 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiPUFFIN: A Multimodal Domain-Constrained Foundation Model for Molecular Property Prediction of Small Molecules
Mar 01, 2026Predicting physicochemical properties across chemical space is vital for chemical engineering, drug discovery, and materials science. Current molecular foundation models lack thermodynamic consistency, while domain-informed approaches are limited to single properties and small datasets. We introduce MultiPUFFIN, a domain-constrained multimodal foundation model addressing both limitations simultaneously. MultiPUFFIN features: (i) an encoder fusing SMILES, graphs, and 3D geometries via gated cross-modal attention, alongside experimental condition and descriptor encoders; (ii) prediction heads embedding established correlations (e.g., Wagner, Andrade, van't Hoff, and Shomate equations) as inductive biases to ensure thermodynamic consistency; and (iii) a two-stage multi-task training strategy.Extending prior frameworks, MultiPUFFIN predicts nine thermophysical properties simultaneously. It is trained on a multi-source dataset of 37,968 unique molecules (40,904 rows). With roughly 35 million parameters, MultiPUFFIN achieves a mean $R^2 = 0.716$ on a challenging scaffold-split test set of 8,877 molecules. Compared to ChemBERTa-2 (pre-trained on 77 million molecules), MultiPUFFIN outperforms the fine-tuned baseline across all nine properties despite using 2000x fewer training molecules. Advantages are strikingly apparent for temperature-dependent properties, where ChemBERTa-2 lacks the architectural capacity to incorporate thermodynamic conditions.These results demonstrate that multimodal encoding and domain-informed biases substantially reduce data and compute requirements compared to brute-force pre-training. Furthermore, MultiPUFFIN handles missing modalities and recovers meaningful thermodynamic parameters without explicit supervision. Systematic ablation studies confirm the property-specific benefits of these domain-informed prediction heads.
Brazilian Court Documents Clustered by Similarity Together Using Natural Language Processing Approaches with Transformers
Apr 21, 2022



Recent advances in Artificial intelligence (AI) have leveraged promising results in solving complex problems in the area of Natural Language Processing (NLP), being an important tool to help in the expeditious resolution of judicial proceedings in the legal area. In this context, this work targets the problem of detecting the degree of similarity between judicial documents that can be achieved in the inference group, by applying six NLP techniques based on transformers, namely BERT, GPT-2 and RoBERTa pre-trained in the Brazilian Portuguese language and the same specialized using 210,000 legal proceedings. Documents were pre-processed and had their content transformed into a vector representation using these NLP techniques. Unsupervised learning was used to cluster the lawsuits, calculating the quality of the model based on the cosine of the distance between the elements of the group to its centroid. We noticed that models based on transformers present better performance when compared to previous research, highlighting the RoBERTa model specialized in the Brazilian Portuguese language, making it possible to advance in the current state of the art in the area of NLP applied to the legal sector.
T4PdM: a Deep Neural Network based on the Transformer Architecture for Fault Diagnosis of Rotating Machinery
Apr 07, 2022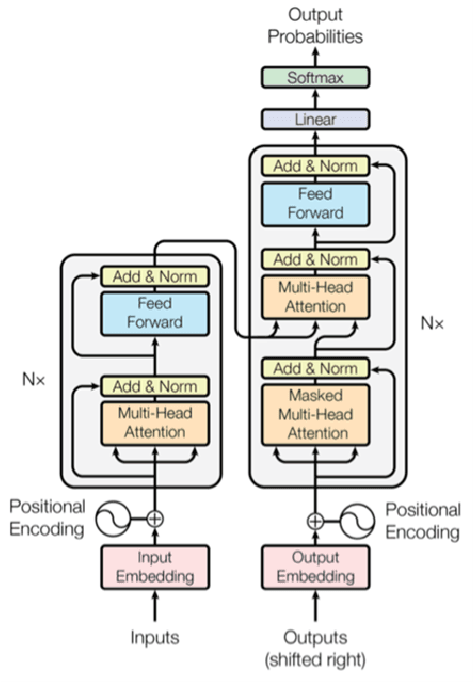

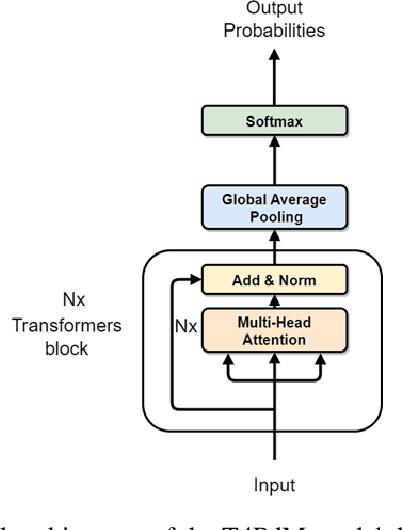
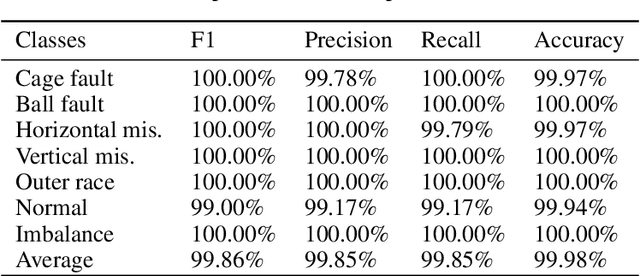
Deep learning and big data algorithms have become widely used in industrial applications to optimize several tasks in many complex systems. Particularly, deep learning model for diagnosing and prognosing machinery health has leveraged predictive maintenance (PdM) to be more accurate and reliable in decision making, in this way avoiding unnecessary interventions, machinery accidents, and environment catastrophes. Recently, Transformer Neural Networks have gained notoriety and have been increasingly the favorite choice for Natural Language Processing (NLP) tasks. Thus, given their recent major achievements in NLP, this paper proposes the development of an automatic fault classifier model for predictive maintenance based on a modified version of the Transformer architecture, namely T4PdM, to identify multiple types of faults in rotating machinery. Experimental results are developed and presented for the MaFaulDa and CWRU databases. T4PdM was able to achieve an overall accuracy of 99.98% and 98% for both datasets, respectively. In addition, the performance of the proposed model is compared to other previously published works. It has demonstrated the superiority of the model in detecting and classifying faults in rotating industrial machinery. Therefore, the proposed Transformer-based model can improve the performance of machinery fault analysis and diagnostic processes and leverage companies to a new era of the Industry 4.0. In addition, this methodology can be adapted to any other task of time series classification.
Machine learning models and facial regions videos for estimating heart rate: a review on Patents, Datasets and Literature
Feb 17, 2022



Estimating heart rate is important for monitoring users in various situations. Estimates based on facial videos are increasingly being researched because it makes it possible to monitor cardiac information in a non-invasive way and because the devices are simpler, requiring only cameras that capture the user's face. From these videos of the user's face, machine learning is able to estimate heart rate. This study investigates the benefits and challenges of using machine learning models to estimate heart rate from facial videos, through patents, datasets, and articles review. We searched Derwent Innovation, IEEE Xplore, Scopus, and Web of Science knowledge bases and identified 7 patent filings, 11 datasets, and 20 articles on heart rate, photoplethysmography, or electrocardiogram data. In terms of patents, we note the advantages of inventions related to heart rate estimation, as described by the authors. In terms of datasets, we discovered that most of them are for academic purposes and with different signs and annotations that allow coverage for subjects other than heartbeat estimation. In terms of articles, we discovered techniques, such as extracting regions of interest for heart rate reading and using Video Magnification for small motion extraction, and models such as EVM-CNN and VGG-16, that extract the observed individual's heart rate, the best regions of interest for signal extraction and ways to process them.
Bias and unfairness in machine learning models: a systematic literature review
Feb 16, 2022



One of the difficulties of artificial intelligence is to ensure that model decisions are fair and free of bias. In research, datasets, metrics, techniques, and tools are applied to detect and mitigate algorithmic unfairness and bias. This study aims to examine existing knowledge on bias and unfairness in Machine Learning models, identifying mitigation methods, fairness metrics, and supporting tools. A Systematic Literature Review found 40 eligible articles published between 2017 and 2022 in the Scopus, IEEE Xplore, Web of Science, and Google Scholar knowledge bases. The results show numerous bias and unfairness detection and mitigation approaches for ML technologies, with clearly defined metrics in the literature, and varied metrics can be highlighted. We recommend further research to define the techniques and metrics that should be employed in each case to standardize and ensure the impartiality of the machine learning model, thus, allowing the most appropriate metric to detect bias and unfairness in a given context.