 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNotes on Deep Learning Theory
Dec 10, 2020These are the notes for the lectures that I was giving during Fall 2020 at the Moscow Institute of Physics and Technology (MIPT) and at the Yandex School of Data Analysis (YSDA). The notes cover some aspects of initialization, loss landscape, generalization, and a neural tangent kernel theory. While many other topics (e.g. expressivity, a mean-field theory, a double descent phenomenon) are missing in the current version, we plan to add them in future revisions.
Dynamically Stable Infinite-Width Limits of Neural Classifiers
Jun 11, 2020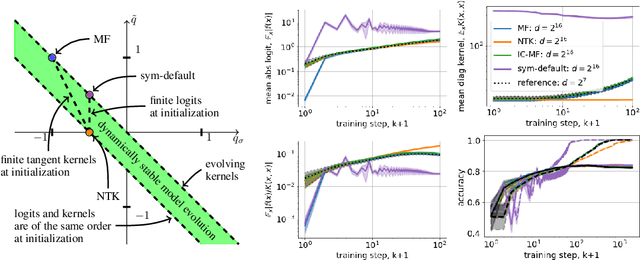
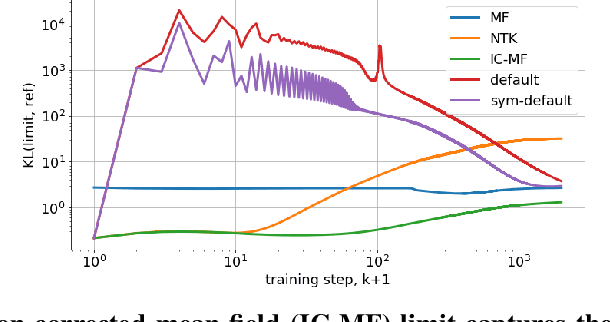
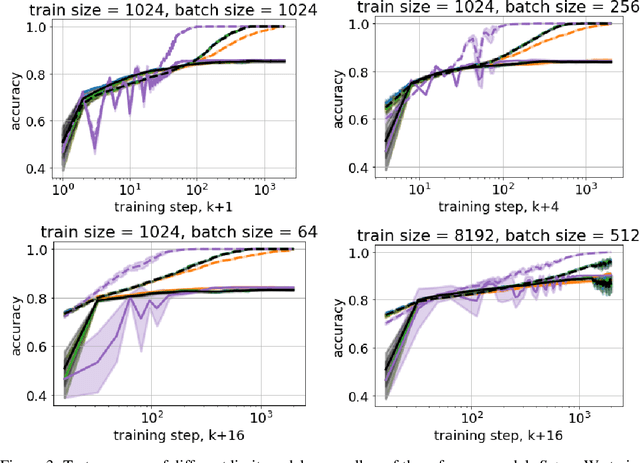
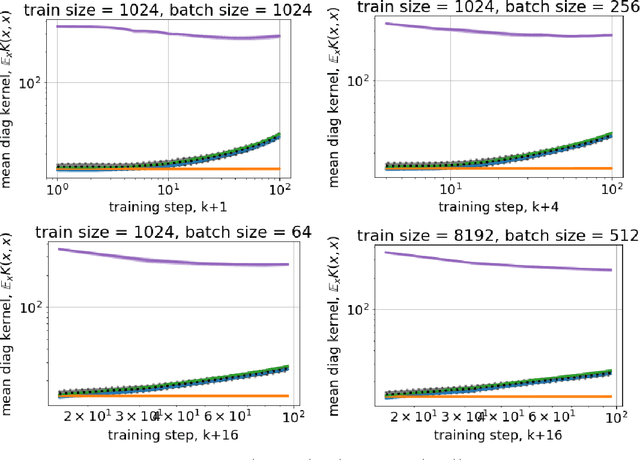
Recent research has been focused on two different approaches to studying neural networks training in the limit of infinite width (1) a mean-field (MF) and (2) a constant neural tangent kernel (NTK) approximations. These two approaches have different scaling of hyperparameters with a width of a network layer and as a result different infinite width limit models. We propose a general framework to study how the limit behavior of neural models depends on the scaling of hyperparameters with a network width. Our framework allows us to derive scaling for existing MF and NTK limits, as well as an uncountable number of other scalings that lead to a dynamically stable limit behavior of corresponding models. However, only a finite number of distinct limit models are induced by these scalings. Each distinct limit model corresponds to a unique combination of such properties as boundedness of logits and tangent kernels at initialization or stationarity of tangent kernels. Existing MF and NTK limit models, as well as one novel limit model, satisfy most of the properties demonstrated by finite-width models. We also propose a novel initialization-corrected mean-field limit that satisfies all properties noted above, and its corresponding model is a simple modification for a finite-width model. Source code to reproduce all the reported results is available on GitHub.
Towards a General Theory of Infinite-Width Limits of Neural Classifiers
Mar 12, 2020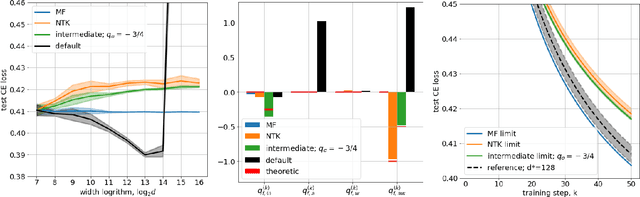
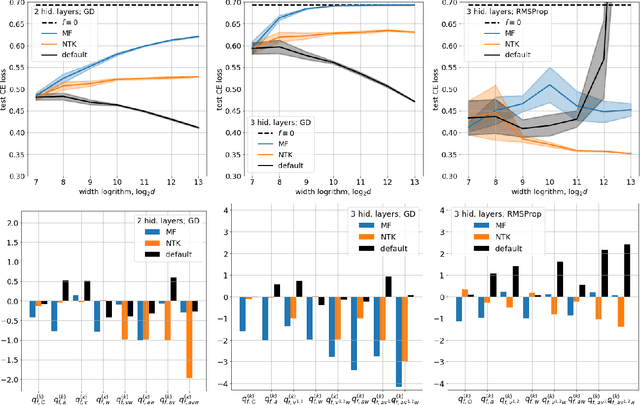
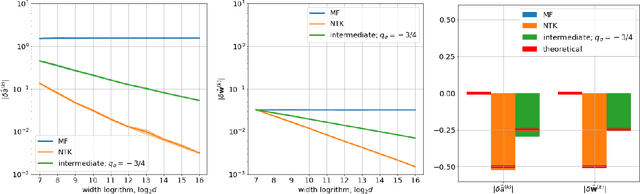
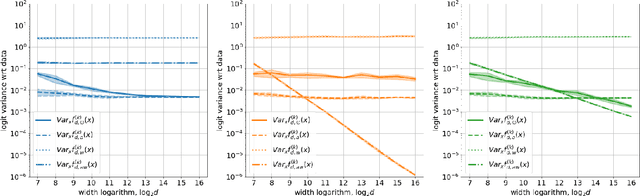
Obtaining theoretical guarantees for neural networks training appears to be a hard problem in a general case. Recent research has been focused on studying this problem in the limit of infinite width and two different theories have been developed: mean-field (MF) and kernel limit theories. We propose a general framework that provides a link between these seemingly distinct theories. Our framework out of the box gives rise to a discrete-time MF limit which was not previously explored in the literature. We prove a convergence theorem for it and show that it provides a more reasonable approximation for finite-width nets compared to NTK limit if learning rates are not very small. Also, our analysis suggests that all infinite-width limits of a network with a single hidden layer are covered by either mean-field limit theory or kernel limit theory. We show that for networks with more than two hidden layers RMSProp training has a non-trivial MF limit, but GD training does not have one. Overall, our framework demonstrates that both MF and NTK limits have considerable limitations in approximating finite-sized neural nets, indicating the need for designing more accurate infinite-width approximations for them. Source code to reproduce all the reported results is available on GitHub.