 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowco: Rethinking Data Analysis in the Age of LLMs
Apr 18, 2025Conducting data analysis typically involves authoring code to transform, visualize, analyze, and interpret data. Large language models (LLMs) are now capable of generating such code for simple, routine analyses. LLMs promise to democratize data science by enabling those with limited programming expertise to conduct data analyses, including in scientific research, business, and policymaking. However, analysts in many real-world settings must often exercise fine-grained control over specific analysis steps, verify intermediate results explicitly, and iteratively refine their analytical approaches. Such tasks present barriers to building robust and reproducible analyses using LLMs alone or even in conjunction with existing authoring tools (e.g., computational notebooks). This paper introduces Flowco, a new mixed-initiative system to address these challenges. Flowco leverages a visual dataflow programming model and integrates LLMs into every phase of the authoring process. A user study suggests that Flowco supports analysts, particularly those with less programming experience, in quickly authoring, debugging, and refining data analyses.
Effective LLM-Driven Code Generation with Pythoness
Jan 03, 2025



The advent of large language models (LLMs) has paved the way for a new era of programming tools with both significant capabilities and risks, as the generated code lacks guarantees of correctness and reliability. Developers using LLMs currently face the difficult task of optimizing, integrating, and maintaining code generated by AI. We propose an embedded domain-specific language (DSL), Pythoness, to address those challenges. In Pythoness, developers program with LLMs at a higher level of abstraction. Rather than interacting directly with generated code, developers using Pythoness operate at the level of behavioral specifications when writing functions, classes, or an entire program. These specifications can take the form of unit tests and property-based tests, which may be expressed formally or in natural language. Guided by these specifications, Pythoness generates code that both passes the tests and can be continuously checked during execution. We posit that the Pythoness approach lets developers harness the full potential of LLMs for code generation while substantially mitigating their inherent risks. We describe our current prototype implementation of Pythoness and demonstrate that it can successfully leverage a combination of tests and code generation to yield higher quality code than specifications alone.
ChatDBG: An AI-Powered Debugging Assistant
Mar 25, 2024



This paper presents ChatDBG, the first AI-powered debugging assistant. ChatDBG integrates large language models (LLMs) to significantly enhance the capabilities and user-friendliness of conventional debuggers. ChatDBG lets programmers engage in a collaborative dialogue with the debugger, allowing them to pose complex questions about program state, perform root cause analysis for crashes or assertion failures, and explore open-ended queries like "why is x null?". To handle these queries, ChatDBG grants the LLM autonomy to take the wheel and drive debugging by issuing commands to navigate through stacks and inspect program state; it then reports its findings and yields back control to the programmer. Our ChatDBG prototype integrates with standard debuggers including LLDB, GDB, and WinDBG for native code and Pdb for Python. Our evaluation across a diverse set of code, including C/C++ code with known bugs and a suite of Python code including standalone scripts and Jupyter notebooks, demonstrates that ChatDBG can successfully analyze root causes, explain bugs, and generate accurate fixes for a wide range of real-world errors. For the Python programs, a single query led to an actionable bug fix 67% of the time; one additional follow-up query increased the success rate to 85%. ChatDBG has seen rapid uptake; it has already been downloaded nearly 30,000 times.
CoverUp: Coverage-Guided LLM-Based Test Generation
Mar 24, 2024This paper presents CoverUp, a novel system that drives the generation of high-coverage Python regression tests via a combination of coverage analysis and large-language models (LLMs). CoverUp iteratively improves coverage, interleaving coverage analysis with dialogs with the LLM to focus its attention on as yet uncovered lines and branches. The resulting test suites significantly improve coverage over the current state of the art: compared to CodaMosa, a hybrid LLM / search-based software testing system, CoverUp substantially improves coverage across the board. On a per-module basis, CoverUp achieves median line coverage of 81% (vs. 62%), branch coverage of 53% (vs. 35%) and line+branch coverage of 78% (vs. 55%). We show that CoverUp's iterative, coverage-guided approach is crucial to its effectiveness, contributing to nearly half of its successes.
Mossad: Defeating Software Plagiarism Detection
Oct 04, 2020
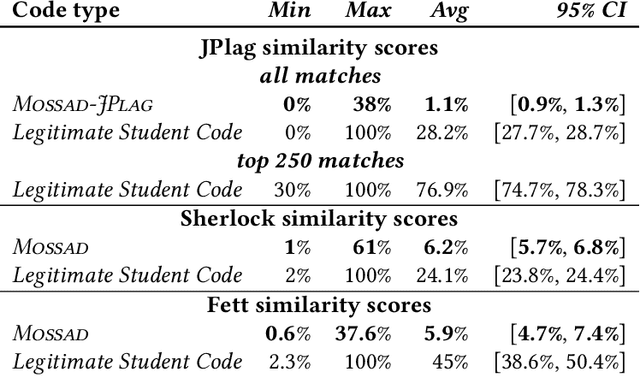
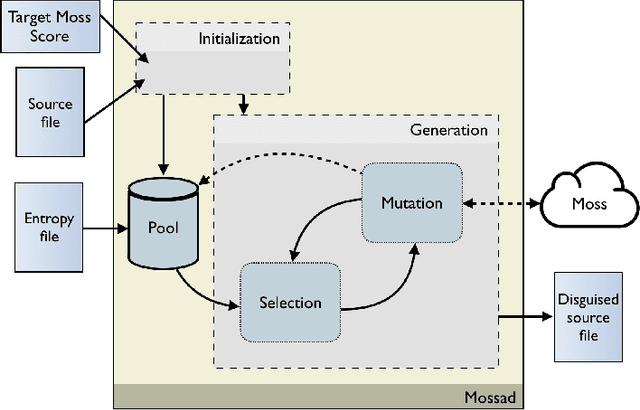

Automatic software plagiarism detection tools are widely used in educational settings to ensure that submitted work was not copied. These tools have grown in use together with the rise in enrollments in computer science programs and the widespread availability of code on-line. Educators rely on the robustness of plagiarism detection tools; the working assumption is that the effort required to evade detection is as high as that required to actually do the assigned work. This paper shows this is not the case. It presents an entirely automatic program transformation approach, Mossad, that defeats popular software plagiarism detection tools. Mossad comprises a framework that couples techniques inspired by genetic programming with domain-specific knowledge to effectively undermine plagiarism detectors. Mossad is effective at defeating four plagiarism detectors, including Moss and JPlag. Mossad is both fast and effective: it can, in minutes, generate modified versions of programs that are likely to escape detection. More insidiously, because of its non-deterministic approach, Mossad can, from a single program, generate dozens of variants, which are classified as no more suspicious than legitimate assignments. A detailed study of Mossad across a corpus of real student assignments demonstrates its efficacy at evading detection. A user study shows that graduate student assistants consistently rate Mossad-generated code as just as readable as authentic student code. This work motivates the need for both research on more robust plagiarism detection tools and greater integration of naturally plagiarism-resistant methodologies like code review into computer science education.