 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Galerkin Normalizing Flow for Transition Probability Density Functions of Diffusion Models
Mar 19, 2026We propose a new Neural Galerkin Normalizing Flow framework to approximate the transition probability density function of a diffusion process by solving the corresponding Fokker-Planck equation with an atomic initial distribution, parametrically with respect to the location of the initial mass. By using Normalizing Flows, we look for the solution as a transformation of the transition probability density function of a reference stochastic process, ensuring that our approximation is structure-preserving and automatically satisfies positivity and mass conservation constraints. By extending Neural Galerkin schemes to the context of Normalizing Flows, we derive a system of ODEs for the time evolution of the Normalizing Flow's parameters. Adaptive sampling routines are used to evaluate the Fokker-Planck residual in meaningful locations, which is of vital importance to address high-dimensional PDEs. Numerical results show that this strategy captures key features of the true solution and enforces the causal relationship between the initial datum and the density function at subsequent times. After completing an offline training phase, online evaluation becomes significantly more cost-effective than solving the PDE from scratch. The proposed method serves as a promising surrogate model, which could be deployed in many-query problems associated with stochastic differential equations, like Bayesian inference, simulation, and diffusion bridge generation.
LAGO: A Local-Global Optimization Framework Combining Trust Region Methods and Bayesian Optimization
Mar 03, 2026We introduce LAGO, a LocAl-Global Optimization algorithm that combines gradient-enhanced Bayesian Optimization (BO) with gradient-based trust region local refinement through an adaptive competition mechanism. At each iteration, global and local optimization strategies independently propose candidate points, and the next evaluation is selected based on predicted improvement. LAGO separates global exploration from local refinement at the proposal level: the BO acquisition function is optimized outside the active trust region, while local function and gradient evaluations are incorporated into the global gradient-enhanced Gaussian process only when they satisfy a lengthscale-based minimum-distance criterion, reducing the risk of numerical instability during the local exploitation. This enables efficient local refinement when reaching promising regions, without sacrificing a global search of the design space. As a result, the method achieves an improved exploration of the full design space compared to standard non-linear local optimization algorithms for smooth functions, while maintaining fast local convergence in regions of interest.
Sparse Polynomial Chaos expansions using Variational Relevance Vector Machines
Dec 23, 2019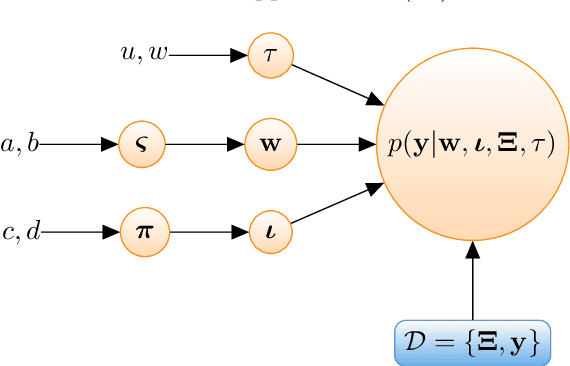
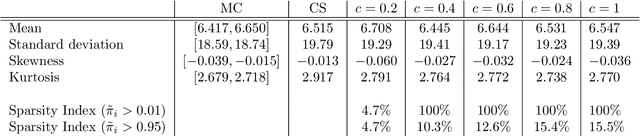
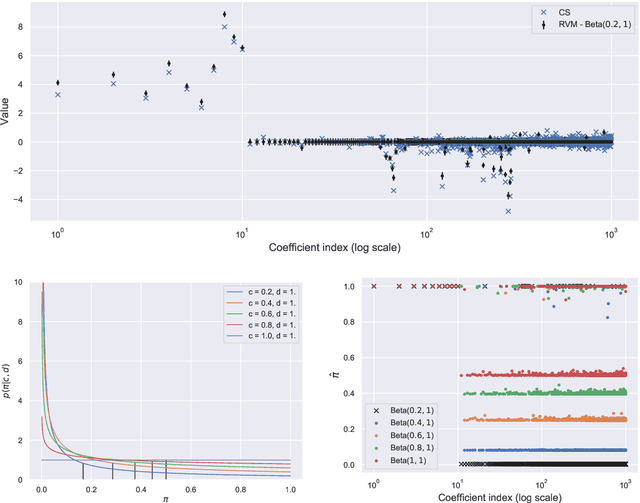
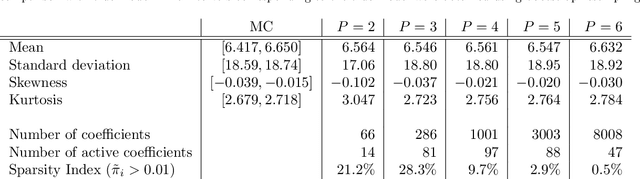
The challenges for non-intrusive methods for Polynomial Chaos modeling lie in the computational efficiency and accuracy under a limited number of model simulations. These challenges can be addressed by enforcing sparsity in the series representation through retaining only the most important basis terms. In this work, we present a novel sparse Bayesian learning technique for obtaining sparse Polynomial Chaos expansions which is based on a Relevance Vector Machine model and is trained using Variational Inference. The methodology shows great potential in high-dimensional data-driven settings using relatively few data points and achieves user-controlled sparse levels that are comparable to other methods such as compressive sensing. The proposed approach is illustrated on two numerical examples, a synthetic response function that is explored for validation purposes and a low-carbon steel plate with random Young's modulus and random loading, which is modeled by stochastic finite element with 38 input random variables.