 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMental Disorders on Online Social Media Through the Lens of Language and Behaviour: Analysis and Visualisation
Feb 07, 2022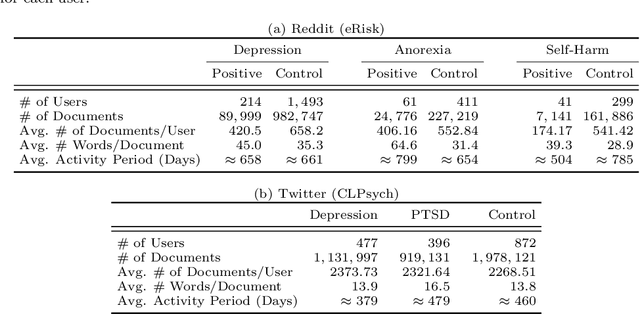
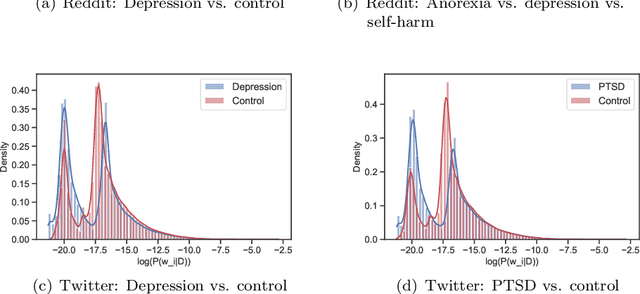
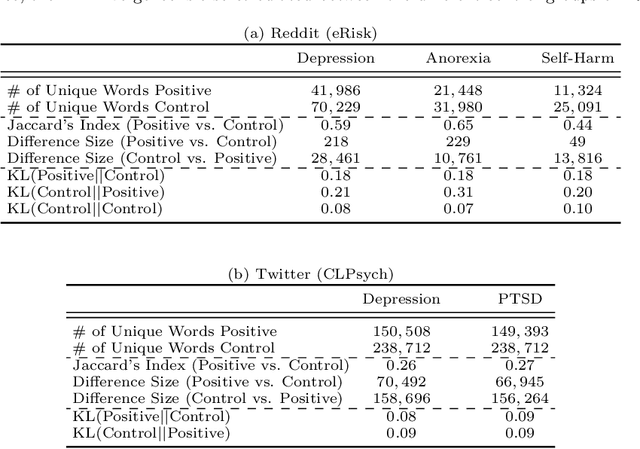
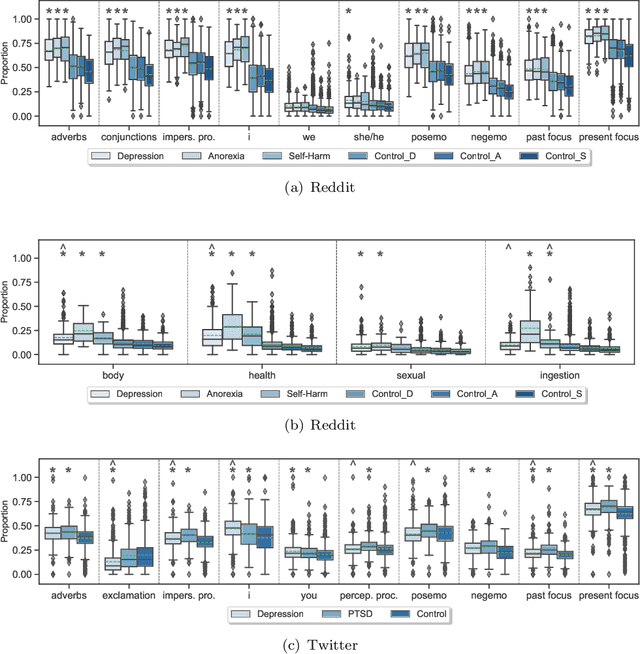
Due to the worldwide accessibility to the Internet along with the continuous advances in mobile technologies, physical and digital worlds have become completely blended, and the proliferation of social media platforms has taken a leading role over this evolution. In this paper, we undertake a thorough analysis towards better visualising and understanding the factors that characterise and differentiate social media users affected by mental disorders. We perform different experiments studying multiple dimensions of language, including vocabulary uniqueness, word usage, linguistic style, psychometric attributes, emotions' co-occurrence patterns, and online behavioural traits, including social engagement and posting trends. Our findings reveal significant differences on the use of function words, such as adverbs and verb tense, and topic-specific vocabulary, such as biological processes. As for emotional expression, we observe that affected users tend to share emotions more regularly than control individuals on average. Overall, the monthly posting variance of the affected groups is higher than the control groups. Moreover, we found evidence suggesting that language use on micro-blogging platforms is less distinguishable for users who have a mental disorder than other less restrictive platforms. In particular, we observe on Twitter less quantifiable differences between affected and control groups compared to Reddit.
A Systematic Analysis on the Impact of Contextual Information on Point-of-Interest Recommendation
Jan 20, 2022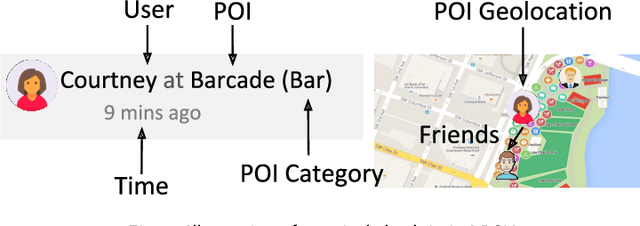
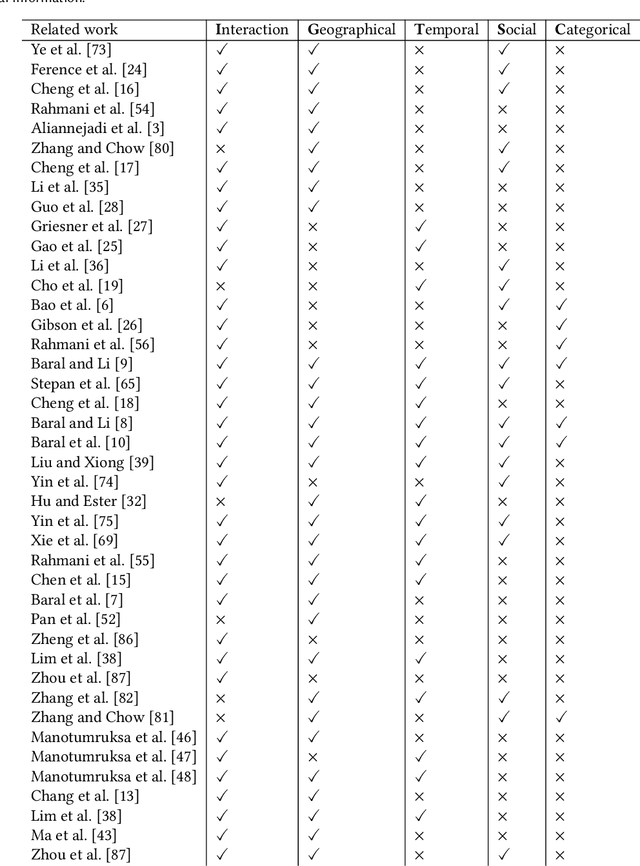
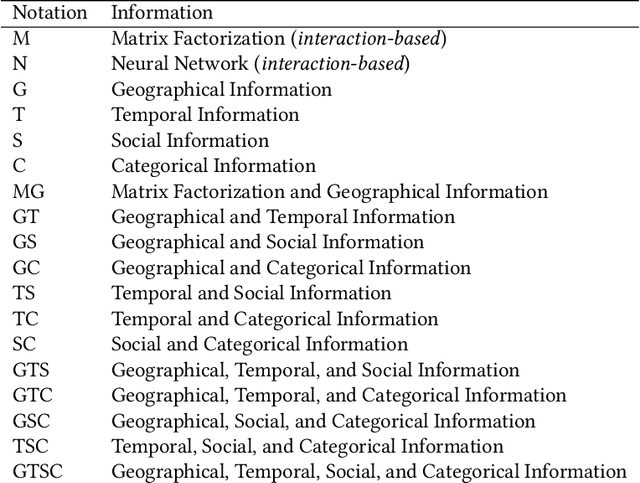
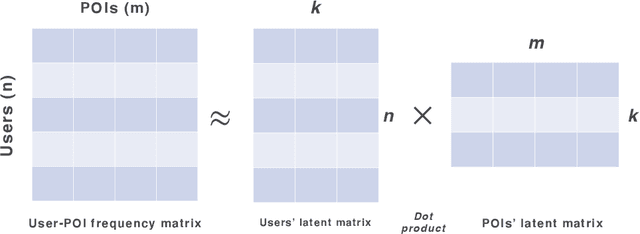
As the popularity of Location-based Social Networks (LBSNs) increases, designing accurate models for Point-of-Interest (POI) recommendation receives more attention. POI recommendation is often performed by incorporating contextual information into previously designed recommendation algorithms. Some of the major contextual information that has been considered in POI recommendation are the location attributes (i.e., exact coordinates of a location, category, and check-in time), the user attributes (i.e., comments, reviews, tips, and check-in made to the locations), and other information, such as the distance of the POI from user's main activity location, and the social tie between users. The right selection of such factors can significantly impact the performance of the POI recommendation. However, previous research does not consider the impact of the combination of these different factors. In this paper, we propose different contextual models and analyze the fusion of different major contextual information in POI recommendation. The major contributions of this paper are: (i) providing an extensive survey of context-aware location recommendation (ii) quantifying and analyzing the impact of different contextual information (e.g., social, temporal, spatial, and categorical) in the POI recommendation on available baselines and two new linear and non-linear models, that can incorporate all the major contextual information into a single recommendation model, and (iii) evaluating the considered models using two well-known real-world datasets. Our results indicate that while modeling geographical and temporal influences can improve recommendation quality, fusing all other contextual information into a recommendation model is not always the best strategy.
Keyword Extraction for Improved Document Retrieval in Conversational Search
Sep 22, 2021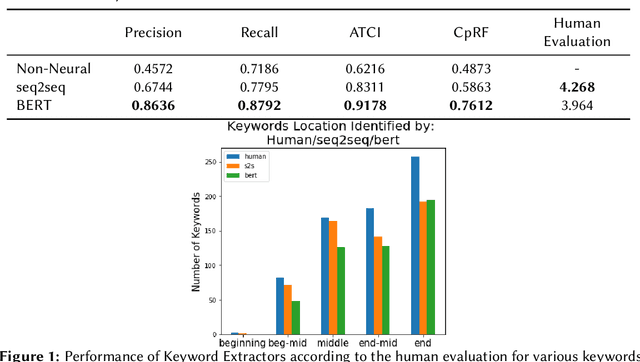
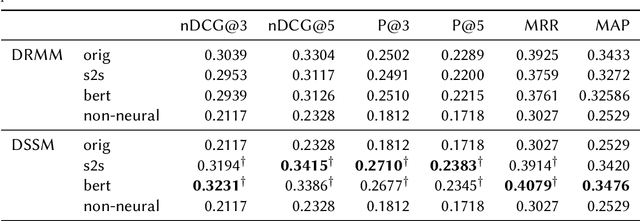
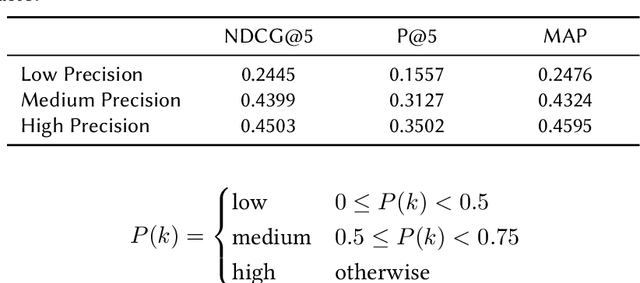
Recent research has shown that mixed-initiative conversational search, based on the interaction between users and computers to clarify and improve a query, provides enormous advantages. Nonetheless, incorporating additional information provided by the user from the conversation poses some challenges. In fact, further interactions could confuse the system as a user might use words irrelevant to the information need but crucial for correct sentence construction in the context of multi-turn conversations. To this aim, in this paper, we have collected two conversational keyword extraction datasets and propose an end-to-end document retrieval pipeline incorporating them. Furthermore, we study the performance of two neural keyword extraction models, namely, BERT and sequence to sequence, in terms of extraction accuracy and human annotation. Finally, we study the effect of keyword extraction on the end-to-end neural IR performance and show that our approach beats state-of-the-art IR models. We make the two datasets publicly available to foster research in this area.
The Impact of User Demographics and Task Types on Cross-App Mobile Search
Sep 14, 2021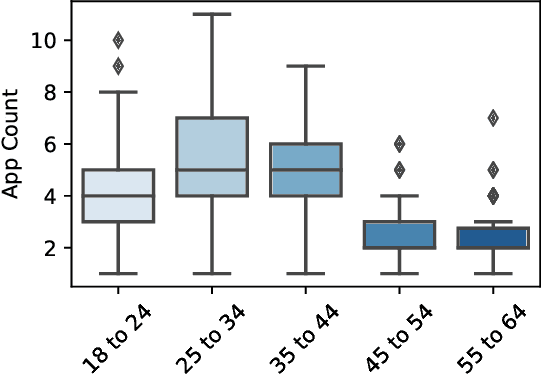
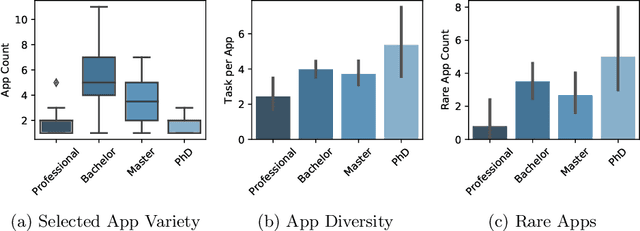
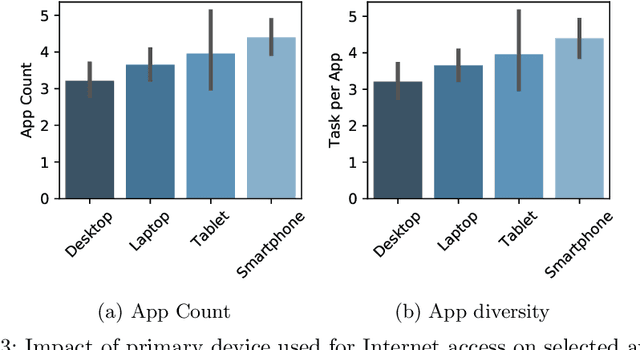
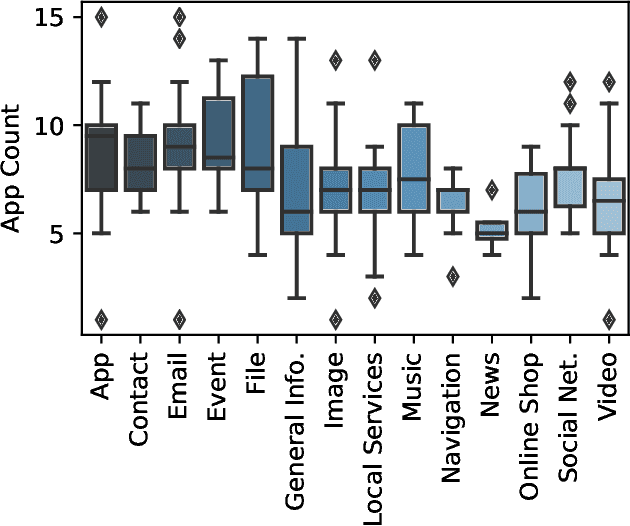
Recent developments in the mobile app industry have resulted in various types of mobile apps, each targeting a different need and a specific audience. Consequently, users access distinct apps to complete their information need tasks. This leads to the use of various apps not only separately, but also collaboratively in the same session to achieve a single goal. Recent work has argued the need for a unified mobile search system that would act as metasearch on users' mobile devices. The system would identify the target apps for the user's query, submit the query to the apps, and present the results to the user in a unified way. In this work, we aim to deepen our understanding of user behavior while accessing information on their mobile phones by conducting an extensive analysis of various aspects related to the search process. In particular, we study the effect of task type and user demographics on their behavior in interacting with mobile apps. Our findings reveal trends and patterns that can inform the design of a more effective mobile information access environment.
User Engagement Prediction for Clarification in Search
Feb 08, 2021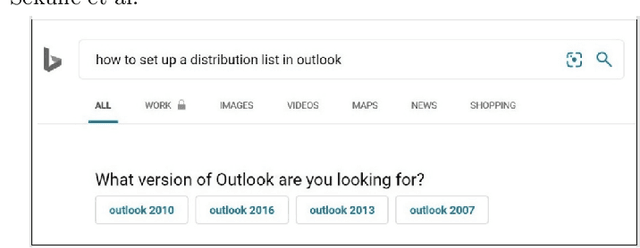
Clarification is increasingly becoming a vital factor in various topics of information retrieval, such as conversational search and modern Web search engines. Prompting the user for clarification in a search session can be very beneficial to the system as the user's explicit feedback helps the system improve retrieval massively. However, it comes with a very high risk of frustrating the user in case the system fails in asking decent clarifying questions. Therefore, it is of great importance to determine when and how to ask for clarification. To this aim, in this work, we model search clarification prediction as user engagement problem. We assume that the better a clarification is, the higher user engagement with it would be. We propose a Transformer-based model to tackle the task. The comparison with competitive baselines on large-scale real-life clarification engagement data proves the effectiveness of our model. Also, we analyse the effect of all result page elements on the performance and find that, among others, the ranked list of the search engine leads to considerable improvements. Our extensive analysis of task-specific features guides future research.
Context-Aware Target Apps Selection and Recommendation for Enhancing Personal Mobile Assistants
Jan 09, 2021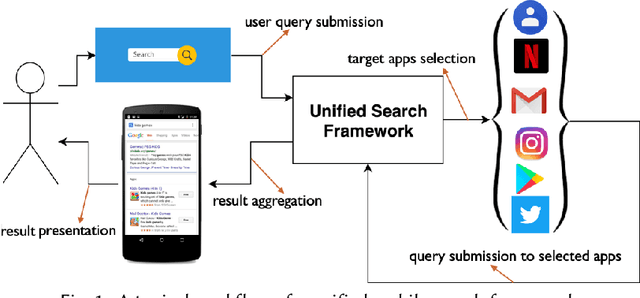
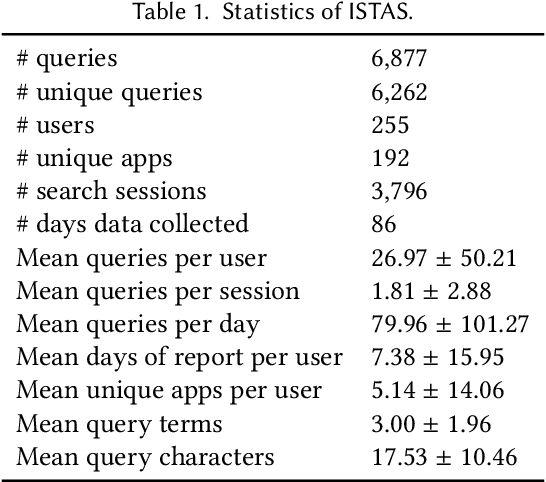
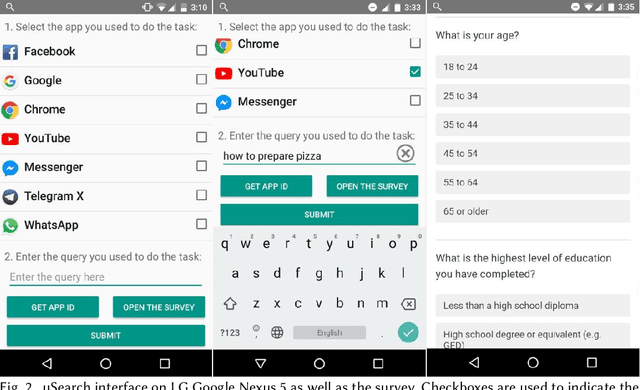
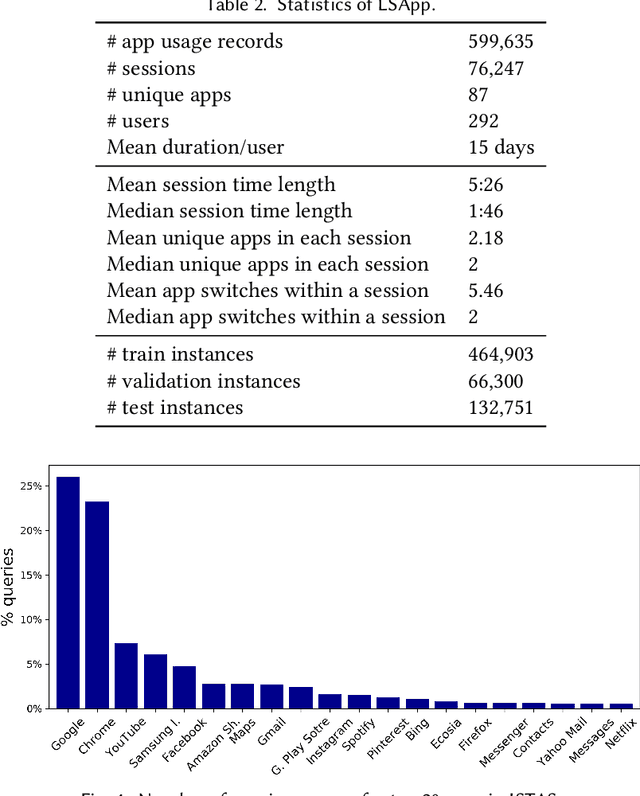
Users install many apps on their smartphones, raising issues related to information overload for users and resource management for devices. Moreover, the recent increase in the use of personal assistants has made mobile devices even more pervasive in users' lives. This paper addresses two research problems that are vital for developing effective personal mobile assistants: target apps selection and recommendation. The former is the key component of a unified mobile search system: a system that addresses the users' information needs for all the apps installed on their devices with a unified mode of access. The latter, instead, predicts the next apps that the users would want to launch. Here we focus on context-aware models to leverage the rich contextual information available to mobile devices. We design an in situ study to collect thousands of mobile queries enriched with mobile sensor data (now publicly available for research purposes). With the aid of this dataset, we study the user behavior in the context of these tasks and propose a family of context-aware neural models that take into account the sequential, temporal, and personal behavior of users. We study several state-of-the-art models and show that the proposed models significantly outperform the baselines.
Harnessing Evolution of Multi-Turn Conversations for Effective Answer Retrieval
Jan 31, 2020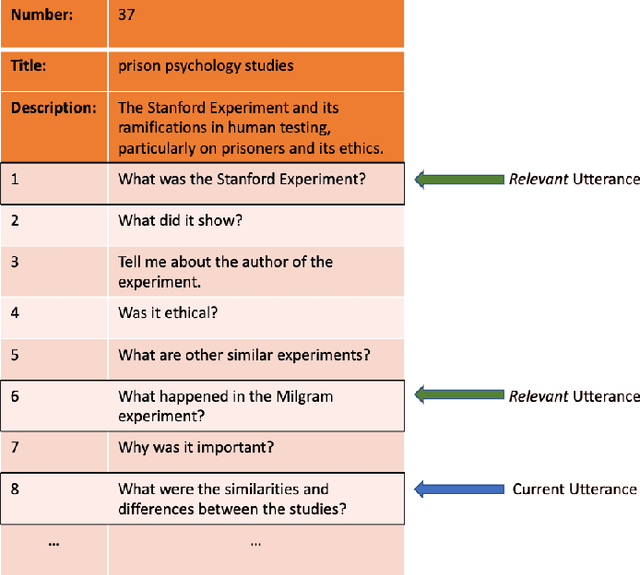
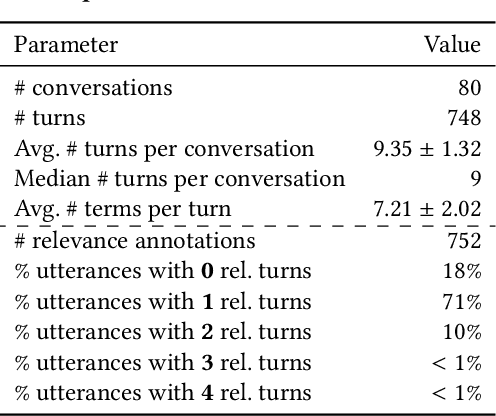
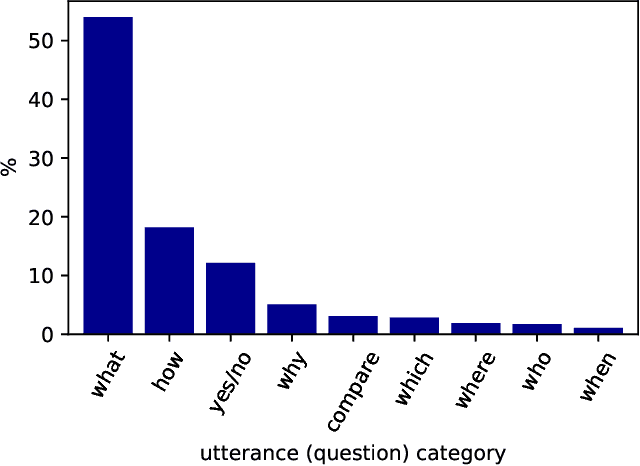

With the improvements in speech recognition and voice generation technologies over the last years, a lot of companies have sought to develop conversation understanding systems that run on mobile phones or smart home devices through natural language interfaces. Conversational assistants, such as Google Assistant and Microsoft Cortana, can help users to complete various types of tasks. This requires an accurate understanding of the user's information need as the conversation evolves into multiple turns. Finding relevant context in a conversation's history is challenging because of the complexity of natural language and the evolution of a user's information need. In this work, we present an extensive analysis of language, relevance, dependency of user utterances in a multi-turn information-seeking conversation. To this aim, we have annotated relevant utterances in the conversations released by the TREC CaST 2019 track. The annotation labels determine which of the previous utterances in a conversation can be used to improve the current one. Furthermore, we propose a neural utterance relevance model based on BERT fine-tuning, outperforming competitive baselines. We study and compare the performance of multiple retrieval models, utilizing different strategies to incorporate the user's context. The experimental results on both classification and retrieval tasks show that our proposed approach can effectively identify and incorporate the conversation context. We show that processing the current utterance using the predicted relevant utterance leads to a 38% relative improvement in terms of nDCG@20. Finally, to foster research in this area, we have released the dataset of the annotations.
Joint Geographical and Temporal Modeling based on Matrix Factorization for Point-of-Interest Recommendation
Jan 24, 2020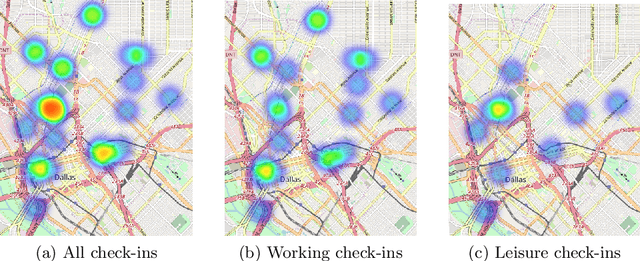
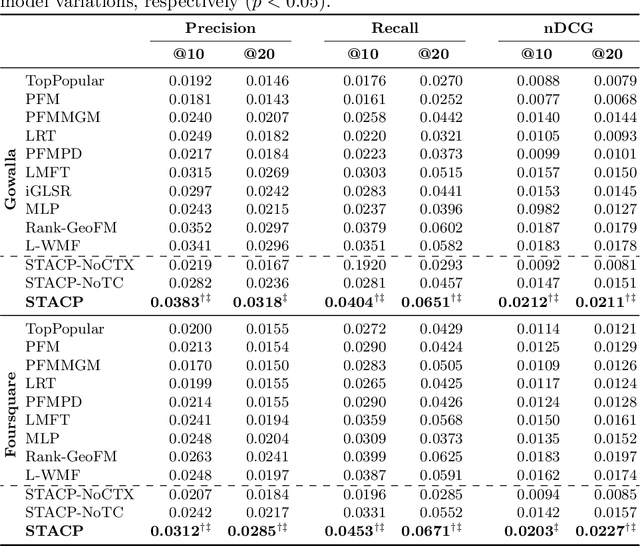
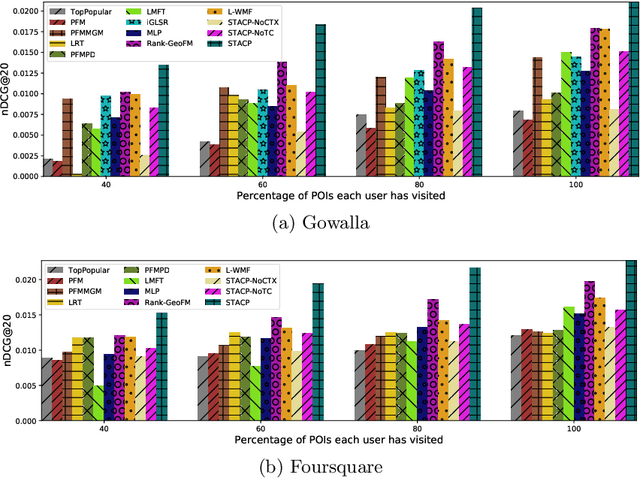
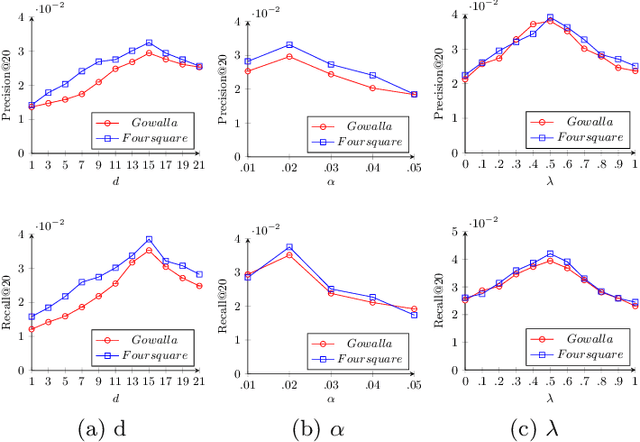
With the popularity of Location-based Social Networks, Point-of-Interest (POI) recommendation has become an important task, which learns the users' preferences and mobility patterns to recommend POIs. Previous studies show that incorporating contextual information such as geographical and temporal influences is necessary to improve POI recommendation by addressing the data sparsity problem. However, existing methods model the geographical influence based on the physical distance between POIs and users, while ignoring the temporal characteristics of such geographical influences. In this paper, we perform a study on the user mobility patterns where we find out that users' check-ins happen around several centers depending on their current temporal state. Next, we propose a spatio-temporal activity-centers algorithm to model users' behavior more accurately. Finally, we demonstrate the effectiveness of our proposed contextual model by incorporating it into the matrix factorization model under two different settings: i) static and ii) temporal. To show the effectiveness of our proposed method, which we refer to as STACP, we conduct experiments on two well-known real-world datasets acquired from Gowalla and Foursquare LBSNs. Experimental results show that the STACP model achieves a statistically significant performance improvement, compared to the state-of-the-art techniques. Also, we demonstrate the effectiveness of capturing geographical and temporal information for modeling users' activity centers and the importance of modeling them jointly.
A Joint Two-Phase Time-Sensitive Regularized Collaborative Ranking Model for Point of Interest Recommendation
Sep 16, 2019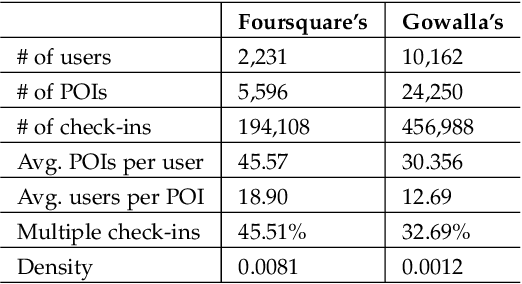
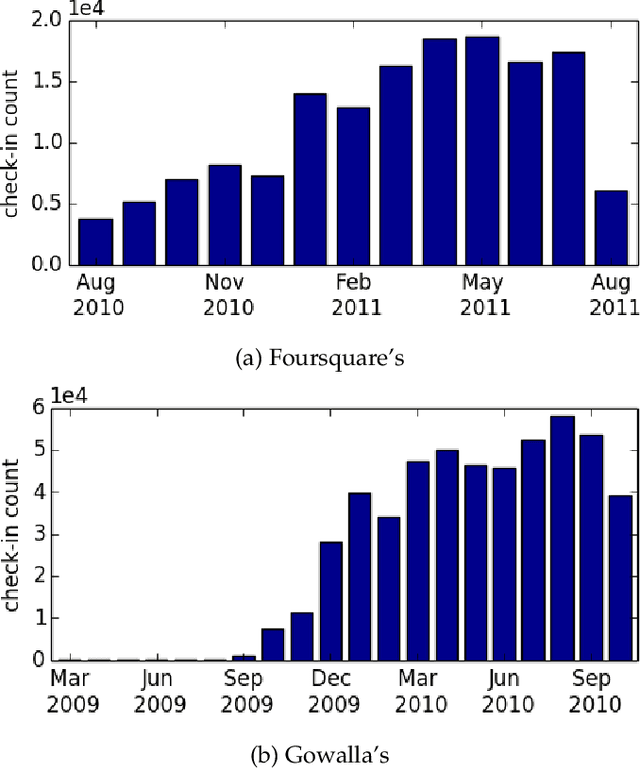
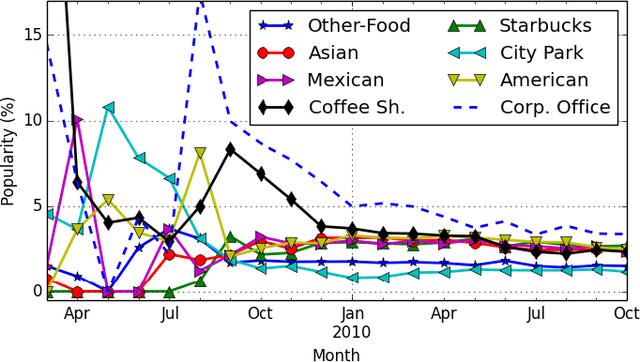
The popularity of location-based social networks (LBSNs) has led to a tremendous amount of user check-in data. Recommending points of interest (POIs) plays a key role in satisfying users' needs in LBSNs. While recent work has explored the idea of adopting collaborative ranking (CR) for recommendation, there have been few attempts to incorporate temporal information for POI recommendation using CR. In this article, we propose a two-phase CR algorithm that incorporates the geographical influence of POIs and is regularized based on the variance of POIs popularity and users' activities over time. The time-sensitive regularizer penalizes user and POIs that have been more time-sensitive in the past, helping the model to account for their long-term behavioral patterns while learning from user-POI interactions. Moreover, in the first phase, it attempts to rank visited POIs higher than the unvisited ones, and at the same time, apply the geographical influence. In the second phase, our algorithm tries to rank users' favorite POIs higher on the recommendation list. Both phases employ a collaborative learning strategy that enables the model to capture complex latent associations from two different perspectives. Experiments on real-world datasets show that our proposed time-sensitive collaborative ranking model beats state-of-the-art POI recommendation methods.
Asking Clarifying Questions in Open-Domain Information-Seeking Conversations
Jul 15, 2019
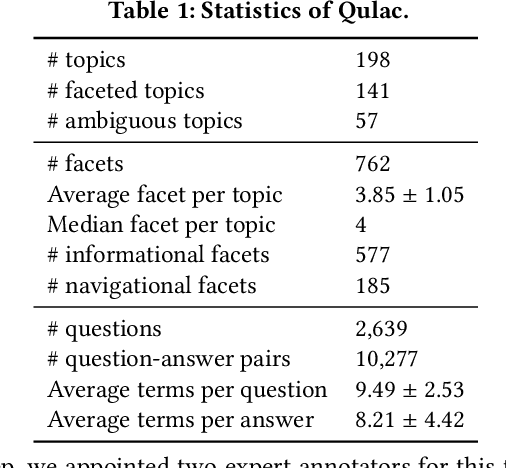
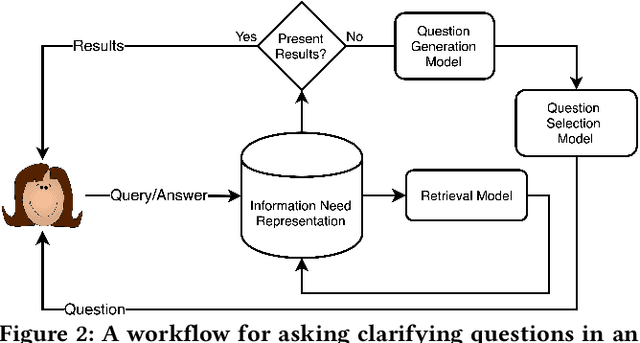
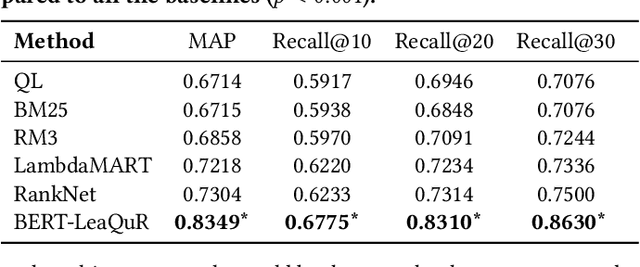
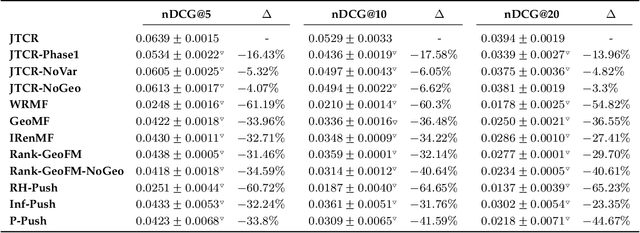
Users often fail to formulate their complex information needs in a single query. As a consequence, they may need to scan multiple result pages or reformulate their queries, which may be a frustrating experience. Alternatively, systems can improve user satisfaction by proactively asking questions of the users to clarify their information needs. Asking clarifying questions is especially important in conversational systems since they can only return a limited number of (often only one) result(s). In this paper, we formulate the task of asking clarifying questions in open-domain information-seeking conversational systems. To this end, we propose an offline evaluation methodology for the task and collect a dataset, called Qulac, through crowdsourcing. Our dataset is built on top of the TREC Web Track 2009-2012 data and consists of over 10K question-answer pairs for 198 TREC topics with 762 facets. Our experiments on an oracle model demonstrate that asking only one good question leads to over 170% retrieval performance improvement in terms of P@1, which clearly demonstrates the potential impact of the task. We further propose a retrieval framework consisting of three components: question retrieval, question selection, and document retrieval. In particular, our question selection model takes into account the original query and previous question-answer interactions while selecting the next question. Our model significantly outperforms competitive baselines. To foster research in this area, we have made Qulac publicly available.