 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tokens to Policy: Causal and Interpretable Heterogeneous Treatment Effects Identification
Jun 15, 2026Heterogeneous Treatment Effect (HTE) identification is crucial to explain the impact of an intervention and optimize our policies accordingly. Existing approaches trade expressivity for interpretability, but, if some active heterogeneity drivers are unmeasured, methods at both ends of this spectrum allow for spurious HTE characterization with no causal reading. In this work, we focus on controlled experiments and argue that an oracle HTE causal characterization via the latent interactors is now within reach, thanks to (i) more extensive pre-treatment measurements, i.e., multi-modal and multi-view, and (ii) scalable representations with minimal human supervision. We then re-frame HTE identification as a Markov-blanket discovery problem on a sufficient and aligned pre-treatment representation, and introduce Neural EXposure Interaction Search (NEXIS), an iterative procedure with provable and empirically validated consistent selection. We deploy NEXIS on two anti-poverty programs in Africa, augmenting each with satellite imagery capturing previously unmeasured environmental effect modifiers, leading to novel, interpretable and prescriptive guidelines to optimize the programs' next iterations.
Assessing the Carbon Emissions and Energy Consumption of U.S. Hyperscale Data Centers
Jun 03, 2026The rapid proliferation of hyperscale data centers (HDCs) in the US, mainly driven by the adoption of artificial intelligence, has raised concerns about this industry's environmental footprint. We compiled facility-level information on 403 US hyperscale data centers operating between May 2024 and April 2025 and estimated their electricity consumption, electricity sources, and attributable CO2 emissions. Across different facility-load scenarios, these HDCs consumed approximately 68-99 TWh of electricity and were associated with about 37-54 million metric tons of CO2. Under the central scenario, HDC electricity demand corresponded to approximately 1.8% of total US electricity consumption, with roughly 54% of attributed generation supplied by fossil-fuel sources. The HDC electricity-weighted average carbon intensity was approximately 545 gCO2/kWh, about 48% above the contemporaneous US national grid-average carbon intensity of 370 gCO2/kWh. Our approach provides an attributional tool for assessing the environmental footprint of hyperscale data centers using the most recent EPA eGRID plant-level data.
Towards a Health-Based Power Grid Optimization in the Artificial Intelligence Era
Oct 11, 2024
The electric power sector is one of the largest contributors to greenhouse gas emissions in the world. In recent years, there has been an unprecedented increase in electricity demand driven by the so-called Artificial Intelligence (AI) revolution. Although AI has and will continue to have a transformative impact, its environmental and health impacts are often overlooked. The standard approach to power grid optimization aims to minimize CO$_2$ emissions. In this paper, we propose a new holistic paradigm. Our proposed optimization directly targets the minimization of adverse health outcomes under energy efficiency and emission constraints. We show the first example of an optimal fuel mix allocation problem aiming to minimize the average number of adverse health effects resulting from exposure to hazardous air pollutants with constraints on the average and marginal emissions. We argue that this new health-based power grid optimization is essential to promote truly sustainable technological advances that align both with global climate goals and public health priorities.
Towards Optimal Environmental Policies: Policy Learning under Arbitrary Bipartite Network Interference
Oct 10, 2024



The substantial effect of air pollution on cardiovascular disease and mortality burdens is well-established. Emissions-reducing interventions on coal-fired power plants -- a major source of hazardous air pollution -- have proven to be an effective, but costly, strategy for reducing pollution-related health burdens. Targeting the power plants that achieve maximum health benefits while satisfying realistic cost constraints is challenging. The primary difficulty lies in quantifying the health benefits of intervening at particular plants. This is further complicated because interventions are applied on power plants, while health impacts occur in potentially distant communities, a setting known as bipartite network interference (BNI). In this paper, we introduce novel policy learning methods based on Q- and A-Learning to determine the optimal policy under arbitrary BNI. We derive asymptotic properties and demonstrate finite sample efficacy in simulations. We apply our novel methods to a comprehensive dataset of Medicare claims, power plant data, and pollution transport networks. Our goal is to determine the optimal strategy for installing power plant scrubbers to minimize ischemic heart disease (IHD) hospitalizations under various cost constraints. We find that annual IHD hospitalization rates could be reduced in a range from 20.66-44.51 per 10,000 person-years through optimal policies under different cost constraints.
Causal Rule Ensemble: Interpretable Inference of Heterogeneous Treatment Effects
Sep 18, 2020

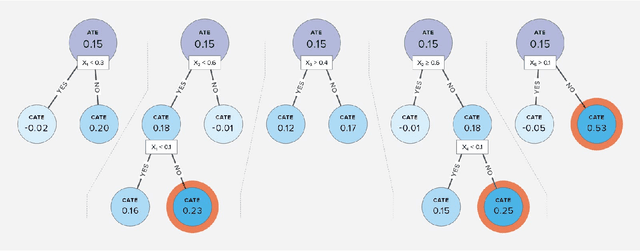

In environmental epidemiology, it is critically important to identify subpopulations that are most vulnerable to the adverse effects of air pollution so we can develop targeted interventions. In recent years, there have been many methodological developments for addressing heterogeneity of treatment effects in causal inference. A common approach is to estimate the conditional average treatment effect (CATE) for a pre-specified covariate set. However, this approach does not provide an easy-to-interpret tool for identifying susceptible subpopulations or discover new subpopulations that are not defined a priori by the researchers. In this paper, we propose a new causal rule ensemble (CRE) method with two features simultaneously: 1) ensuring interpretability by revealing heterogeneous treatment effect structures in terms of decision rules and 2) providing CATE estimates with high statistical precision similar to causal machine learning algorithms. We provide theoretical results that guarantee consistency of the estimated causal effects for the newly discovered causal rules. Furthermore, via simulations, we show that the CRE method has competitive performance on its ability to discover subpopulations and then accurately estimate the causal effects. We also develop a new sensitivity analysis method that examine robustness to unmeasured confounding bias. Lastly, we apply the CRE method to the study of the effects of long-term exposure to air pollution on the 5-year mortality rate of the New England Medicare-enrolled population in United States. Code is available at https://github.com/kwonsang/causal_rule_ensemble.
Supervised learning for the prediction of firm dynamics
Sep 11, 2020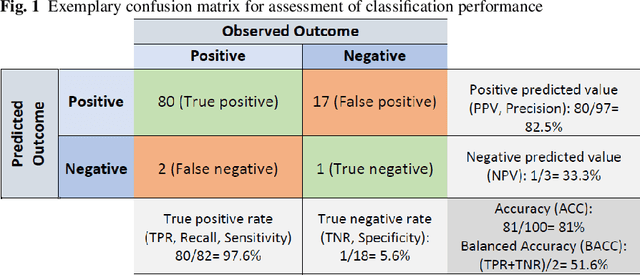
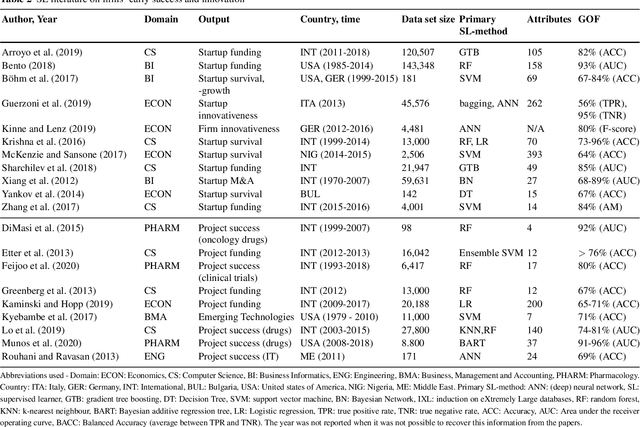
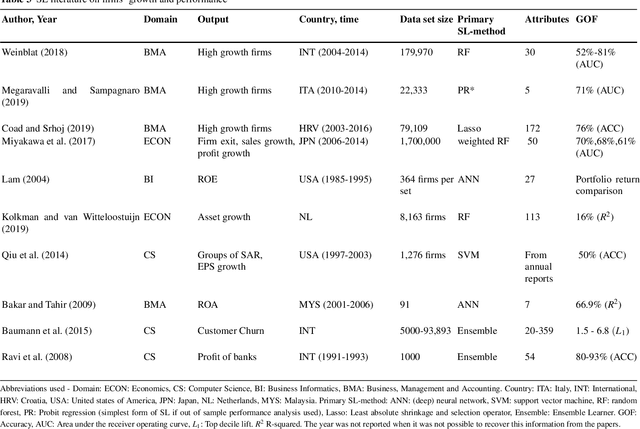
Thanks to the increasing availability of granular, yet high-dimensional, firm level data, machine learning (ML) algorithms have been successfully applied to address multiple research questions related to firm dynamics. Especially supervised learning (SL), the branch of ML dealing with the prediction of labelled outcomes, has been used to better predict firms' performance. In this contribution, we will illustrate a series of SL approaches to be used for prediction tasks, relevant at different stages of the company life cycle. The stages we will focus on are (i) startup and innovation, (ii) growth and performance of companies, and (iii) firms exit from the market. First, we review SL implementations to predict successful startups and R&D projects. Next, we describe how SL tools can be used to analyze company growth and performance. Finally, we review SL applications to better forecast financial distress and company failure. In the concluding Section, we extend the discussion of SL methods in the light of targeted policies, result interpretability, and causality.
Heterogeneous causal effects with imperfect compliance: a novel Bayesian machine learning approach
May 29, 2019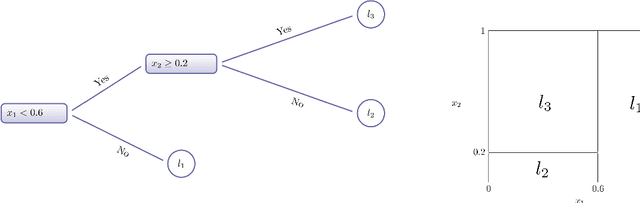



This paper introduces an innovative Bayesian machine learning algorithm to draw inference on heterogeneous causal effects in the presence of imperfect compliance (e.g., under an irregular assignment mechanism). We show, through Monte Carlo simulations, that the proposed Bayesian Causal Forest with Instrumental Variable (BCF-IV) algorithm outperforms other machine learning techniques tailored for causal inference (namely, Generalized Random Forest and Causal Trees with Instrumental Variable) in estimating the causal effects. Moreover, we show that it converges to an optimal asymptotic performance in discovering the drivers of heterogeneity in a simulated scenario. BCF-IV sheds a light on the heterogeneity of causal effects in instrumental variable scenarios and, in turn, provides the policy-makers with a relevant tool for targeted policies. Its empirical application evaluates the effects of additional funding on students' performances. The results indicate that BCF-IV could be used to enhance the effectiveness of school funding on students' performance by 3.2 to 3.5 times.