 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMObyGaze: a film dataset of multimodal objectification densely annotated by experts
May 28, 2025

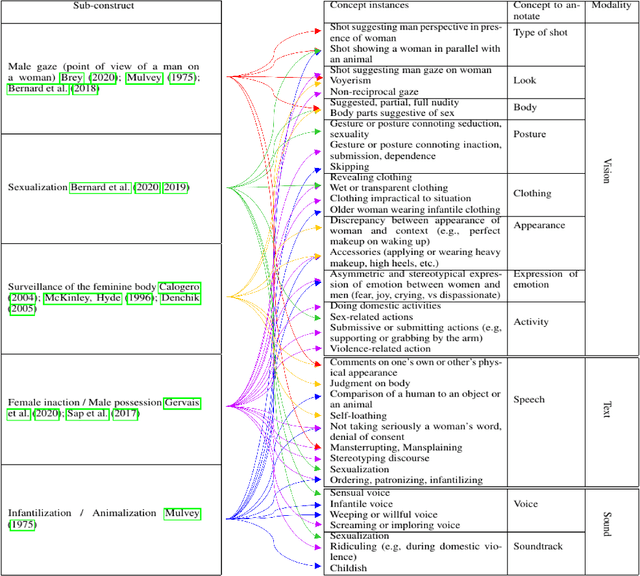
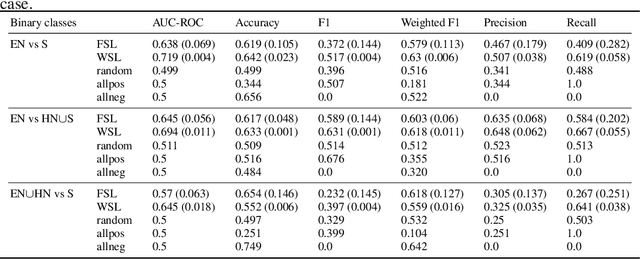
Characterizing and quantifying gender representation disparities in audiovisual storytelling contents is necessary to grasp how stereotypes may perpetuate on screen. In this article, we consider the high-level construct of objectification and introduce a new AI task to the ML community: characterize and quantify complex multimodal (visual, speech, audio) temporal patterns producing objectification in films. Building on film studies and psychology, we define the construct of objectification in a structured thesaurus involving 5 sub-constructs manifesting through 11 concepts spanning 3 modalities. We introduce the Multimodal Objectifying Gaze (MObyGaze) dataset, made of 20 movies annotated densely by experts for objectification levels and concepts over freely delimited segments: it amounts to 6072 segments over 43 hours of video with fine-grained localization and categorization. We formulate different learning tasks, propose and investigate best ways to learn from the diversity of labels among a low number of annotators, and benchmark recent vision, text and audio models, showing the feasibility of the task. We make our code and our dataset available to the community and described in the Croissant format: https://anonymous.4open.science/r/MObyGaze-F600/.
Leveraging multimodal explanatory annotations for video interpretation with Modality Specific Dataset
Apr 15, 2025We examine the impact of concept-informed supervision on multimodal video interpretation models using MOByGaze, a dataset containing human-annotated explanatory concepts. We introduce Concept Modality Specific Datasets (CMSDs), which consist of data subsets categorized by the modality (visual, textual, or audio) of annotated concepts. Models trained on CMSDs outperform those using traditional legacy training in both early and late fusion approaches. Notably, this approach enables late fusion models to achieve performance close to that of early fusion models. These findings underscore the importance of modality-specific annotations in developing robust, self-explainable video models and contribute to advancing interpretable multimodal learning in complex video analysis.