 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Normalization of Confusion Matrices: Methods and Geometric Interpretations
Sep 05, 2025The confusion matrix is a standard tool for evaluating classifiers by providing insights into class-level errors. In heterogeneous settings, its values are shaped by two main factors: class similarity -- how easily the model confuses two classes -- and distribution bias, arising from skewed distributions in the training and test sets. However, confusion matrix values reflect a mix of both factors, making it difficult to disentangle their individual contributions. To address this, we introduce bistochastic normalization using Iterative Proportional Fitting, a generalization of row and column normalization. Unlike standard normalizations, this method recovers the underlying structure of class similarity. By disentangling error sources, it enables more accurate diagnosis of model behavior and supports more targeted improvements. We also show a correspondence between confusion matrix normalizations and the model's internal class representations. Both standard and bistochastic normalizations can be interpreted geometrically in this space, offering a deeper understanding of what normalization reveals about a classifier.
A Weighted Loss Approach to Robust Federated Learning under Data Heterogeneity
Jun 12, 2025Federated learning (FL) is a machine learning paradigm that enables multiple data holders to collaboratively train a machine learning model without sharing their training data with external parties. In this paradigm, workers locally update a model and share with a central server their updated gradients (or model parameters). While FL seems appealing from a privacy perspective, it opens a number of threats from a security perspective as (Byzantine) participants can contribute poisonous gradients (or model parameters) harming model convergence. Byzantine-resilient FL addresses this issue by ensuring that the training proceeds as if Byzantine participants were absent. Towards this purpose, common strategies ignore outlier gradients during model aggregation, assuming that Byzantine gradients deviate more from honest gradients than honest gradients do from each other. However, in heterogeneous settings, honest gradients may differ significantly, making it difficult to distinguish honest outliers from Byzantine ones. In this paper, we introduce the Worker Label Alignement Loss (WoLA), a weighted loss that aligns honest worker gradients despite data heterogeneity, which facilitates the identification of Byzantines' gradients. This approach significantly outperforms state-of-the-art methods in heterogeneous settings. In this paper, we provide both theoretical insights and empirical evidence of its effectiveness.
Intrusion Detection Using Mouse Dynamics
Oct 10, 2018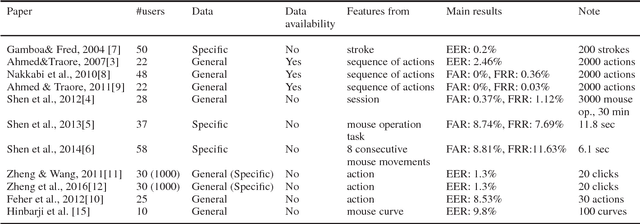
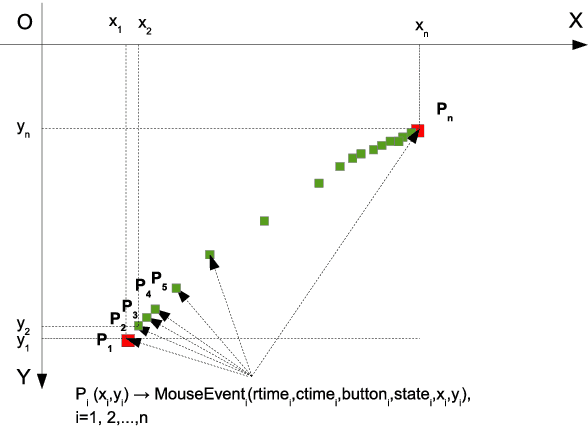
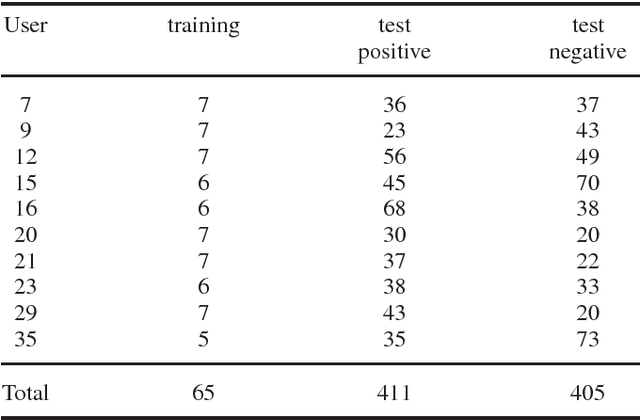
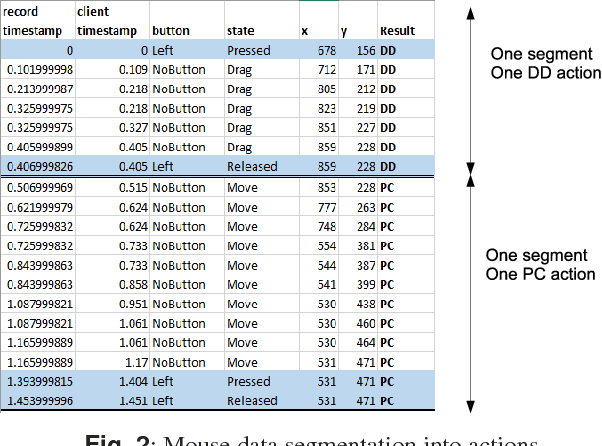
Compared to other behavioural biometrics, mouse dynamics is a less explored area. General purpose data sets containing unrestricted mouse usage data are usually not available. The Balabit data set was released in 2016 for a data science competition, which against the few subjects, can be considered the first adequate publicly available one. This paper presents a performance evaluation study on this data set for impostor detection. The existence of very short test sessions makes this data set challenging. Raw data were segmented into mouse move, point and click and drag and drop types of mouse actions, then several features were extracted. In contrast to keystroke dynamics, mouse data is not sensitive, therefore it is possible to collect negative mouse dynamics data and to use two-class classifiers for impostor detection. Both action- and set of actions-based evaluations were performed. Set of actions-based evaluation achieves 0.92 AUC on the test part of the data set. However, the same type of evaluation conducted on the training part of the data set resulted in maximal AUC (1) using only 13 actions. Drag and drop mouse actions proved to be the best actions for impostor detection.