 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA parametric distribution for exact post-selection inference with data carving
May 21, 2023Post-selection inference (PoSI) is a statistical technique for obtaining valid confidence intervals and p-values when hypothesis generation and testing use the same source of data. PoSI can be used on a range of popular algorithms including the Lasso. Data carving is a variant of PoSI in which a portion of held out data is combined with the hypothesis generating data at inference time. While data carving has attractive theoretical and empirical properties, existing approaches rely on computationally expensive MCMC methods to carry out inference. This paper's key contribution is to show that pivotal quantities can be constructed for the data carving procedure based on a known parametric distribution. Specifically, when the selection event is characterized by a set of polyhedral constraints on a Gaussian response, data carving will follow the sum of a normal and a truncated normal (SNTN), which is a variant of the truncated bivariate normal distribution. The main impact of this insight is that obtaining exact inference for data carving can be made computationally trivial, since the CDF of the SNTN distribution can be found using the CDF of a standard bivariate normal. A python package sntn has been released to further facilitate the adoption of data carving with PoSI.
SurvSet: An open-source time-to-event dataset repository
Mar 07, 2022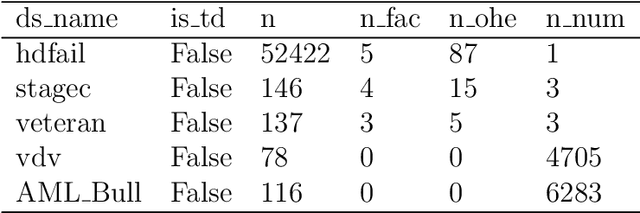
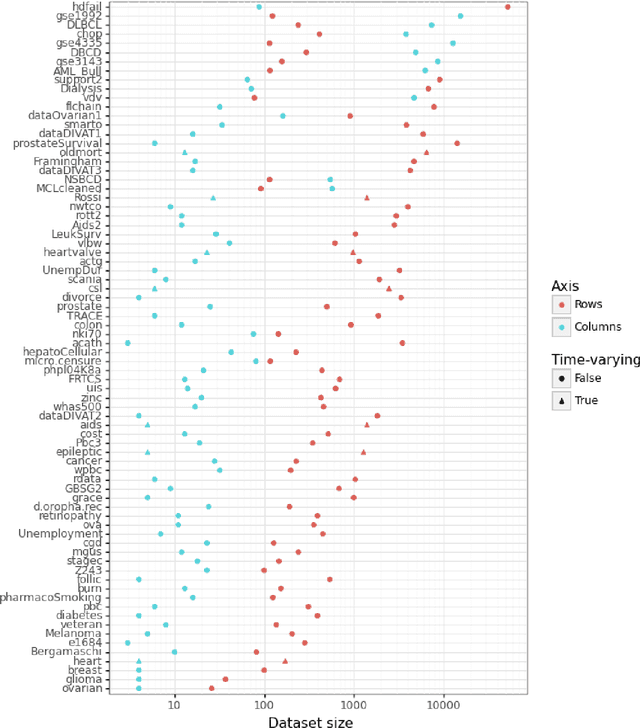
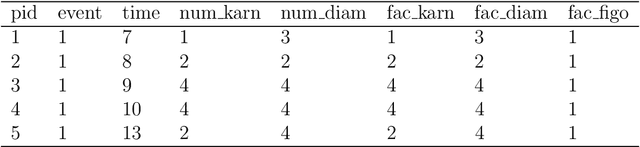
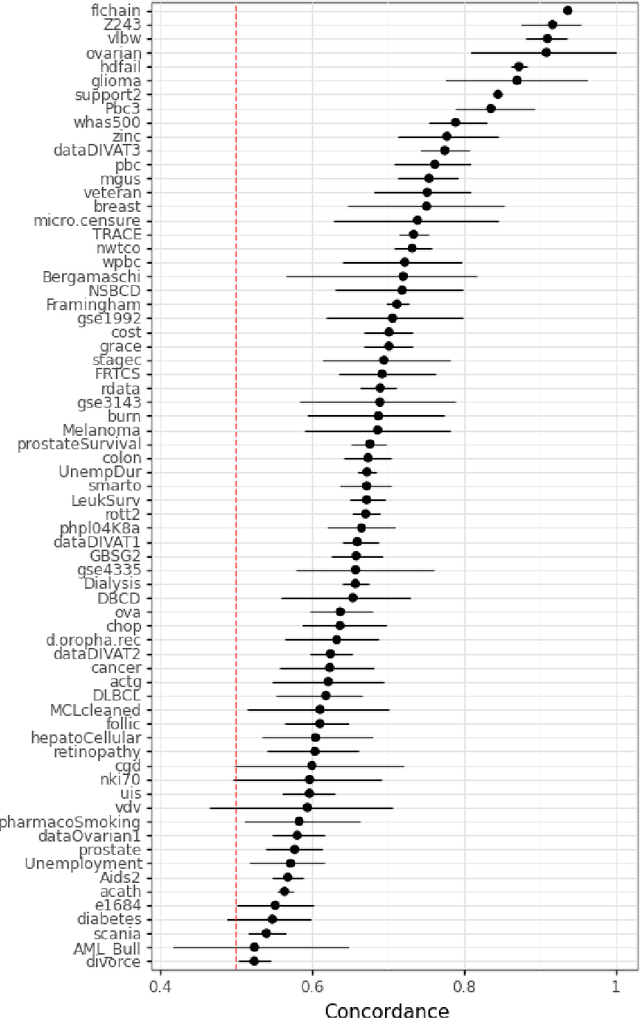
Time-to-event (T2E) analysis is a branch of statistics that models the duration of time it takes for an event to occur. Such events can include outcomes like death, unemployment, or product failure. Most modern machine learning (ML) algorithms, like decision trees and kernel methods, are supported for T2E modelling with data science software (python and R). To complement these developments, SurvSet is the first open-source T2E dataset repository designed for a rapid benchmarking of ML algorithms and statistical methods. The data in SurvSet have been consistently formatted so that a single preprocessing method will work for all datasets. SurvSet currently has 76 datasets which vary in dimensionality, time dependency, and background (the majority of which come from biomedicine). SurvSet is available on PyPI and can be installed with pip install SurvSet. R users can download the data directly from the corresponding git repository.
Forecasting Emergency Department Capacity Constraints for COVID Isolation Beds
Nov 09, 2020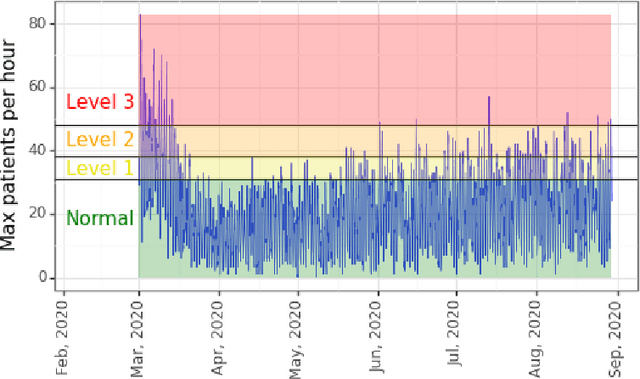
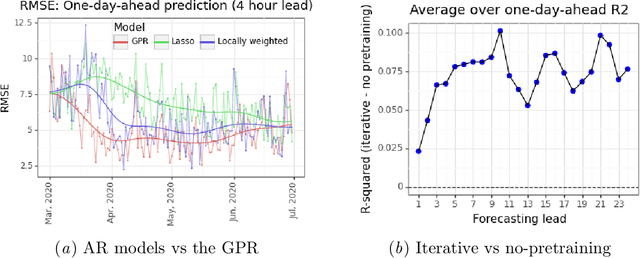
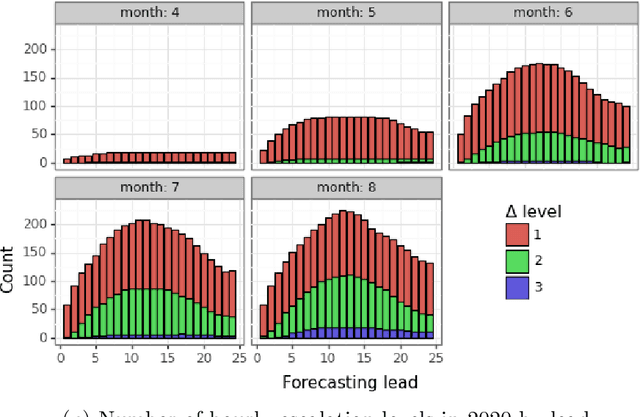
Predicting patient volumes in a hospital setting is a well-studied application of time series forecasting. Existing tools usually make forecasts at the daily or weekly level to assist in planning for staffing requirements. Prompted by new COVID-related capacity constraints placed on our pediatric hospital's emergency department, we developed an hourly forecasting tool to make predictions over a 24 hour window. These forecasts would give our hospital sufficient time to be able to martial resources towards expanding capacity and augmenting staff (e.g. transforming wards or bringing in physicians on call). Using Gaussian Process Regressions (GPRs), we obtain strong performance for both point predictions (average R-squared: 82%) as well as classification accuracy when predicting the ordinal tiers of our hospital's capacity (average precision/recall: 82%/74%). Compared to traditional regression approaches, GPRs not only obtain consistently higher performance, but are also robust to the dataset shifts that have occurred throughout 2020. Hospital stakeholders are encouraged by the strength of our results, and we are currently working on moving our tool to a real-time setting with the goal of augmenting the capabilities of our healthcare workers.
The False Positive Control Lasso
Mar 29, 2019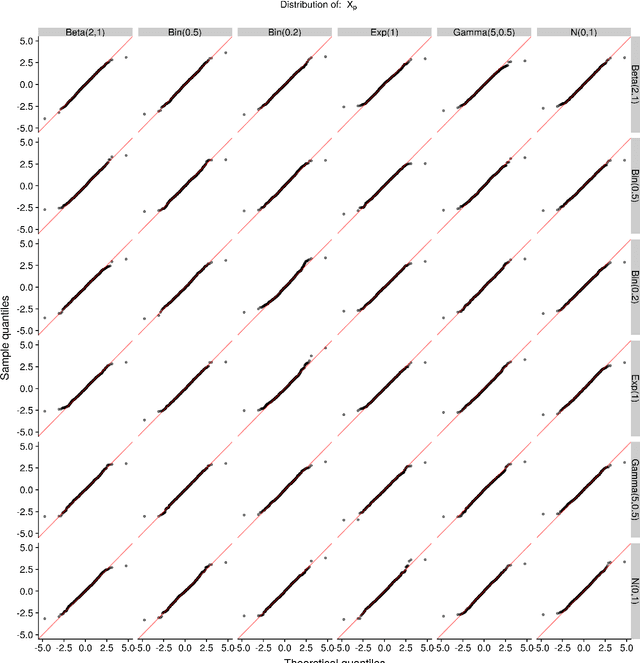
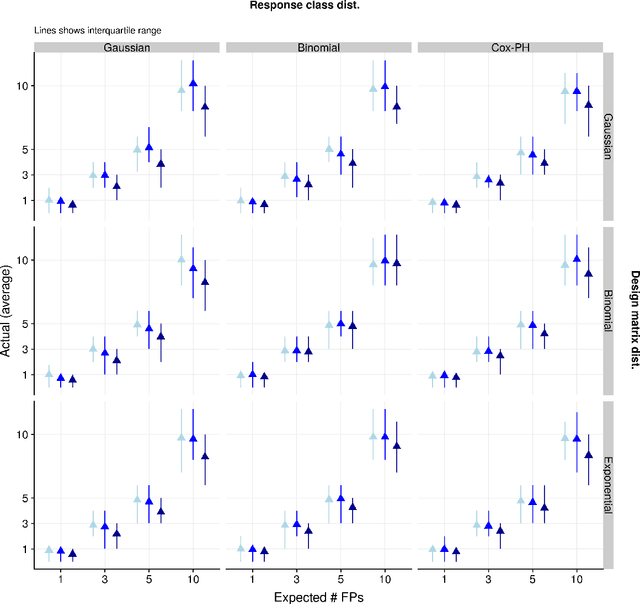
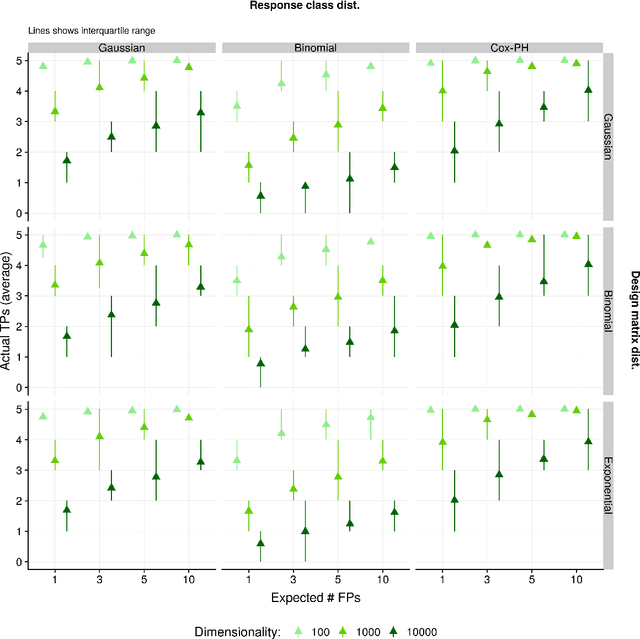
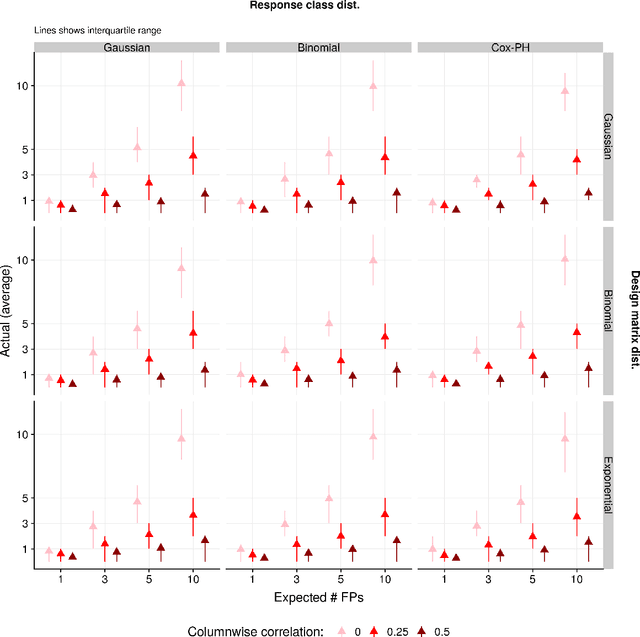
In high dimensional settings where a small number of regressors are expected to be important, the Lasso estimator can be used to obtain a sparse solution vector with the expectation that most of the non-zero coefficients are associated with true signals. While several approaches have been developed to control the inclusion of false predictors with the Lasso, these approaches are limited by relying on asymptotic theory, having to empirically estimate terms based on theoretical quantities, assuming a continuous response class with Gaussian noise and design matrices, or high computation costs. In this paper we show how: (1) an existing model (the SQRT-Lasso) can be recast as a method of controlling the number of expected false positives, (2) how a similar estimator can used for all other generalized linear model classes, and (3) this approach can be fit with existing fast Lasso optimization solvers. Our justification for false positive control using randomly weighted self-normalized sum theory is to our knowledge novel. Moreover, our estimator's properties hold in finite samples up to some approximation error which we find in practical settings to be negligible under a strict mutual incoherence condition.