 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypernyms under Siege: Linguistically-motivated Artillery for Hypernymy Detection
Jan 08, 2017
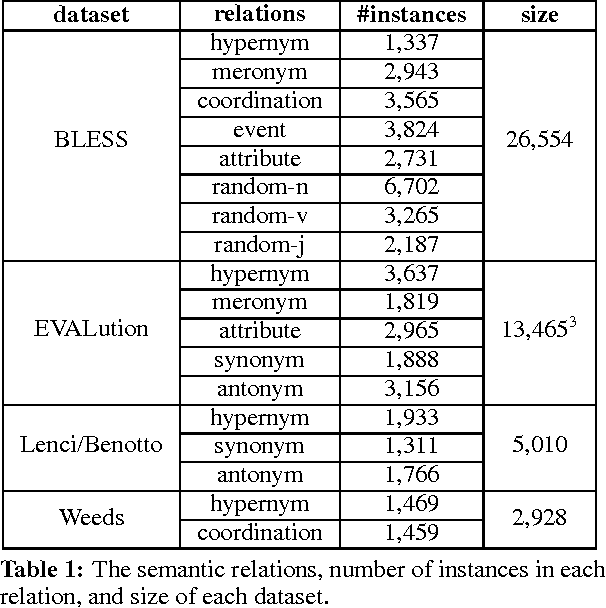
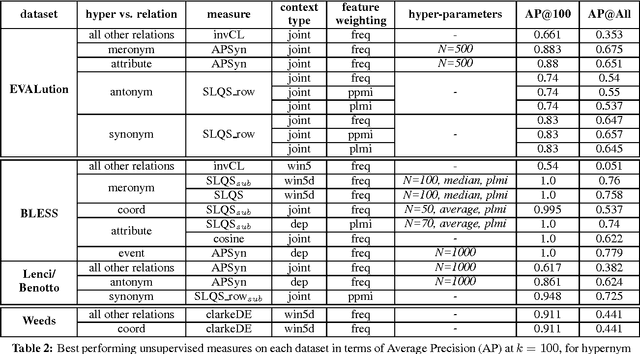
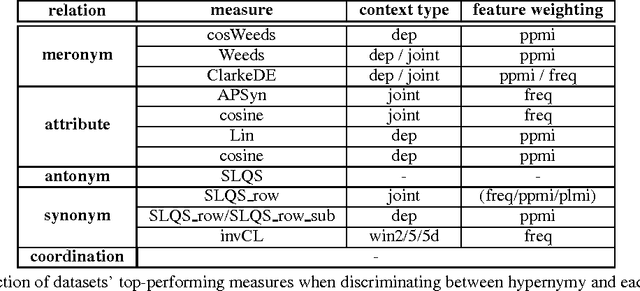
The fundamental role of hypernymy in NLP has motivated the development of many methods for the automatic identification of this relation, most of which rely on word distribution. We investigate an extensive number of such unsupervised measures, using several distributional semantic models that differ by context type and feature weighting. We analyze the performance of the different methods based on their linguistic motivation. Comparison to the state-of-the-art supervised methods shows that while supervised methods generally outperform the unsupervised ones, the former are sensitive to the distribution of training instances, hurting their reliability. Being based on general linguistic hypotheses and independent from training data, unsupervised measures are more robust, and therefore are still useful artillery for hypernymy detection.
CogALex-V Shared Task: ROOT18
Nov 03, 2016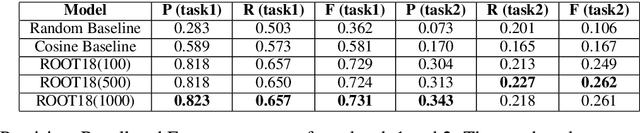
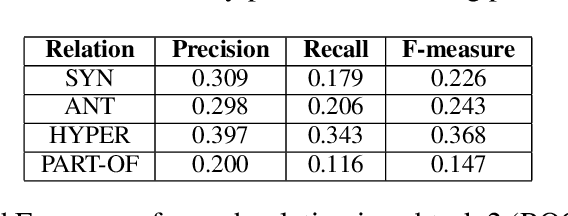
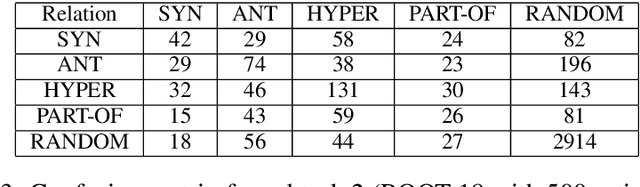
In this paper, we describe ROOT 18, a classifier using the scores of several unsupervised distributional measures as features to discriminate between semantically related and unrelated words, and then to classify the related pairs according to their semantic relation (i.e. synonymy, antonymy, hypernymy, part-whole meronymy). Our classifier participated in the CogALex-V Shared Task, showing a solid performance on the first subtask, but a poor performance on the second subtask. The low scores reported on the second subtask suggest that distributional measures are not sufficient to discriminate between multiple semantic relations at once.
Representing Verbs with Rich Contexts: an Evaluation on Verb Similarity
Oct 05, 2016
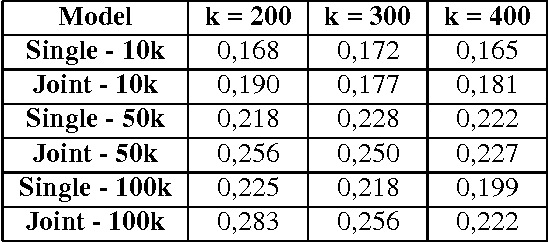
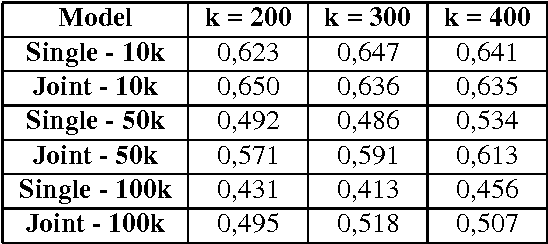
Several studies on sentence processing suggest that the mental lexicon keeps track of the mutual expectations between words. Current DSMs, however, represent context words as separate features, thereby loosing important information for word expectations, such as word interrelations. In this paper, we present a DSM that addresses this issue by defining verb contexts as joint syntactic dependencies. We test our representation in a verb similarity task on two datasets, showing that joint contexts achieve performances comparable to single dependencies or even better. Moreover, they are able to overcome the data sparsity problem of joint feature spaces, in spite of the limited size of our training corpus.
Testing APSyn against Vector Cosine on Similarity Estimation
Oct 05, 2016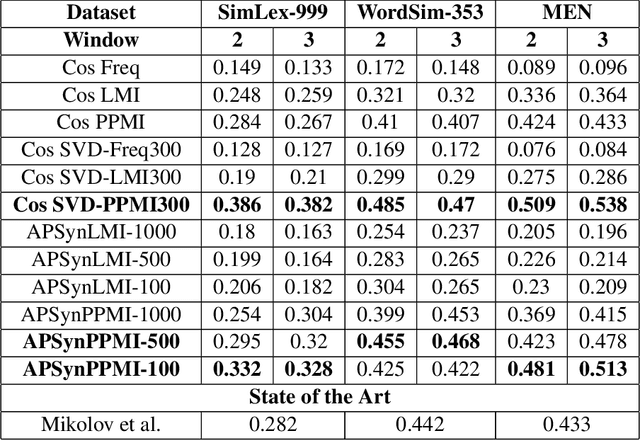
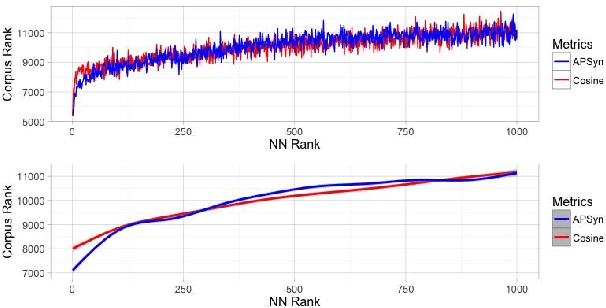
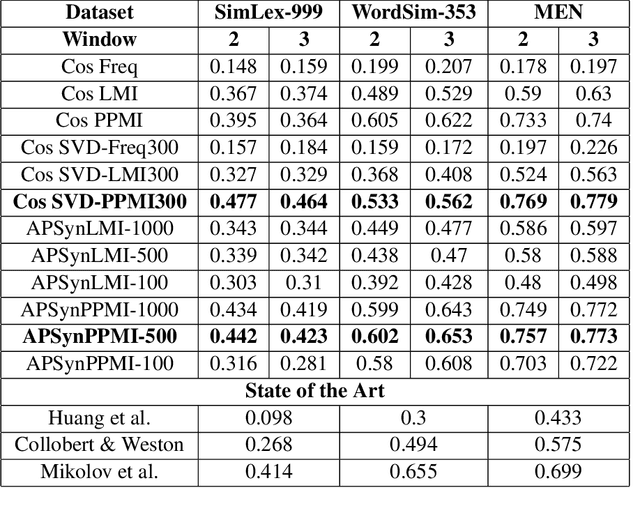
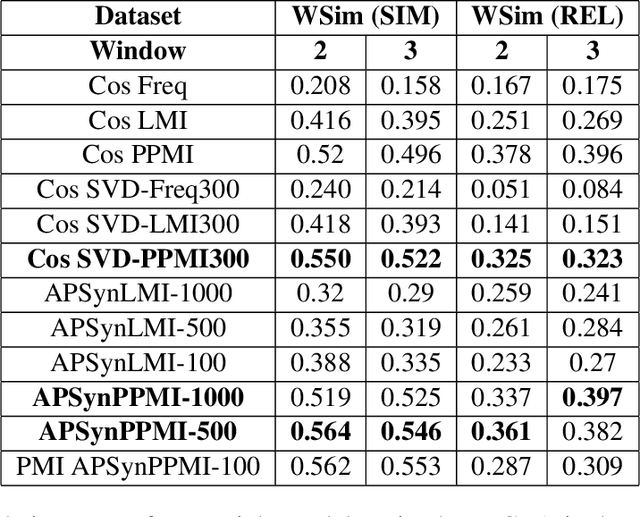
In Distributional Semantic Models (DSMs), Vector Cosine is widely used to estimate similarity between word vectors, although this measure was noticed to suffer from several shortcomings. The recent literature has proposed other methods which attempt to mitigate such biases. In this paper, we intend to investigate APSyn, a measure that computes the extent of the intersection between the most associated contexts of two target words, weighting it by context relevance. We evaluated this metric in a similarity estimation task on several popular test sets, and our results show that APSyn is in fact highly competitive, even with respect to the results reported in the literature for word embeddings. On top of it, APSyn addresses some of the weaknesses of Vector Cosine, performing well also on genuine similarity estimation.
Unsupervised Measure of Word Similarity: How to Outperform Co-occurrence and Vector Cosine in VSMs
Mar 30, 2016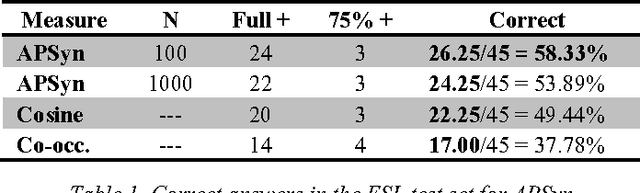
In this paper, we claim that vector cosine, which is generally considered among the most efficient unsupervised measures for identifying word similarity in Vector Space Models, can be outperformed by an unsupervised measure that calculates the extent of the intersection among the most mutually dependent contexts of the target words. To prove it, we describe and evaluate APSyn, a variant of the Average Precision that, without any optimization, outperforms the vector cosine and the co-occurrence on the standard ESL test set, with an improvement ranging between +9.00% and +17.98%, depending on the number of chosen top contexts.
ROOT13: Spotting Hypernyms, Co-Hyponyms and Randoms
Mar 29, 2016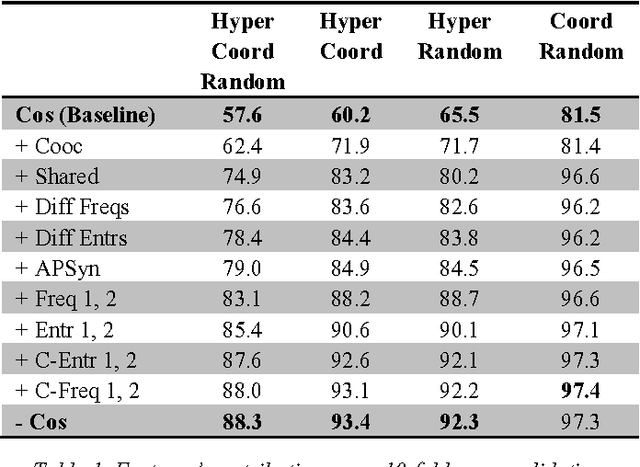
In this paper, we describe ROOT13, a supervised system for the classification of hypernyms, co-hyponyms and random words. The system relies on a Random Forest algorithm and 13 unsupervised corpus-based features. We evaluate it with a 10-fold cross validation on 9,600 pairs, equally distributed among the three classes and involving several Parts-Of-Speech (i.e. adjectives, nouns and verbs). When all the classes are present, ROOT13 achieves an F1 score of 88.3%, against a baseline of 57.6% (vector cosine). When the classification is binary, ROOT13 achieves the following results: hypernyms-co-hyponyms (93.4% vs. 60.2%), hypernymsrandom (92.3% vs. 65.5%) and co-hyponyms-random (97.3% vs. 81.5%). Our results are competitive with stateof-the-art models.
Nine Features in a Random Forest to Learn Taxonomical Semantic Relations
Mar 29, 2016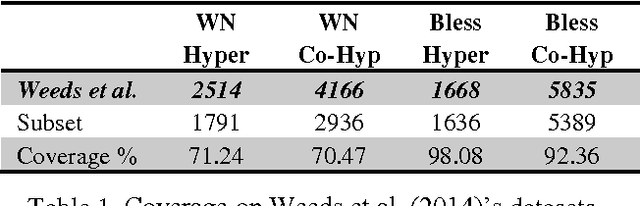
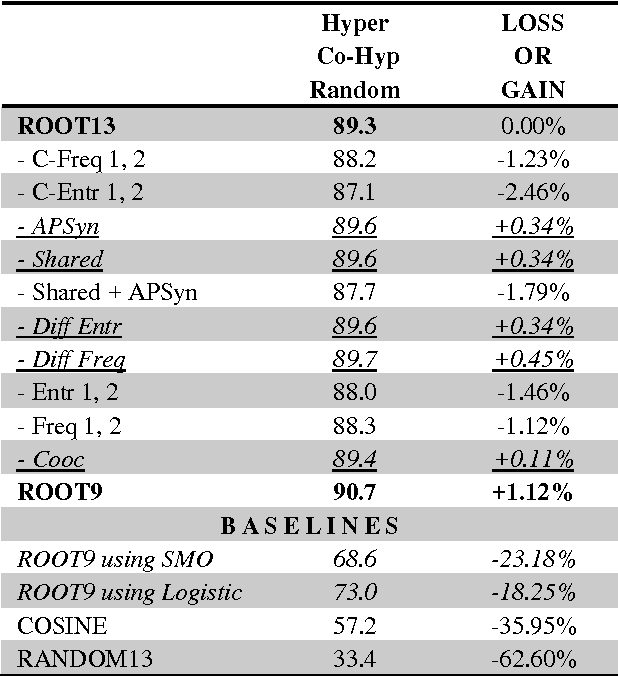
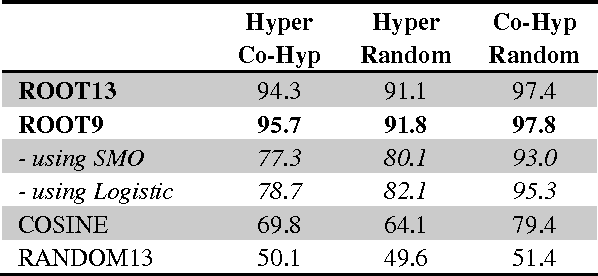
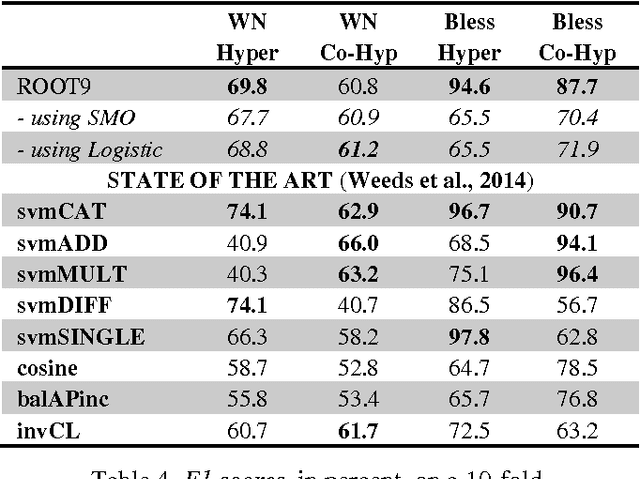
ROOT9 is a supervised system for the classification of hypernyms, co-hyponyms and random words that is derived from the already introduced ROOT13 (Santus et al., 2016). It relies on a Random Forest algorithm and nine unsupervised corpus-based features. We evaluate it with a 10-fold cross validation on 9,600 pairs, equally distributed among the three classes and involving several Parts-Of-Speech (i.e. adjectives, nouns and verbs). When all the classes are present, ROOT9 achieves an F1 score of 90.7%, against a baseline of 57.2% (vector cosine). When the classification is binary, ROOT9 achieves the following results against the baseline: hypernyms-co-hyponyms 95.7% vs. 69.8%, hypernyms-random 91.8% vs. 64.1% and co-hyponyms-random 97.8% vs. 79.4%. In order to compare the performance with the state-of-the-art, we have also evaluated ROOT9 in subsets of the Weeds et al. (2014) datasets, proving that it is in fact competitive. Finally, we investigated whether the system learns the semantic relation or it simply learns the prototypical hypernyms, as claimed by Levy et al. (2015). The second possibility seems to be the most likely, even though ROOT9 can be trained on negative examples (i.e., switched hypernyms) to drastically reduce this bias.
What a Nerd! Beating Students and Vector Cosine in the ESL and TOEFL Datasets
Mar 29, 2016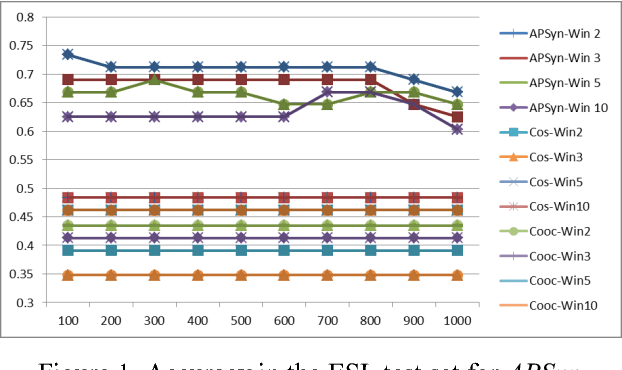
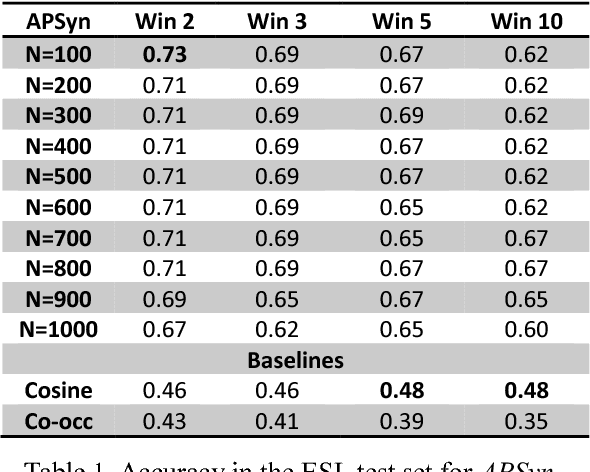
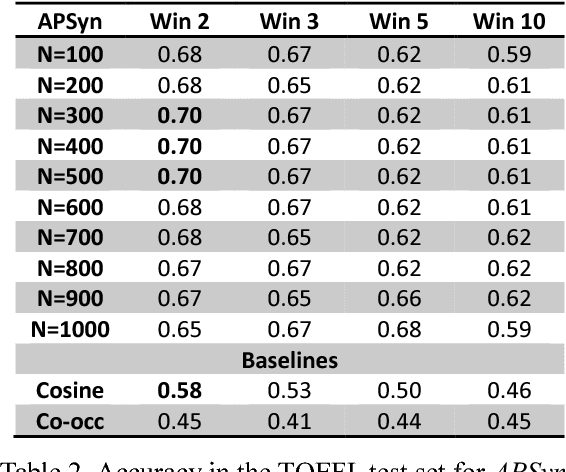
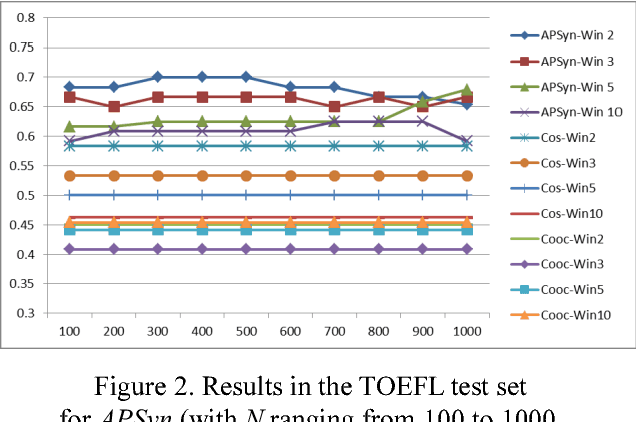
In this paper, we claim that Vector Cosine, which is generally considered one of the most efficient unsupervised measures for identifying word similarity in Vector Space Models, can be outperformed by a completely unsupervised measure that evaluates the extent of the intersection among the most associated contexts of two target words, weighting such intersection according to the rank of the shared contexts in the dependency ranked lists. This claim comes from the hypothesis that similar words do not simply occur in similar contexts, but they share a larger portion of their most relevant contexts compared to other related words. To prove it, we describe and evaluate APSyn, a variant of Average Precision that, independently of the adopted parameters, outperforms the Vector Cosine and the co-occurrence on the ESL and TOEFL test sets. In the best setting, APSyn reaches 0.73 accuracy on the ESL dataset and 0.70 accuracy in the TOEFL dataset, beating therefore the non-English US college applicants (whose average, as reported in the literature, is 64.50%) and several state-of-the-art approaches.