 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Multidimensional Patient Modeling using Auxiliary Confidence Labels
Jul 28, 2015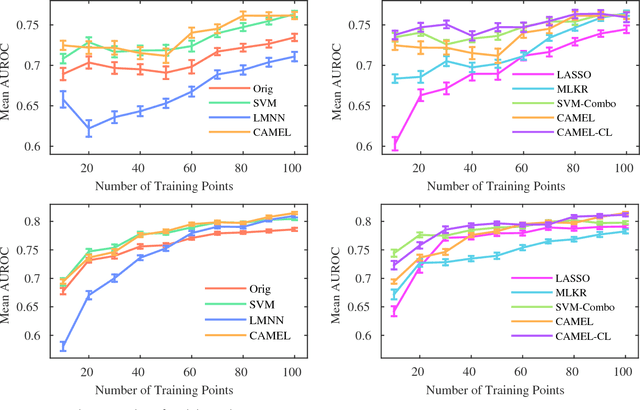
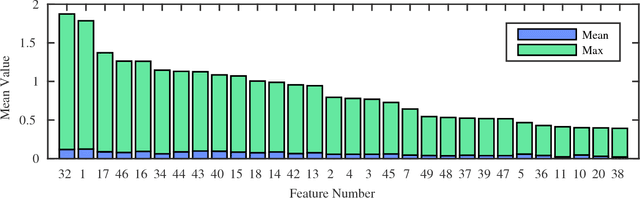
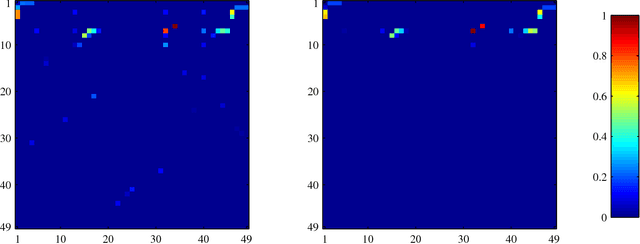

In this work, we focus on the problem of learning a classification model that performs inference on patient Electronic Health Records (EHRs). Often, a large amount of costly expert supervision is required to learn such a model. To reduce this cost, we obtain confidence labels that indicate how sure an expert is in the class labels she provides. If meaningful confidence information can be incorporated into a learning method, fewer patient instances may need to be labeled to learn an accurate model. In addition, while accuracy of predictions is important for any inference model, a model of patients must be interpretable so that clinicians can understand how the model is making decisions. To these ends, we develop a novel metric learning method called Confidence bAsed MEtric Learning (CAMEL) that supports inclusion of confidence labels, but also emphasizes interpretability in three ways. First, our method induces sparsity, thus producing simple models that use only a few features from patient EHRs. Second, CAMEL naturally produces confidence scores that can be taken into consideration when clinicians make treatment decisions. Third, the metrics learned by CAMEL induce multidimensional spaces where each dimension represents a different "factor" that clinicians can use to assess patients. In our experimental evaluation, we show on a real-world clinical data set that our CAMEL methods are able to learn models that are as or more accurate as other methods that use the same supervision. Furthermore, we show that when CAMEL uses confidence scores it is able to learn models as or more accurate as others we tested while using only 10% of the training instances. Finally, we perform qualitative assessments on the metrics learned by CAMEL and show that they identify and clearly articulate important factors in how the model performs inference.
Efficient Online Relative Comparison Kernel Learning
Jan 12, 2015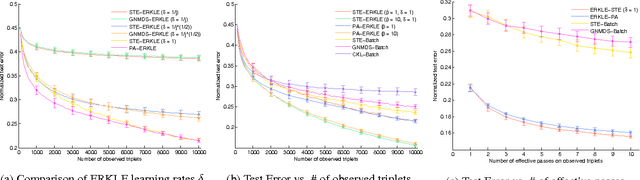
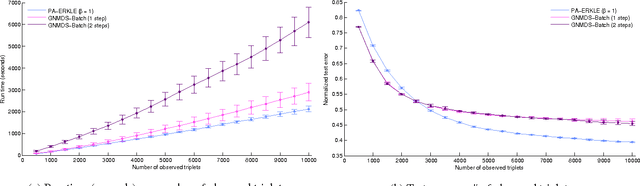
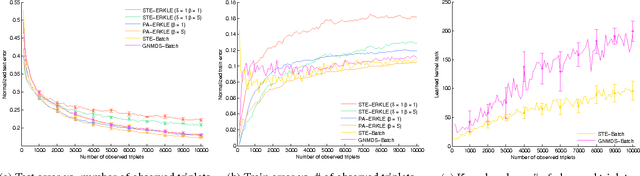
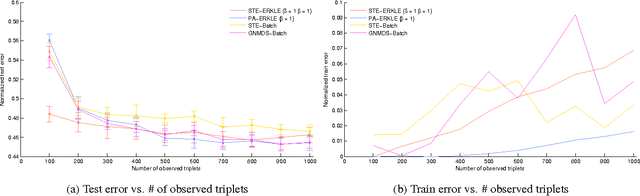
Learning a kernel matrix from relative comparison human feedback is an important problem with applications in collaborative filtering, object retrieval, and search. For learning a kernel over a large number of objects, existing methods face significant scalability issues inhibiting the application of these methods to settings where a kernel is learned in an online and timely fashion. In this paper we propose a novel framework called Efficient online Relative comparison Kernel LEarning (ERKLE), for efficiently learning the similarity of a large set of objects in an online manner. We learn a kernel from relative comparisons via stochastic gradient descent, one query response at a time, by taking advantage of the sparse and low-rank properties of the gradient to efficiently restrict the kernel to lie in the space of positive semidefinite matrices. In addition, we derive a passive-aggressive online update for minimally satisfying new relative comparisons as to not disrupt the influence of previously obtained comparisons. Experimentally, we demonstrate a considerable improvement in speed while obtaining improved or comparable accuracy compared to current methods in the online learning setting.
Relative Comparison Kernel Learning with Auxiliary Kernels
Apr 15, 2014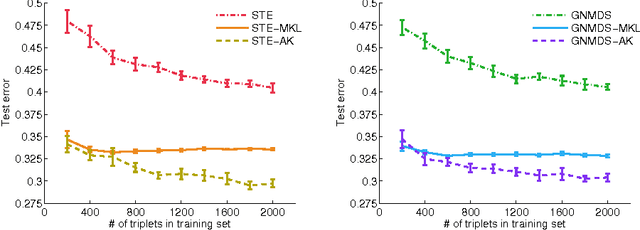
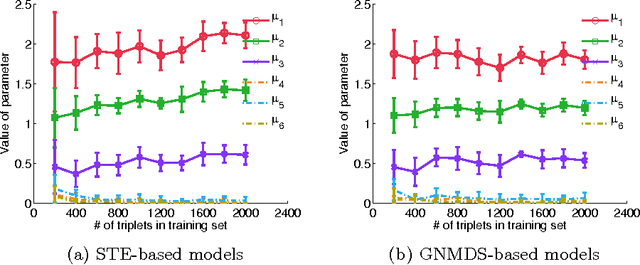
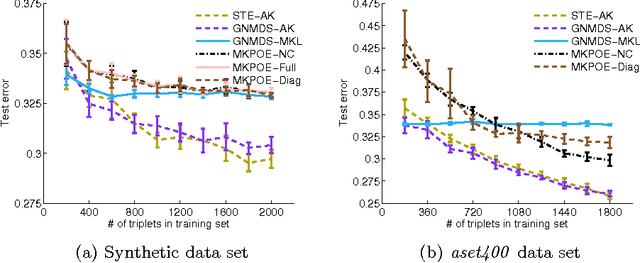
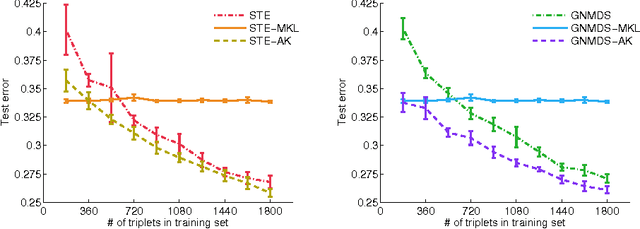
In this work we consider the problem of learning a positive semidefinite kernel matrix from relative comparisons of the form: "object A is more similar to object B than it is to C", where comparisons are given by humans. Existing solutions to this problem assume many comparisons are provided to learn a high quality kernel. However, this can be considered unrealistic for many real-world tasks since relative assessments require human input, which is often costly or difficult to obtain. Because of this, only a limited number of these comparisons may be provided. In this work, we explore methods for aiding the process of learning a kernel with the help of auxiliary kernels built from more easily extractable information regarding the relationships among objects. We propose a new kernel learning approach in which the target kernel is defined as a conic combination of auxiliary kernels and a kernel whose elements are learned directly. We formulate a convex optimization to solve for this target kernel that adds only minor overhead to methods that use no auxiliary information. Empirical results show that in the presence of few training relative comparisons, our method can learn kernels that generalize to more out-of-sample comparisons than methods that do not utilize auxiliary information, as well as similar methods that learn metrics over objects.