 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Universal Normal Embedding
Mar 23, 2026Generative models and vision encoders have largely advanced on separate tracks, optimized for different goals and grounded in different mathematical principles. Yet, they share a fundamental property: latent space Gaussianity. Generative models map Gaussian noise to images, while encoders map images to semantic embeddings whose coordinates empirically behave as Gaussian. We hypothesize that both are views of a shared latent source, the Universal Normal Embedding (UNE): an approximately Gaussian latent space from which encoder embeddings and DDIM-inverted noise arise as noisy linear projections. To test our hypothesis, we introduce NoiseZoo, a dataset of per-image latents comprising DDIM-inverted diffusion noise and matching encoder representations (CLIP, DINO). On CelebA, linear probes in both spaces yield strong, aligned attribute predictions, indicating that generative noise encodes meaningful semantics along linear directions. These directions further enable faithful, controllable edits (e.g., smile, gender, age) without architectural changes, where simple orthogonalization mitigates spurious entanglements. Taken together, our results provide empirical support for the UNE hypothesis and reveal a shared Gaussian-like latent geometry that concretely links encoding and generation. Code and data are available https://rbetser.github.io/UNE/
InfoNCE Induces Gaussian Distribution
Feb 27, 2026Contrastive learning has become a cornerstone of modern representation learning, allowing training with massive unlabeled data for both task-specific and general (foundation) models. A prototypical loss in contrastive training is InfoNCE and its variants. In this work, we show that the InfoNCE objective induces Gaussian structure in representations that emerge from contrastive training. We establish this result in two complementary regimes. First, we show that under certain alignment and concentration assumptions, projections of the high-dimensional representation asymptotically approach a multivariate Gaussian distribution. Next, under less strict assumptions, we show that adding a small asymptotically vanishing regularization term that promotes low feature norm and high feature entropy leads to similar asymptotic results. We support our analysis with experiments on synthetic and CIFAR-10 datasets across multiple encoder architectures and sizes, demonstrating consistent Gaussian behavior. This perspective provides a principled explanation for commonly observed Gaussianity in contrastive representations. The resulting Gaussian model enables principled analytical treatment of learned representations and is expected to support a wide range of applications in contrastive learning.
A Pseudo-Inverse for Nonlinear Operators
Nov 21, 2021


The Moore-Penrose inverse is widely used in physics, statistics and various fields of engineering. Among other characteristics, it captures well the notion of inversion of linear operators in the case of overcomplete data. In data science, nonlinear operators are extensively used. In this paper we define and characterize the fundamental properties of a pseudo-inverse for nonlinear operators. The concept is defined broadly. First for general sets, and then a refinement for normed spaces. Our pseudo-inverse for normed spaces yields the Moore-Penrose inverse when the operator is a matrix. We present conditions for existence and uniqueness of a pseudo-inverse and establish theoretical results investigating its properties, such as continuity, its value for operator compositions and projection operators, and others. Analytic expressions are given for the pseudo-inverse of some well-known, non-invertible, nonlinear operators, such as hard- or soft-thresholding and ReLU. Finally, we analyze a neural layer and discuss relations to wavelet thresholding and to regularized loss minimization.
Experts with Lower-Bounded Loss Feedback: A Unifying Framework
Dec 17, 2020The most prominent feedback models for the best expert problem are the full information and bandit models. In this work we consider a simple feedback model that generalizes both, where on every round, in addition to a bandit feedback, the adversary provides a lower bound on the loss of each expert. Such lower bounds may be obtained in various scenarios, for instance, in stock trading or in assessing errors of certain measurement devices. For this model we prove optimal regret bounds (up to logarithmic factors) for modified versions of Exp3, generalizing algorithms and bounds both for the bandit and the full-information settings. Our second-order unified regret analysis simulates a two-step loss update and highlights three Hessian or Hessian-like expressions, which map to the full-information regret, bandit regret, and a hybrid of both. Our results intersect with those for bandits with graph-structured feedback, in that both settings can accommodate feedback from an arbitrary subset of experts on each round. However, our model also accommodates partial feedback at the single-expert level, by allowing non-trivial lower bounds on each loss.
Adaptive LiDAR Sampling and Depth Completion using Ensemble Variance
Jul 27, 2020
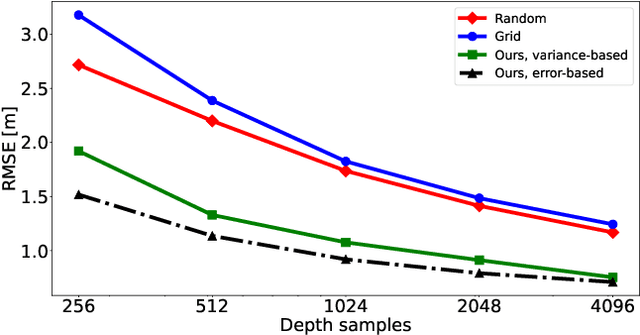

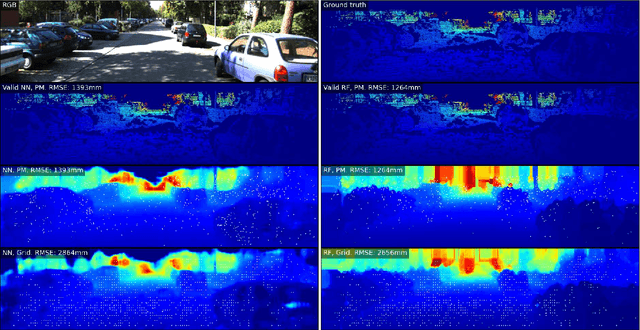
This work considers the problem of depth completion, with or without image data, where an algorithm may measure the depth of a prescribed limited number of pixels. The algorithmic challenge is to choose pixel positions strategically and dynamically to maximally reduce overall depth estimation error. This setting is realized in daytime or nighttime depth completion for autonomous vehicles with a programmable LiDAR. Our method uses an ensemble of predictors to define a sampling probability over pixels. This probability is proportional to the variance of the predictions of ensemble members, thus highlighting pixels that are difficult to predict. By additionally proceeding in several prediction phases, we effectively reduce redundant sampling of similar pixels. Our ensemble-based method may be implemented using any depth-completion learning algorithm, such as a state-of-the-art neural network, treated as a black box. In particular, we also present a simple and effective Random Forest-based algorithm, and similarly use its internal ensemble in our design. We conduct experiments on the KITTI dataset, using the neural network algorithm of Ma et al. and our Random Forest based learner for implementing our method. The accuracy of both implementations exceeds the state of the art. Compared with a random or grid sampling pattern, our method allows a reduction by a factor of 4-10 in the number of measurements required to attain the same accuracy.