 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperposition as Data Augmentation using LSTM and HMM in Small Training Sets
Oct 24, 2019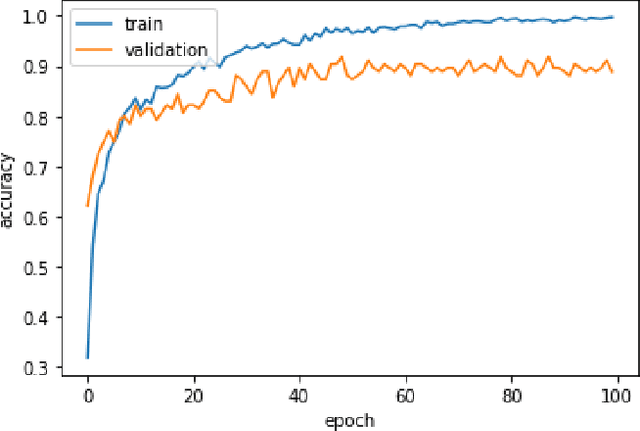
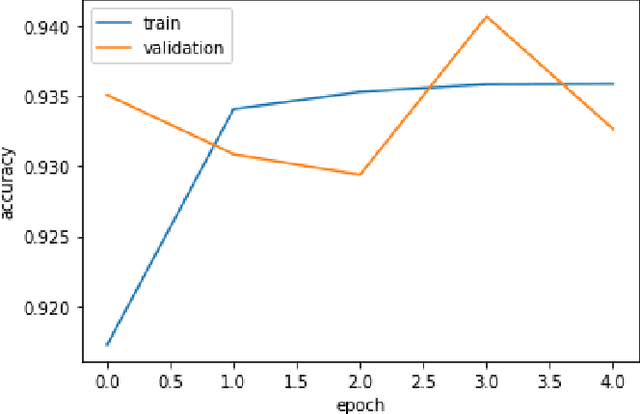
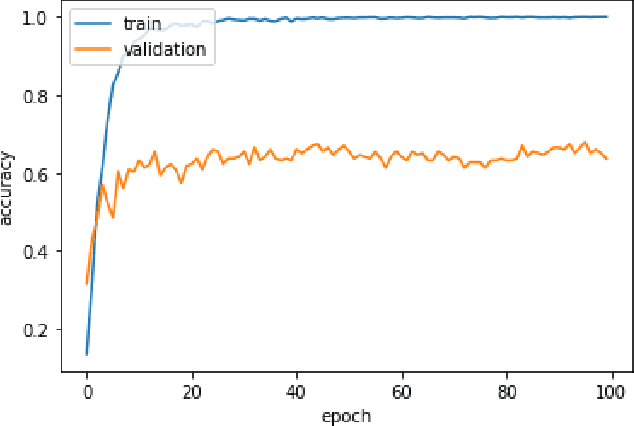
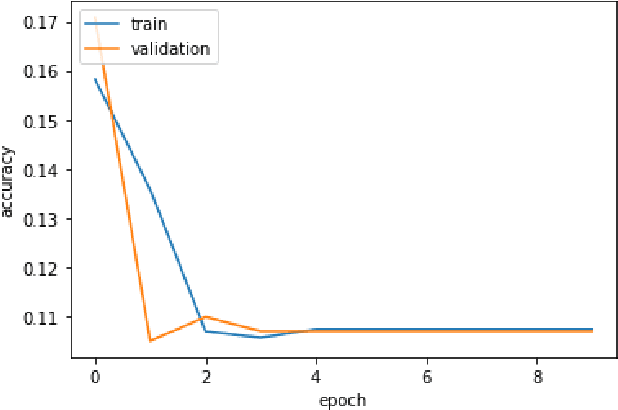
Considering audio and image data as having quantum nature (data are represented by density matrices), we achieved better results on training architectures such as 3-layer stacked LSTM and HMM by mixing training samples using superposition augmentation and compared with plain default training and mix-up augmentation. This augmentation technique originates from the mix-up approach but provides more solid theoretical reasoning based on quantum properties. We achieved 3% improvement (from 68% to 71%) by using 38% lesser number of training samples in Russian audio-digits recognition task and 7,16% better accuracy than mix-up augmentation by training only 500 samples using HMM on the same task. Also, we achieved 1.1% better accuracy than mix-up on first 900 samples in MNIST using 3-layer stacked LSTM.