 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Methods for Combining Linguistic Indicators to Classify Verbs
Sep 13, 1997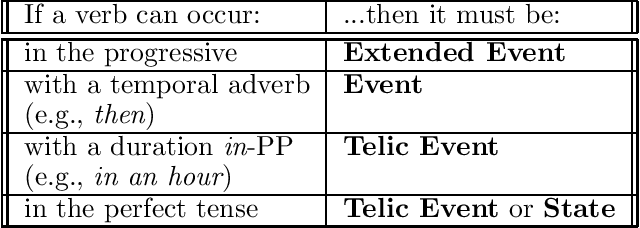
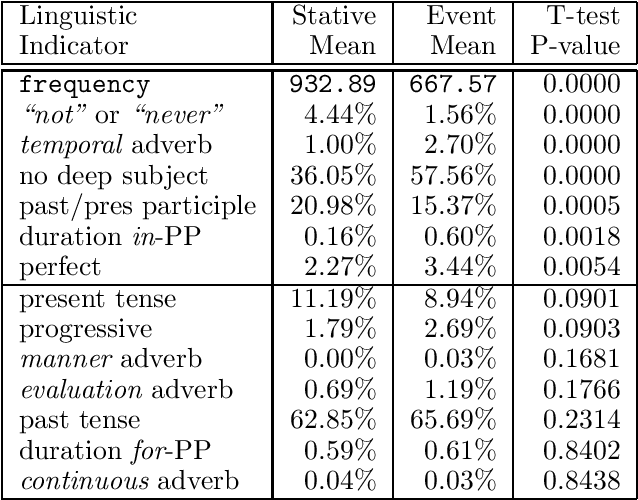
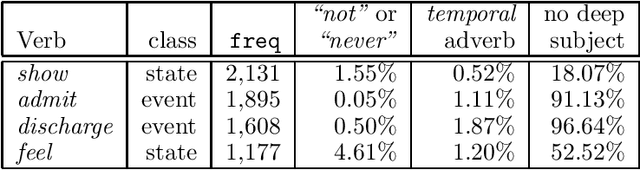
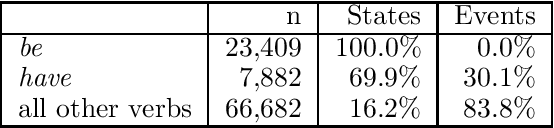
Fourteen linguistically-motivated numerical indicators are evaluated for their ability to categorize verbs as either states or events. The values for each indicator are computed automatically across a corpus of text. To improve classification performance, machine learning techniques are employed to combine multiple indicators. Three machine learning methods are compared for this task: decision tree induction, a genetic algorithm, and log-linear regression.
Gathering Statistics to Aspectually Classify Sentences with a Genetic Algorithm
Oct 21, 1996This paper presents a method for large corpus analysis to semantically classify an entire clause. In particular, we use cooccurrence statistics among similar clauses to determine the aspectual class of an input clause. The process examines linguistic features of clauses that are relevant to aspectual classification. A genetic algorithm determines what combinations of linguistic features to use for this task.
Emergent Linguistic Rules from Inducing Decision Trees: Disambiguating Discourse Clue Words
Aug 13, 1994We apply decision tree induction to the problem of discourse clue word sense disambiguation with a genetic algorithm. The automatic partitioning of the training set which is intrinsic to decision tree induction gives rise to linguistically viable rules.