 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScattering Transform for Auditory Attention Decoding
Feb 26, 2026The use of hearing aids will increase in the coming years due to demographic change. One open problem that remains to be solved by a new generation of hearing aids is the cocktail party problem. A possible solution is electroencephalography-based auditory attention decoding. This has been the subject of several studies in recent years, which have in common that they use the same preprocessing methods in most cases. In this work, in order to achieve an advantage, the use of a scattering transform is proposed as an alternative to these preprocessing methods. The two-layer scattering transform is compared with a regular filterbank, the synchrosqueezing short-time Fourier transform and the common preprocessing. To demonstrate the performance, the known and the proposed preprocessing methods are compared for different classification tasks on two widely used datasets, provided by the KU Leuven (KUL) and the Technical University of Denmark (DTU). Both established and new neural-network-based models, CNNs, LSTMs, and recent Transformer/graph-based models are used for classification. Various evaluation strategies were compared, with a focus on the task of classifying speakers who are unknown from the training. We show that the two-layer scattering transform can significantly improve the performance for subject-related conditions, especially on the KUL dataset. However, on the DTU dataset, this only applies to some of the models, or when larger amounts of training data are provided, as in 10-fold cross-validation. This suggests that the scattering transform is capable of extracting additional relevant information.
Audio Scene Classification with Deep Recurrent Neural Networks
Jun 05, 2017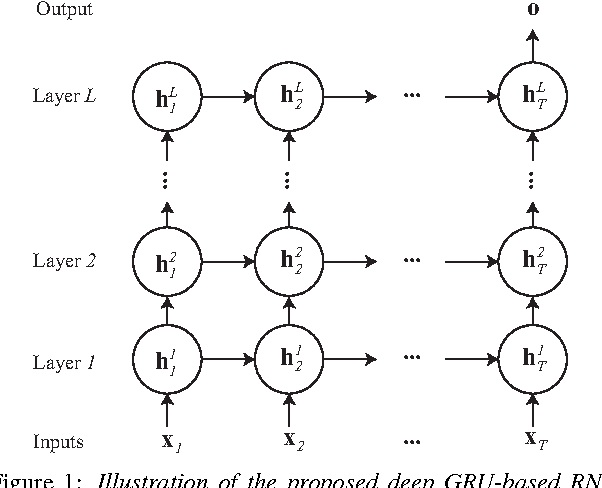

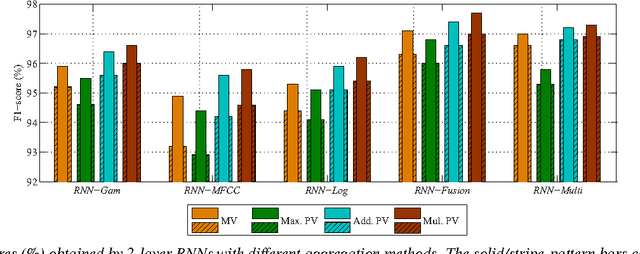
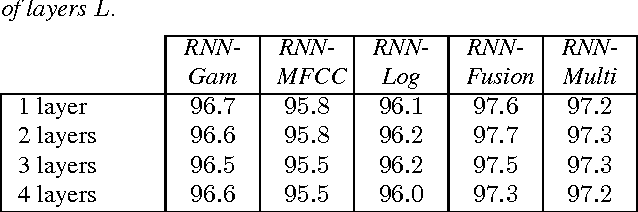
We introduce in this work an efficient approach for audio scene classification using deep recurrent neural networks. An audio scene is firstly transformed into a sequence of high-level label tree embedding feature vectors. The vector sequence is then divided into multiple subsequences on which a deep GRU-based recurrent neural network is trained for sequence-to-label classification. The global predicted label for the entire sequence is finally obtained via aggregation of subsequence classification outputs. We will show that our approach obtains an F1-score of 97.7% on the LITIS Rouen dataset, which is the largest dataset publicly available for the task. Compared to the best previously reported result on the dataset, our approach is able to reduce the relative classification error by 35.3%.