 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Reward Machines: A Study in Partially Observable Reinforcement Learning
Dec 17, 2021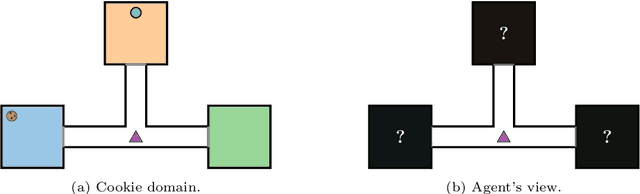
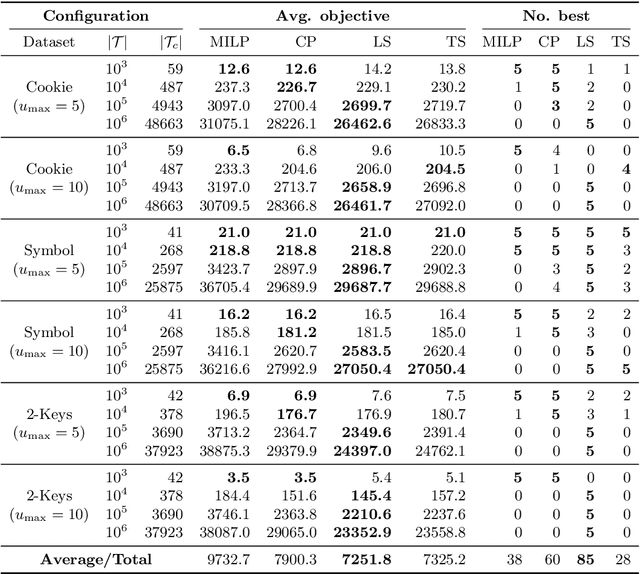
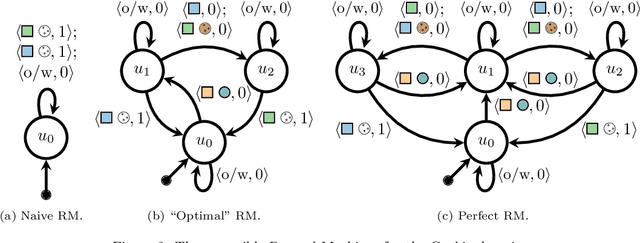
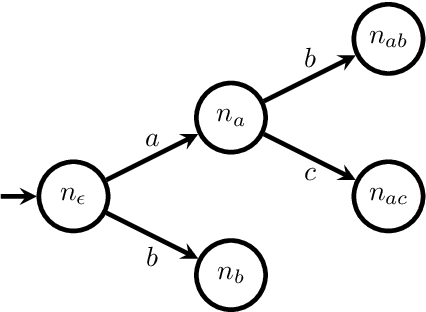
Reinforcement learning (RL) is a central problem in artificial intelligence. This problem consists of defining artificial agents that can learn optimal behaviour by interacting with an environment -- where the optimal behaviour is defined with respect to a reward signal that the agent seeks to maximize. Reward machines (RMs) provide a structured, automata-based representation of a reward function that enables an RL agent to decompose an RL problem into structured subproblems that can be efficiently learned via off-policy learning. Here we show that RMs can be learned from experience, instead of being specified by the user, and that the resulting problem decomposition can be used to effectively solve partially observable RL problems. We pose the task of learning RMs as a discrete optimization problem where the objective is to find an RM that decomposes the problem into a set of subproblems such that the combination of their optimal memoryless policies is an optimal policy for the original problem. We show the effectiveness of this approach on three partially observable domains, where it significantly outperforms A3C, PPO, and ACER, and discuss its advantages, limitations, and broader potential.