 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformalized Super Learner
Apr 24, 2026The Super Learner (SL) is a widely used ensemble method that combines predictions from a library of learners based on their predictive performance. Interval predictions are of considerable practical interest because they allow uncertainty in predictions produced by an individual learner or an ensemble to be quantified. Several methods have been proposed for constructing interval predictions based on the SL, however, these approaches are typically justified using asymptotic arguments or rely on computationally intensive procedures such as the bootstrap. Conformal prediction (CP) is a machine learning framework for constructing prediction intervals with finite-sample and asymptotic coverage guarantees under mild conditions. We propose coupling CP with the SL through a natural construction that mirrors the original SL framework, using individual learner weights and combining learner-specific conformity scores via a weighted majority vote. We characterize the properties of the resulting SL-based prediction intervals for continuous outcomes. We cover settings under exchangeability, potential violations of exchangeability, and data-generating mechanisms exhibiting heteroscedasticity, sparsity, and other forms of distributional heterogeneity. A comprehensive simulation study shows that the conformalized SL achieves valid finite-sample coverage with competitive performance relative to the true data-generating mechanism. A central contribution of this work is an application to predicting creatinine levels using socio-demographic, biometric, and laboratory measurements. This example demonstrates the benefits of an ensemble with carefully selected learners designed to capture key aspects of complex regression functions, including non-linear effects, interactions, sparsity, heteroscedasticity, and robustness to outliers.R
Modelling Preference Data with the Wallenius Distribution
Jun 28, 2018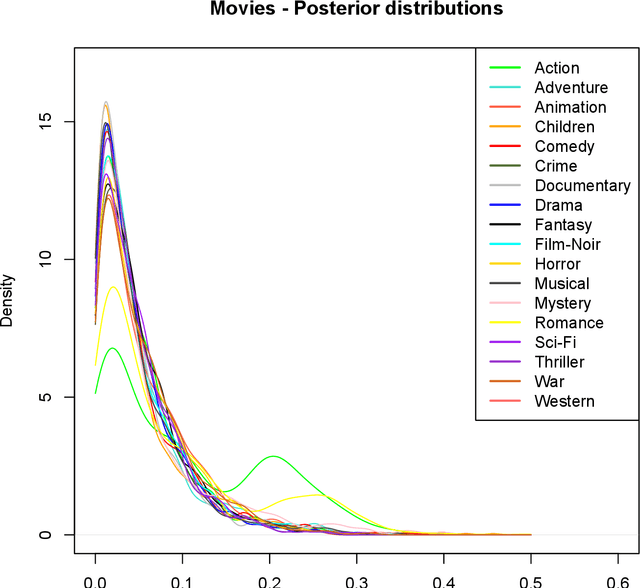
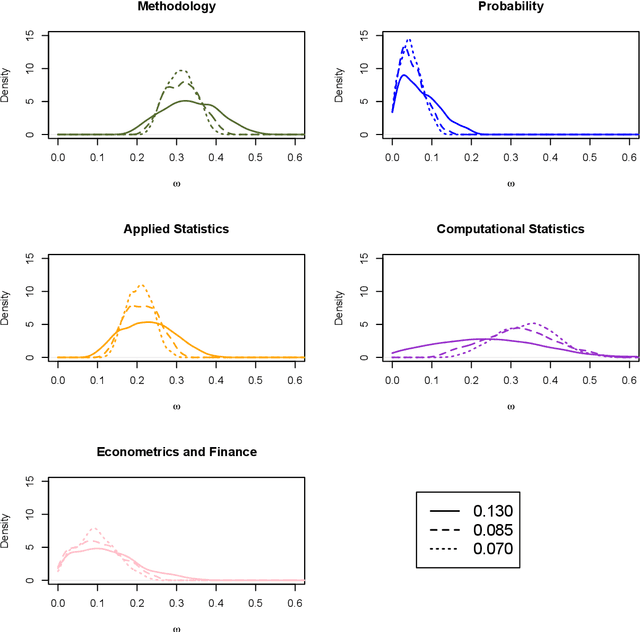
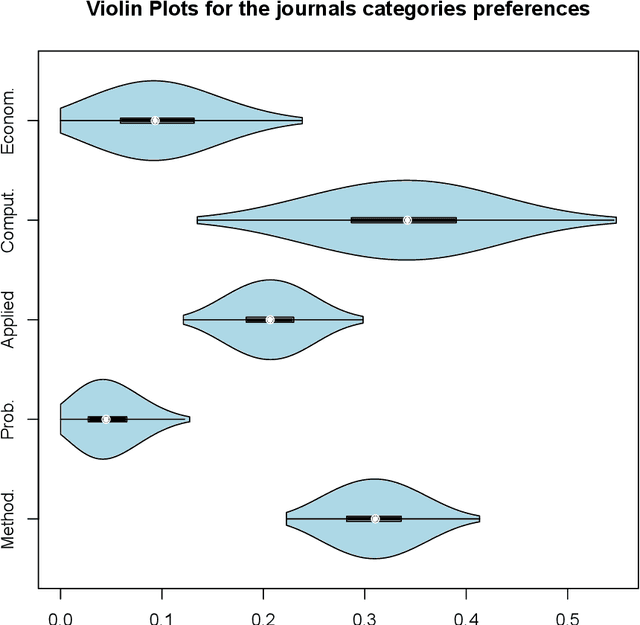
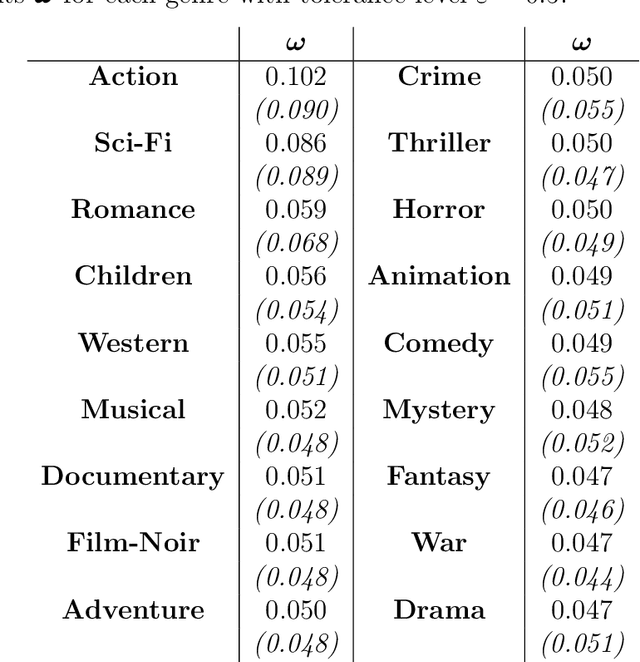
The Wallenius distribution is a generalisation of the Hypergeometric distribution where weights are assigned to balls of different colours. This naturally defines a model for ranking categories which can be used for classification purposes. Since, in general, the resulting likelihood is not analytically available, we adopt an approximate Bayesian computational (ABC) approach for estimating the importance of the categories. We illustrate the performance of the estimation procedure on simulated datasets. Finally, we use the new model for analysing two datasets about movies ratings and Italian academic statisticians' journal preferences. The latter is a novel dataset collected by the authors.
Objective Bayesian Analysis for Change Point Problems
Jan 07, 2018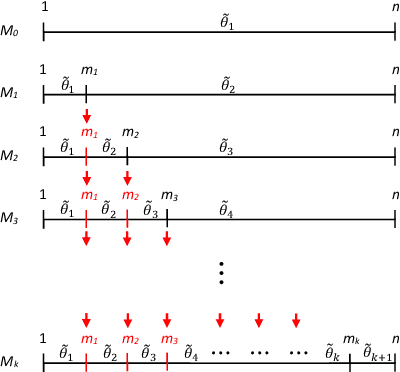
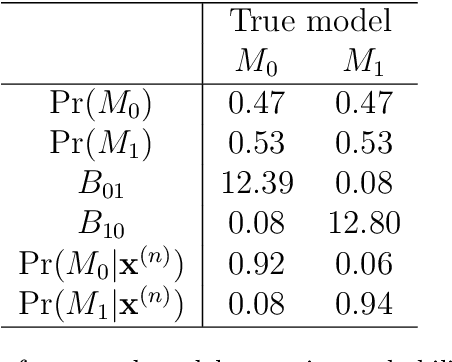
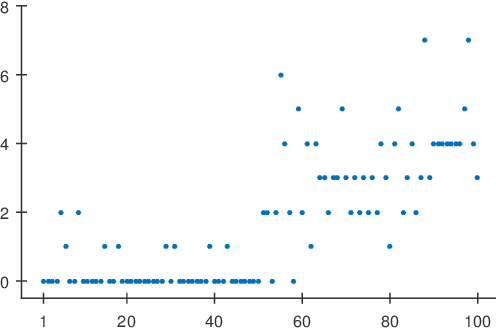
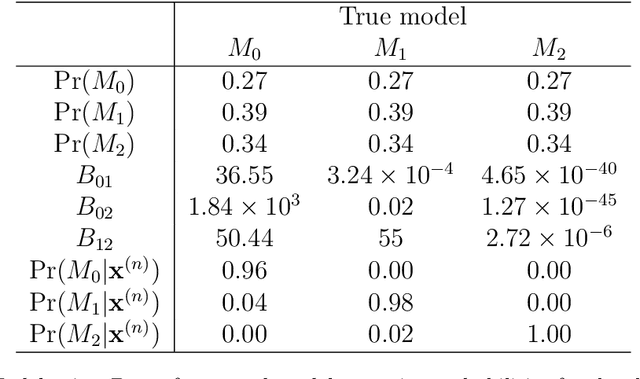
In this paper we present a loss-based approach to change point analysis. In particular, we look at the problem from two perspectives. The first focuses on the definition of a prior when the number of change points is known a priori. The second contribution aims to estimate the number of change points by using a loss-based approach recently introduced in the literature. The latter considers change point estimation as a model selection exercise. We show the performance of the proposed approach on simulated data and real data sets.
Modelling and computation using NCoRM mixtures for density regression
Aug 31, 2017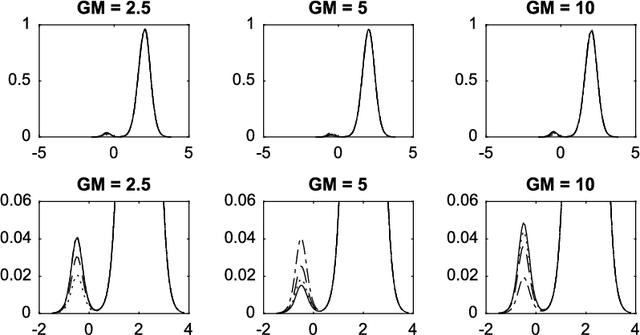
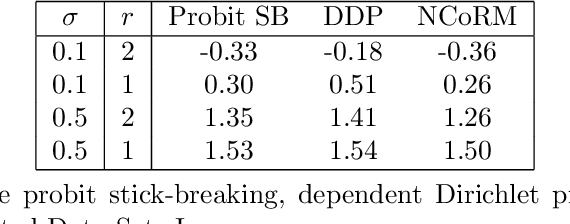
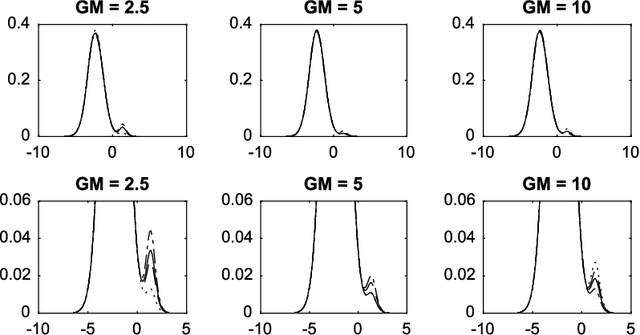
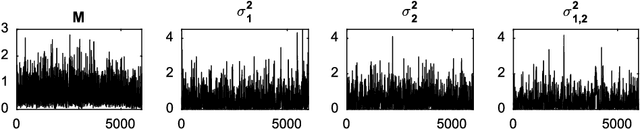
Normalized compound random measures are flexible nonparametric priors for related distributions. We consider building general nonparametric regression models using normalized compound random measure mixture models. Posterior inference is made using a novel pseudo-marginal Metropolis-Hastings sampler for normalized compound random measure mixture models. The algorithm makes use of a new general approach to the unbiased estimation of Laplace functionals of compound random measures (which includes completely random measures as a special case). The approach is illustrated on problems of density regression.
Generalized Species Sampling Priors with Latent Beta reinforcements
Aug 01, 2014
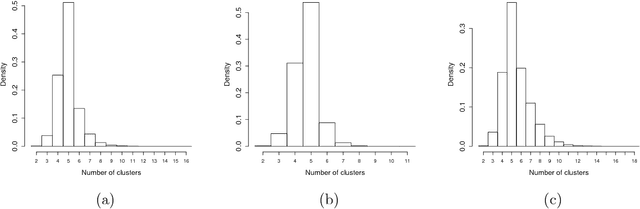
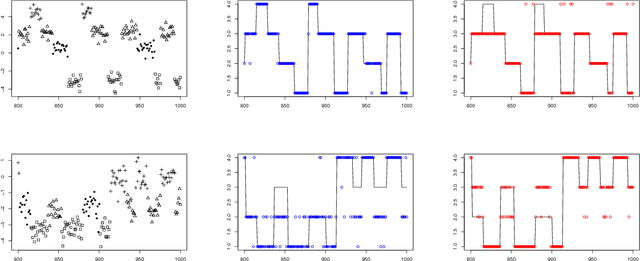
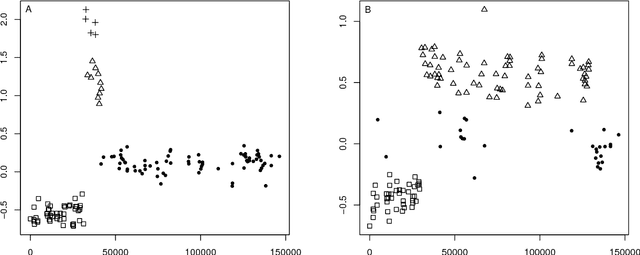
Many popular Bayesian nonparametric priors can be characterized in terms of exchangeable species sampling sequences. However, in some applications, exchangeability may not be appropriate. We introduce a {novel and probabilistically coherent family of non-exchangeable species sampling sequences characterized by a tractable predictive probability function with weights driven by a sequence of independent Beta random variables. We compare their theoretical clustering properties with those of the Dirichlet Process and the two parameters Poisson-Dirichlet process. The proposed construction provides a complete characterization of the joint process, differently from existing work. We then propose the use of such process as prior distribution in a hierarchical Bayes modeling framework, and we describe a Markov Chain Monte Carlo sampler for posterior inference. We evaluate the performance of the prior and the robustness of the resulting inference in a simulation study, providing a comparison with popular Dirichlet Processes mixtures and Hidden Markov Models. Finally, we develop an application to the detection of chromosomal aberrations in breast cancer by leveraging array CGH data.