 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Performance Increment Strategy for Semantic Segmentation of Low-Resolution Images from Damaged Roads
Nov 25, 2024



Autonomous driving needs good roads, but 85% of Brazilian roads have damages that deep learning models may not regard as most semantic segmentation datasets for autonomous driving are high-resolution images of well-maintained urban roads. A representative dataset for emerging countries consists of low-resolution images of poorly maintained roads and includes labels of damage classes; in this scenario, three challenges arise: objects with few pixels, objects with undefined shapes, and highly underrepresented classes. To tackle these challenges, this work proposes the Performance Increment Strategy for Semantic Segmentation (PISSS) as a methodology of 14 training experiments to boost performance. With PISSS, we reached state-of-the-art results of 79.8 and 68.8 mIoU on the Road Traversing Knowledge (RTK) and Technik Autonomer Systeme 500 (TAS500) test sets, respectively. Furthermore, we also offer an analysis of DeepLabV3+ pitfalls for small object segmentation.
Face Reconstruction with Variational Autoencoder and Face Masks
Dec 03, 2021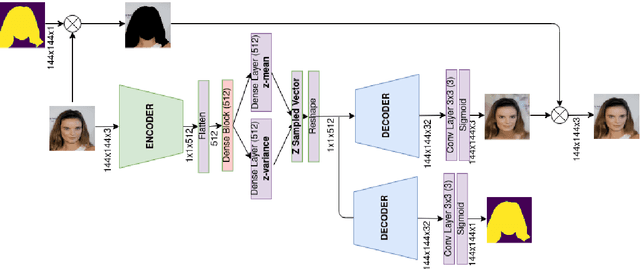

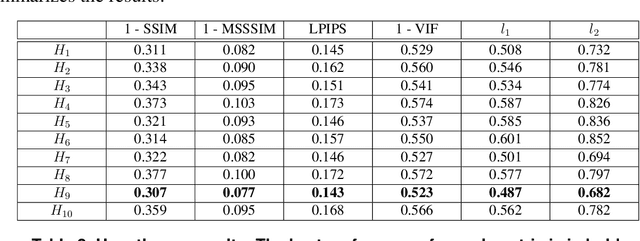
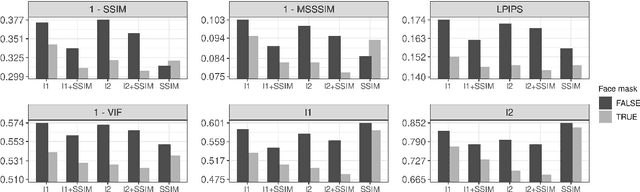
Variational AutoEncoders (VAE) employ deep learning models to learn a continuous latent z-space that is subjacent to a high-dimensional observed dataset. With that, many tasks are made possible, including face reconstruction and face synthesis. In this work, we investigated how face masks can help the training of VAEs for face reconstruction, by restricting the learning to the pixels selected by the face mask. An evaluation of the proposal using the celebA dataset shows that the reconstructed images are enhanced with the face masks, especially when SSIM loss is used either with l1 or l2 loss functions. We noticed that the inclusion of a decoder for face mask prediction in the architecture affected the performance for l1 or l2 loss functions, while this was not the case for the SSIM loss. Besides, SSIM perceptual loss yielded the crispest samples between all hypotheses tested, although it shifts the original color of the image, making the usage of the l1 or l2 losses together with SSIM helpful to solve this issue.
Proximal Policy Optimization with Continuous Bounded Action Space via the Beta Distribution
Nov 03, 2021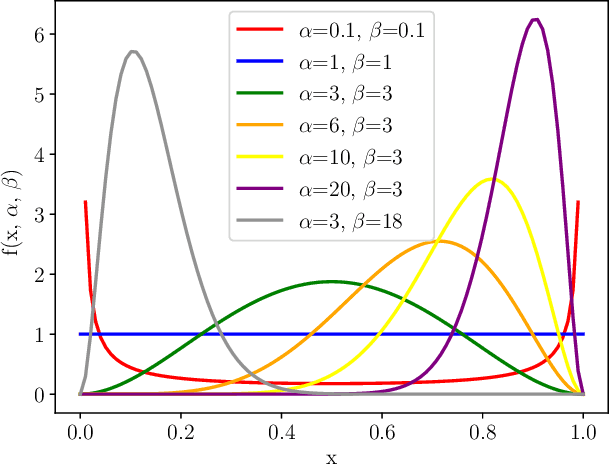

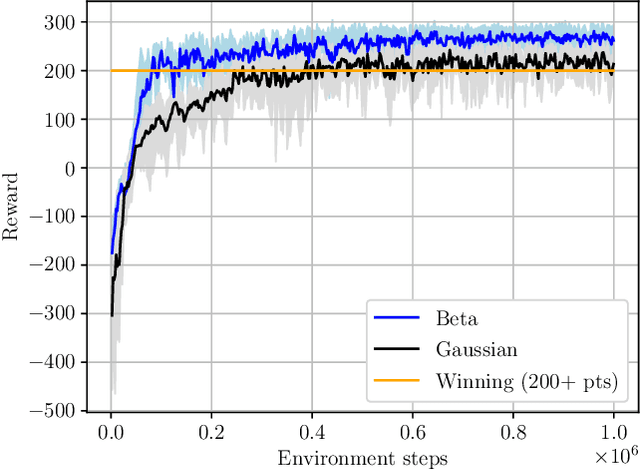
Reinforcement learning methods for continuous control tasks have evolved in recent years generating a family of policy gradient methods that rely primarily on a Gaussian distribution for modeling a stochastic policy. However, the Gaussian distribution has an infinite support, whereas real world applications usually have a bounded action space. This dissonance causes an estimation bias that can be eliminated if the Beta distribution is used for the policy instead, as it presents a finite support. In this work, we investigate how this Beta policy performs when it is trained by the Proximal Policy Optimization (PPO) algorithm on two continuous control tasks from OpenAI gym. For both tasks, the Beta policy is superior to the Gaussian policy in terms of agent's final expected reward, also showing more stability and faster convergence of the training process. For the CarRacing environment with high-dimensional image input, the agent's success rate was improved by 63% over the Gaussian policy.
Benford's law: what does it say on adversarial images?
Feb 09, 2021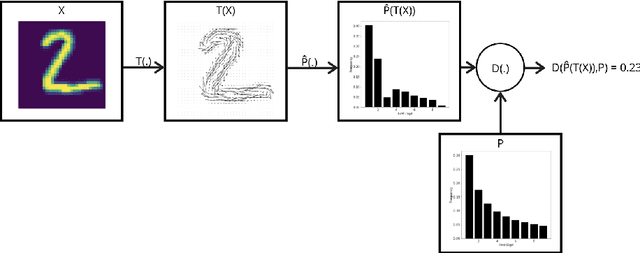
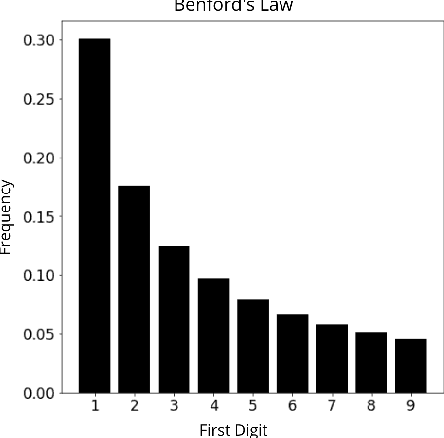

Convolutional neural networks (CNNs) are fragile to small perturbations in the input images. These networks are thus prone to malicious attacks that perturb the inputs to force a misclassification. Such slightly manipulated images aimed at deceiving the classifier are known as adversarial images. In this work, we investigate statistical differences between natural images and adversarial ones. More precisely, we show that employing a proper image transformation and for a class of adversarial attacks, the distribution of the leading digit of the pixels in adversarial images deviates from Benford's law. The stronger the attack, the more distant the resulting distribution is from Benford's law. Our analysis provides a detailed investigation of this new approach that can serve as a basis for alternative adversarial example detection methods that do not need to modify the original CNN classifier neither work on the raw high-dimensional pixels as features to defend against attacks.