 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying PAC and Regret: Uniform PAC Bounds for Episodic Reinforcement Learning
Jan 02, 2018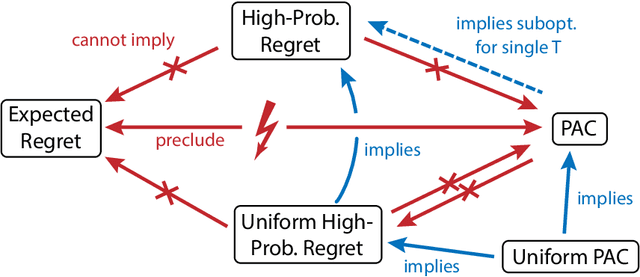
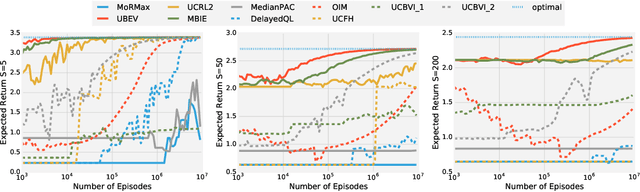
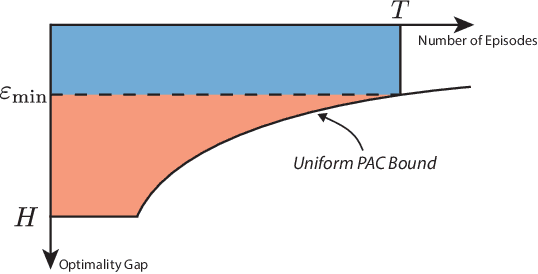
Statistical performance bounds for reinforcement learning (RL) algorithms can be critical for high-stakes applications like healthcare. This paper introduces a new framework for theoretically measuring the performance of such algorithms called Uniform-PAC, which is a strengthening of the classical Probably Approximately Correct (PAC) framework. In contrast to the PAC framework, the uniform version may be used to derive high probability regret guarantees and so forms a bridge between the two setups that has been missing in the literature. We demonstrate the benefits of the new framework for finite-state episodic MDPs with a new algorithm that is Uniform-PAC and simultaneously achieves optimal regret and PAC guarantees except for a factor of the horizon.
Using Options and Covariance Testing for Long Horizon Off-Policy Policy Evaluation
Dec 05, 2017
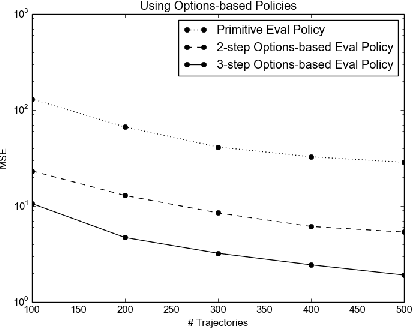
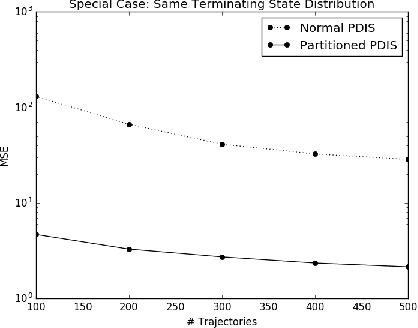
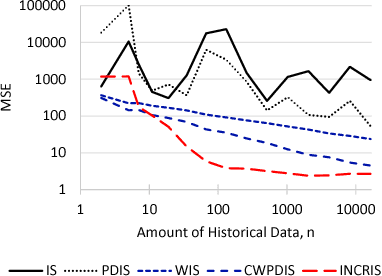
Evaluating a policy by deploying it in the real world can be risky and costly. Off-policy policy evaluation (OPE) algorithms use historical data collected from running a previous policy to evaluate a new policy, which provides a means for evaluating a policy without requiring it to ever be deployed. Importance sampling is a popular OPE method because it is robust to partial observability and works with continuous states and actions. However, the amount of historical data required by importance sampling can scale exponentially with the horizon of the problem: the number of sequential decisions that are made. We propose using policies over temporally extended actions, called options, and show that combining these policies with importance sampling can significantly improve performance for long-horizon problems. In addition, we can take advantage of special cases that arise due to options-based policies to further improve the performance of importance sampling. We further generalize these special cases to a general covariance testing rule that can be used to decide which weights to drop in an IS estimate, and derive a new IS algorithm called Incremental Importance Sampling that can provide significantly more accurate estimates for a broad class of domains.
Generalized Grounding Graphs: A Probabilistic Framework for Understanding Grounded Commands
Nov 29, 2017
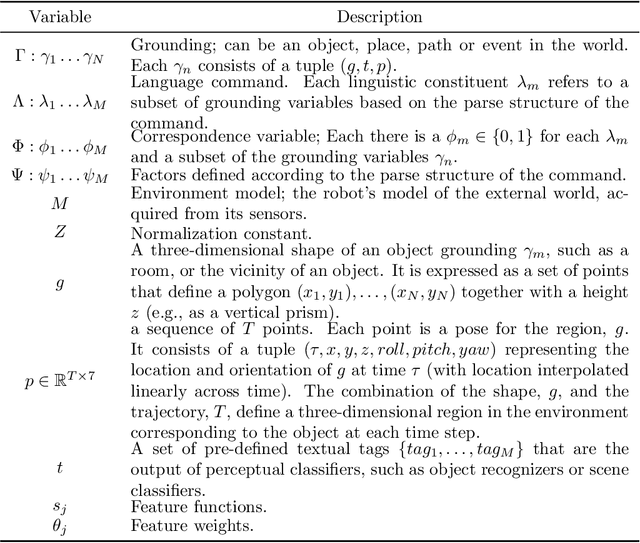
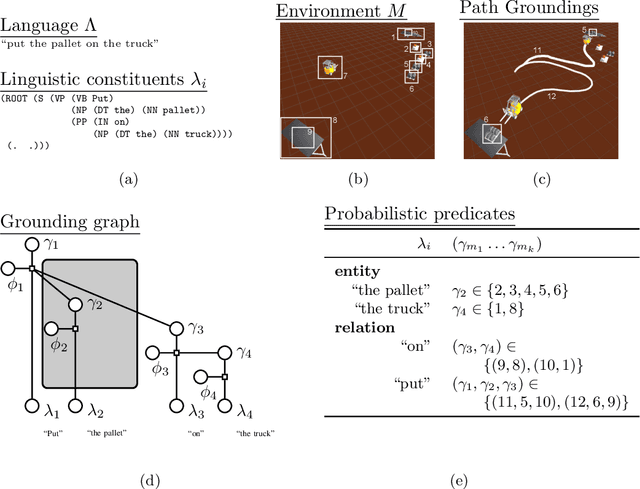
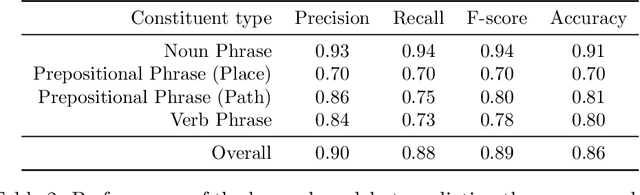
Many task domains require robots to interpret and act upon natural language commands which are given by people and which refer to the robot's physical surroundings. Such interpretation is known variously as the symbol grounding problem, grounded semantics and grounded language acquisition. This problem is challenging because people employ diverse vocabulary and grammar, and because robots have substantial uncertainty about the nature and contents of their surroundings, making it difficult to associate the constitutive language elements (principally noun phrases and spatial relations) of the command text to elements of those surroundings. Symbolic models capture linguistic structure but have not scaled successfully to handle the diverse language produced by untrained users. Existing statistical approaches can better handle diversity, but have not to date modeled complex linguistic structure, limiting achievable accuracy. Recent hybrid approaches have addressed limitations in scaling and complexity, but have not effectively associated linguistic and perceptual features. Our framework, called Generalized Grounding Graphs (G^3), addresses these issues by defining a probabilistic graphical model dynamically according to the linguistic parse structure of a natural language command. This approach scales effectively, handles linguistic diversity, and enables the system to associate parts of a command with the specific objects, places, and events in the external world to which they refer. We show that robots can learn word meanings and use those learned meanings to robustly follow natural language commands produced by untrained users. We demonstrate our approach for both mobility commands and mobile manipulation commands involving a variety of semi-autonomous robotic platforms, including a wheelchair, a micro-air vehicle, a forklift, and the Willow Garage PR2.
On Ensuring that Intelligent Machines Are Well-Behaved
Aug 17, 2017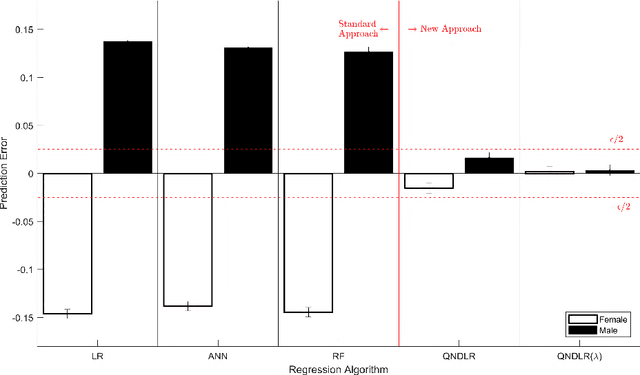
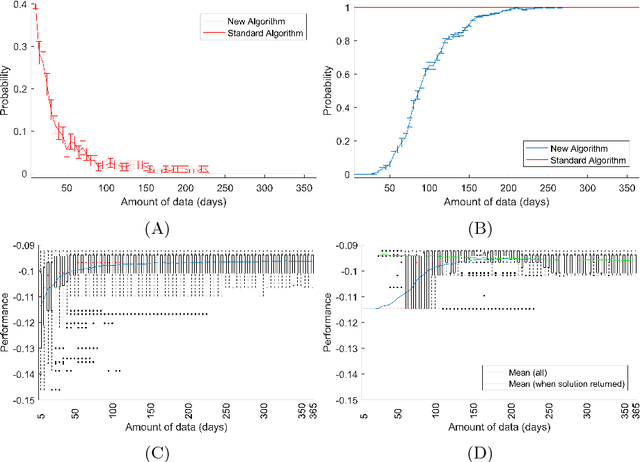
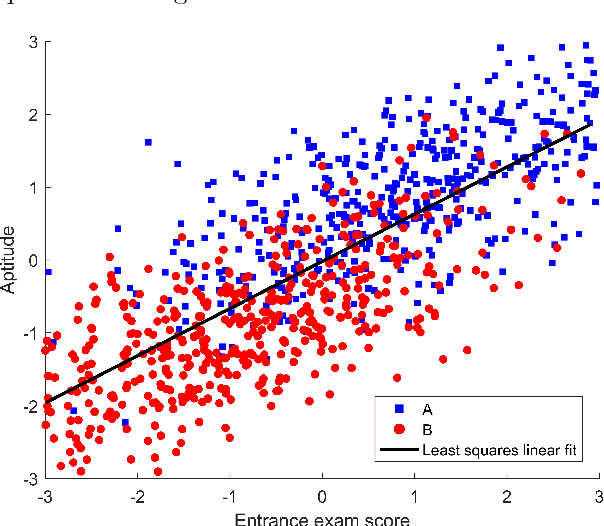
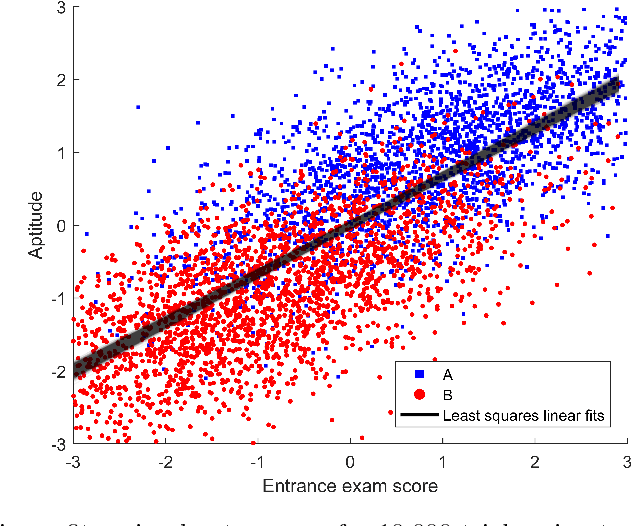
Machine learning algorithms are everywhere, ranging from simple data analysis and pattern recognition tools used across the sciences to complex systems that achieve super-human performance on various tasks. Ensuring that they are well-behaved---that they do not, for example, cause harm to humans or act in a racist or sexist way---is therefore not a hypothetical problem to be dealt with in the future, but a pressing one that we address here. We propose a new framework for designing machine learning algorithms that simplifies the problem of specifying and regulating undesirable behaviors. To show the viability of this new framework, we use it to create new machine learning algorithms that preclude the sexist and harmful behaviors exhibited by standard machine learning algorithms in our experiments. Our framework for designing machine learning algorithms simplifies the safe and responsible application of machine learning.
Policy Gradient Methods for Reinforcement Learning with Function Approximation and Action-Dependent Baselines
Jun 20, 2017We show how an action-dependent baseline can be used by the policy gradient theorem using function approximation, originally presented with action-independent baselines by (Sutton et al. 2000).
Decoupling Learning Rules from Representations
Jun 09, 2017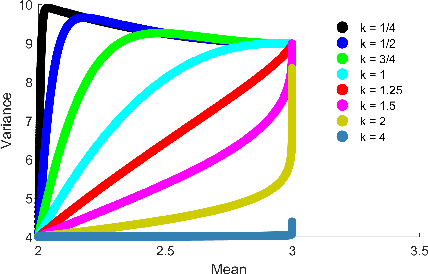
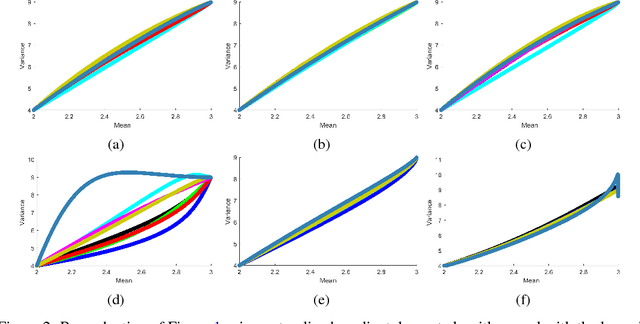
In the artificial intelligence field, learning often corresponds to changing the parameters of a parameterized function. A learning rule is an algorithm or mathematical expression that specifies precisely how the parameters should be changed. When creating an artificial intelligence system, we must make two decisions: what representation should be used (i.e., what parameterized function should be used) and what learning rule should be used to search through the resulting set of representable functions. Using most learning rules, these two decisions are coupled in a subtle (and often unintentional) way. That is, using the same learning rule with two different representations that can represent the same sets of functions can result in two different outcomes. After arguing that this coupling is undesirable, particularly when using artificial neural networks, we present a method for partially decoupling these two decisions for a broad class of learning rules that span unsupervised learning, reinforcement learning, and supervised learning.
Sample Efficient Policy Search for Optimal Stopping Domains
May 24, 2017
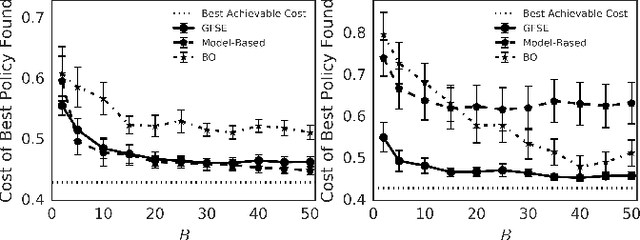
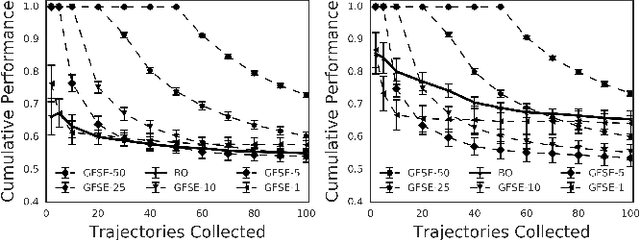
Optimal stopping problems consider the question of deciding when to stop an observation-generating process in order to maximize a return. We examine the problem of simultaneously learning and planning in such domains, when data is collected directly from the environment. We propose GFSE, a simple and flexible model-free policy search method that reuses data for sample efficiency by leveraging problem structure. We bound the sample complexity of our approach to guarantee uniform convergence of policy value estimates, tightening existing PAC bounds to achieve logarithmic dependence on horizon length for our setting. We also examine the benefit of our method against prevalent model-based and model-free approaches on 3 domains taken from diverse fields.
Sample Efficient Feature Selection for Factored MDPs
Mar 09, 2017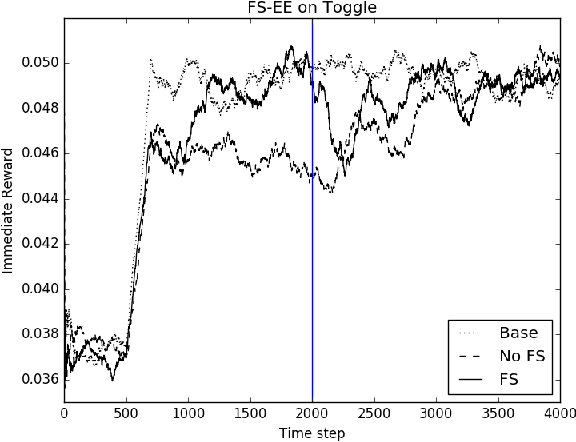
In reinforcement learning, the state of the real world is often represented by feature vectors. However, not all of the features may be pertinent for solving the current task. We propose Feature Selection Explore and Exploit (FS-EE), an algorithm that automatically selects the necessary features while learning a Factored Markov Decision Process, and prove that under mild assumptions, its sample complexity scales with the in-degree of the dynamics of just the necessary features, rather than the in-degree of all features. This can result in a much better sample complexity when the in-degree of the necessary features is smaller than the in-degree of all features.
Importance Sampling with Unequal Support
Nov 10, 2016
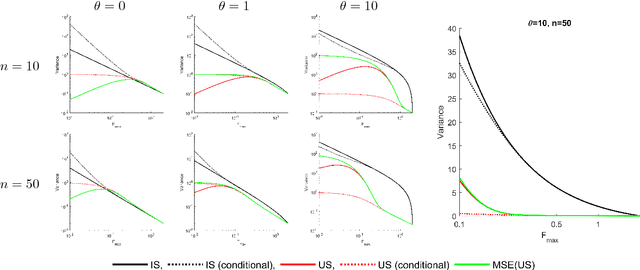
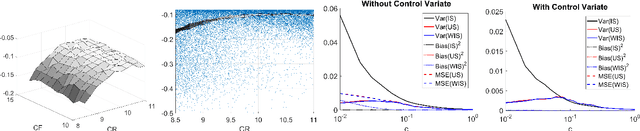
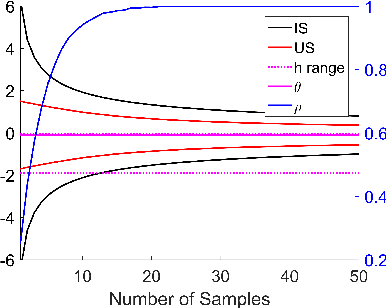
Importance sampling is often used in machine learning when training and testing data come from different distributions. In this paper we propose a new variant of importance sampling that can reduce the variance of importance sampling-based estimates by orders of magnitude when the supports of the training and testing distributions differ. After motivating and presenting our new importance sampling estimator, we provide a detailed theoretical analysis that characterizes both its bias and variance relative to the ordinary importance sampling estimator (in various settings, which include cases where ordinary importance sampling is biased, while our new estimator is not, and vice versa). We conclude with an example of how our new importance sampling estimator can be used to improve estimates of how well a new treatment policy for diabetes will work for an individual, using only data from when the individual used a previous treatment policy.
A PAC RL Algorithm for Episodic POMDPs
Jun 01, 2016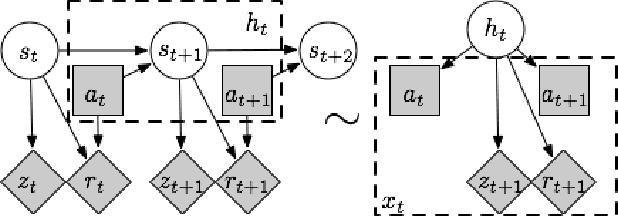
Many interesting real world domains involve reinforcement learning (RL) in partially observable environments. Efficient learning in such domains is important, but existing sample complexity bounds for partially observable RL are at least exponential in the episode length. We give, to our knowledge, the first partially observable RL algorithm with a polynomial bound on the number of episodes on which the algorithm may not achieve near-optimal performance. Our algorithm is suitable for an important class of episodic POMDPs. Our approach builds on recent advances in method of moments for latent variable model estimation.