 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Latent Routing
May 14, 2026We investigate the temporal concatenation of sub-policies in Markov Decision Processes (MDP) with time-varying reward functions. We introduce General Dijkstra Search (GDS), and prove that globally optimal goal-reaching policies can be recovered through temporal composition of intermediate optimal sub-policies. Motivated by the "search, select, update" principle underlying GDS, we propose Dynamic Latent Routing (DLR), a language-model post-training method that jointly learns discrete latent codes, routing policies, and model parameters through dynamic search in a single training stage. In low-data fine-tuning settings, DLR matches or outperforms supervised fine-tuning across four datasets and six models, achieving a mean gain of +6.6 percentage points, while prior discrete-latent baselines consistently underperform SFT. Mechanistic analyses and targeted code ablations show that DLR learns structured routing behaviors with distinct causal roles.
Memorization-Compression Cycles Improve Generalization
May 13, 2025We prove theoretically that generalization improves not only through data scaling but also by compressing internal representations. To operationalize this insight, we introduce the Information Bottleneck Language Modeling (IBLM) objective, which reframes language modeling as a constrained optimization problem: minimizing representation entropy subject to optimal prediction performance. Empirically, we observe an emergent memorization-compression cycle during LLM pretraining, evidenced by oscillation positive/negative gradient alignment between cross-entropy and Matrix-Based Entropy (MBE), a measure of representation entropy. This pattern closely mirrors the predictive-compressive trade-off prescribed by IBLM and also parallels the biological alternation between awake learning and sleep consolidation. Motivated by this observation, we propose Gated Phase Transition (GAPT), a training algorithm that adaptively switches between memorization and compression phases. When applied to GPT-2 pretraining on FineWeb dataset, GAPT reduces MBE by 50% and improves cross-entropy by 4.8%. GAPT improves OOD generalizatino by 35% in a pretraining task on arithmetic multiplication. In a setting designed to simulate catastrophic forgetting, GAPT reduces interference by compressing and separating representations, achieving a 97% improvement in separation - paralleling the functional role of sleep consolidation.
Scaling LLM Pre-training with Vocabulary Curriculum
Feb 25, 2025Modern language models rely on static vocabularies, fixed before pretraining, in contrast to the adaptive vocabulary acquisition observed in human language learning. To bridge this gap, we introduce vocabulary curriculum learning, an approach that improves pretraining efficiency with log-linear scaling gains relative to vocabulary size. Our method alternates between entropy-guided vocabulary expansion and model optimization, enabling models to learn transferable representations across diverse tokenization granularities. This approach naturally gives rise to an optimal computation allocation pattern: longer tokens capture predictable content, while shorter tokens focus on more complex, harder-to-predict contexts. Experiments on small-scale GPT models demonstrate improved scaling efficiency, reinforcing the effectiveness of dynamic tokenization. We release our code to support further research and plan to extend our experiments to larger models and diverse domains.
Iterative Graph Alignment
Aug 29, 2024
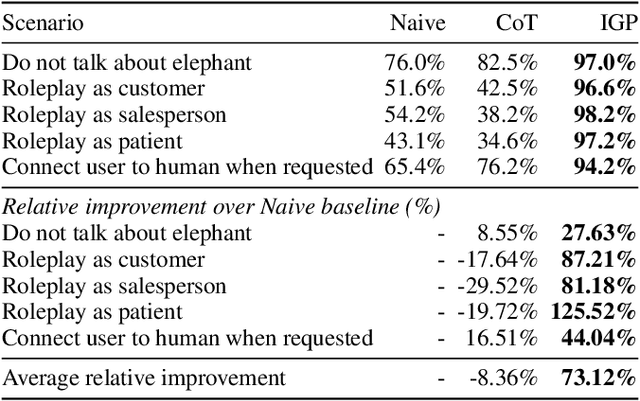
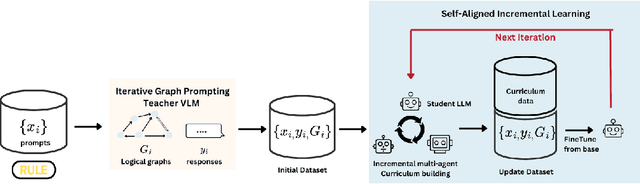
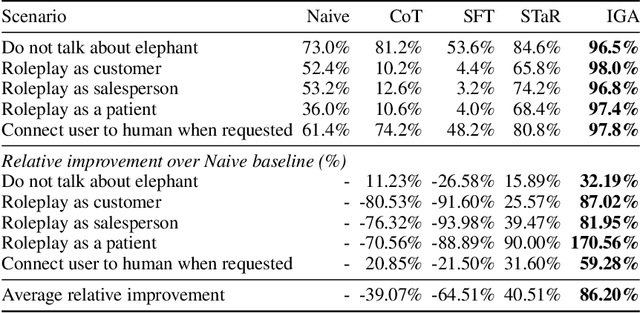
By compressing diverse narratives, LLMs go beyond memorization, achieving intelligence by capturing generalizable causal relationships. However, they suffer from local 'representation gaps' due to insufficient training data diversity, limiting their real-world utility, especially in tasks requiring strict alignment to rules. Traditional alignment methods relying on heavy human annotations are inefficient and unscalable. Recent self-alignment techniques also fall short, as they often depend on self-selection based prompting and memorization-based learning. To address these issues, we introduce Iterative Graph Alignment (IGA), an annotation-free rule-based alignment algorithm. A teacher model (VLM) employs Iterative Graph Prompting (IGP) to create logical graphs and reference answers. The student model (LLM) identifies local knowledge gaps by attempting to align its responses with these references, collaborating with helper models to generate diverse answers. These aligned responses are then used for iterative supervised fine-tuning (SFT). Our evaluations across five rule-based scenarios demonstrate IGP's effectiveness, with a 73.12\% alignment improvement in Claude Sonnet 3.5, and Llama3-8B-Instruct achieving an 86.20\% improvement, outperforming Claude Sonnet 3.5 in rule-based alignment.