demonstrate that selective fine-tuning achieves approximately 91% classification accuracy while updating fewer than 6% of the model parameters. Comparative experiments with head-only training and full-model fine-tuning show that the proposed method provides a favorable balance between predictive performance and computational efficiency. These results indicate that selective fine-tuning offers an efficient and scalable framework for clinical text classification.
From Generative Modeling to Clinical Classification: A GPT-Based Architecture for EHR Notes
Jan 29, 2026The increasing availability of unstructured clinical narratives in electronic health records (EHRs) has created new opportunities for automated disease characterization, cohort identification, and clinical decision support. However, modeling long, domain-specific clinical text remains challenging due to limited labeled data, severe class imbalance, and the high computational cost of adapting large pretrained language models. This study presents a GPT-based architecture for clinical text classification that adapts a pretrained decoder-only Transformer using a selective fine-tuning strategy. Rather than updating all model parameters, the majority of the GPT-2 backbone is frozen, and training is restricted to the final Transformer block, the final layer normalization, and a lightweight classification head. This approach substantially reduces the number of trainable parameters while preserving the representational capacity required to model complex clinical language. The proposed method is evaluated on radiology reports from the MIMIC-IV-Note dataset using uncertainty-aware CheXpert-style labels derived directly from report text. Experiments cover multiple problem formulations, including multi-label classification of radiographic findings, binary per-label classification under different uncertainty assumptions, and aggregate disease outcome prediction. Across varying dataset sizes, the model exhibits stable convergence behavior and strong classification performance, particularly in settings dominated by non-mention and negated findings. Overall, the results indicate that selective fine-tuning of pretrained generative language models provides an efficient and effective pathway for clinical text classification, enabling scalable adaptation to real-world EHR data while significantly reducing computational complexity.
The Multi-phase spatial meta-heuristic algorithm for public health emergency transportation
Jul 05, 2021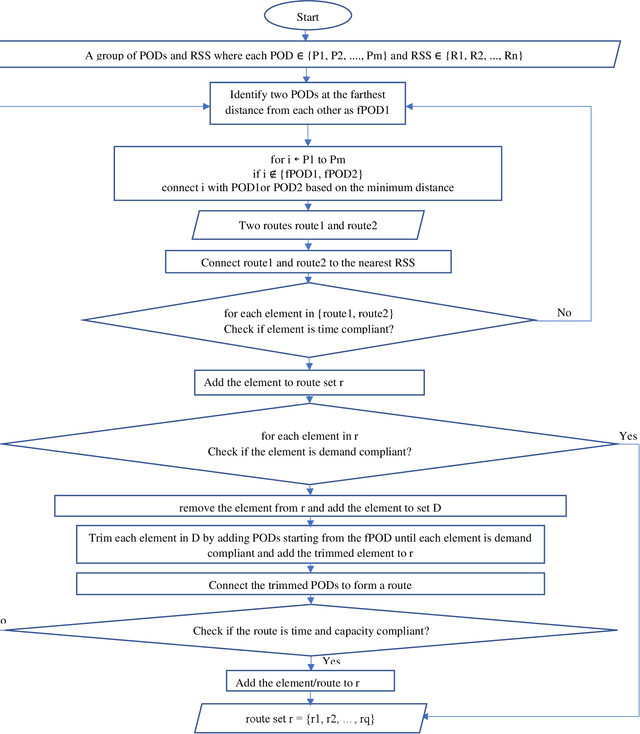
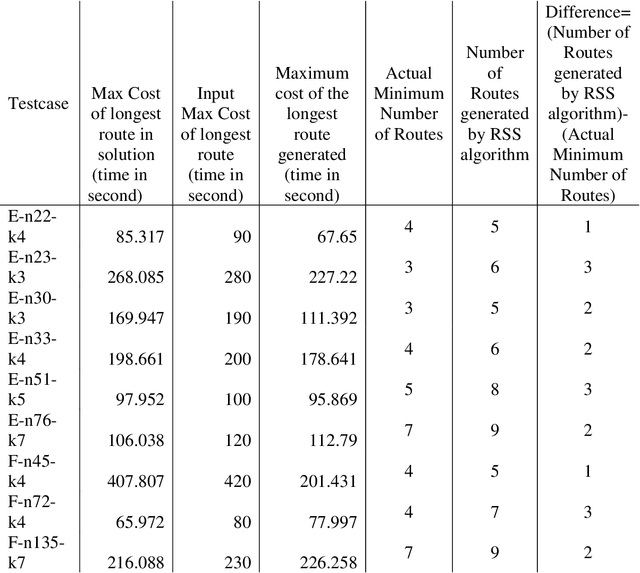
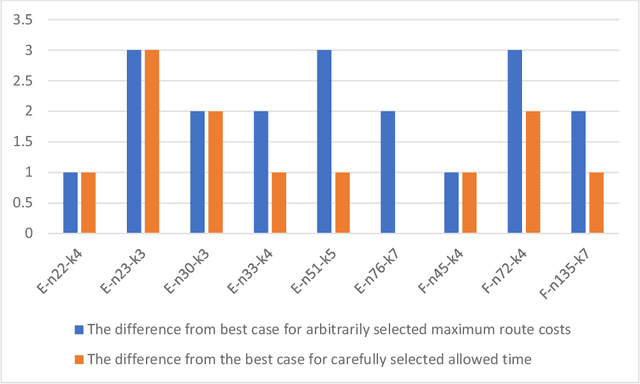
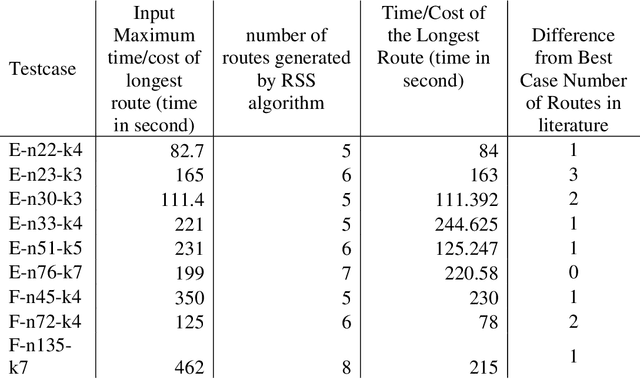
The delivery of Medical Countermeasures(MCMs) for mass prophylaxis in the case of a bio-terrorist attack is an active research topic that has interested the research community over the past decades. The objective of this study is to design an efficient algorithm for the Receive Reload and Store Problem(RSS) in which we aim to find feasible routes to deliver MCMs to a target population considering time, physical, and human resources, and capacity limitations. For doing this, we adapt the p-median problem to the POD-based emergency response planning procedures and propose an efficient algorithm solution to perform the p-median in reasonable computational time. We present RE-PLAN, the Response PLan Analyzer system that contains some RSS solutions developed at The Center for Computational Epidemiology and Response Analysis (CeCERA) at the University of North Texas. Finally, we analyze a study case where we show how the computational performance of the algorithm can impact the process of decision making and emergency planning in the short and long terms.