 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Software Vulnerability Static Code Analysis Using Generative Pre-Trained Transformer Models
Jul 31, 2024



Generative Pre-Trained Transformer models have been shown to be surprisingly effective at a variety of natural language processing tasks -- including generating computer code. We evaluate the effectiveness of open source GPT models for the task of automatic identification of the presence of vulnerable code syntax (specifically targeting C and C++ source code). This task is evaluated on a selection of 36 source code examples from the NIST SARD dataset, which are specifically curated to not contain natural English that indicates the presence, or lack thereof, of a particular vulnerability. The NIST SARD source code dataset contains identified vulnerable lines of source code that are examples of one out of the 839 distinct Common Weakness Enumerations (CWE), allowing for exact quantification of the GPT output classification error rate. A total of 5 GPT models are evaluated, using 10 different inference temperatures and 100 repetitions at each setting, resulting in 5,000 GPT queries per vulnerable source code analyzed. Ultimately, we find that the GPT models that we evaluated are not suitable for fully automated vulnerability scanning because the false positive and false negative rates are too high to likely be useful in practice. However, we do find that the GPT models perform surprisingly well at automated vulnerability detection for some of the test cases, in particular surpassing random sampling, and being able to identify the exact lines of code that are vulnerable albeit at a low success rate. The best performing GPT model result found was Llama-2-70b-chat-hf with inference temperature of 0.1 applied to NIST SARD test case 149165 (which is an example of a buffer overflow vulnerability), which had a binary classification recall score of 1.0 and a precision of 1.0 for correctly and uniquely identifying the vulnerable line of code and the correct CWE number.
Comparing Quantum Annealing and Spiking Neuromorphic Computing for Sampling Binary Sparse Coding QUBO Problems
May 30, 2024We consider the problem of computing a sparse binary representation of an image. To be precise, given an image and an overcomplete, non-orthonormal basis, we aim to find a sparse binary vector indicating the minimal set of basis vectors that when added together best reconstruct the given input. We formulate this problem with an $L_2$ loss on the reconstruction error, and an $L_0$ (or, equivalently, an $L_1$) loss on the binary vector enforcing sparsity. This yields a quadratic binary optimization problem (QUBO), whose optimal solution(s) in general is NP-hard to find. The method of unsupervised and unnormalized dictionary feature learning for a desired sparsity level to best match the data is presented. Next, we solve the sparse representation QUBO by implementing it both on a D-Wave quantum annealer with Pegasus chip connectivity via minor embedding, as well as on the Intel Loihi 2 spiking neuromorphic processor. On the quantum annealer, we sample from the sparse representation QUBO using parallel quantum annealing combined with quantum evolution Monte Carlo, also known as iterated reverse annealing. On Loihi 2, we use a stochastic winner take all network of neurons. The solutions are benchmarked against simulated annealing, a classical heuristic, and the optimal solutions are computed using CPLEX. Iterated reverse quantum annealing performs similarly to simulated annealing, although simulated annealing is always able to sample the optimal solution whereas quantum annealing was not always able to. The Loihi 2 solutions that are sampled are on average more sparse than the solutions from any of the other methods. Loihi 2 outperforms a D-Wave quantum annealer standard linear-schedule anneal, while iterated reverse quantum annealing performs much better than both unmodified linear-schedule quantum annealing and iterated warm starting on Loihi 2.
Automated Creation of Source Code Variants of a Cryptographic Hash Function Implementation Using Generative Pre-Trained Transformer Models
Apr 24, 2024


Generative pre-trained transformers (GPT's) are a type of large language machine learning model that are unusually adept at producing novel, and coherent, natural language. In this study the ability of GPT models to generate novel and correct versions, and notably very insecure versions, of implementations of the cryptographic hash function SHA-1 is examined. The GPT models Llama-2-70b-chat-h, Mistral-7B-Instruct-v0.1, and zephyr-7b-alpha are used. The GPT models are prompted to re-write each function using a modified version of the localGPT framework and langchain to provide word embedding context of the full source code and header files to the model, resulting in over 130,000 function re-write GPT output text blocks, approximately 40,000 of which were able to be parsed as C code and subsequently compiled. The generated code is analyzed for being compilable, correctness of the algorithm, memory leaks, compiler optimization stability, and character distance to the reference implementation. Remarkably, several generated function variants have a high implementation security risk of being correct for some test vectors, but incorrect for other test vectors. Additionally, many function implementations were not correct to the reference algorithm of SHA-1, but produced hashes that have some of the basic characteristics of hash functions. Many of the function re-writes contained serious flaws such as memory leaks, integer overflows, out of bounds accesses, use of uninitialised values, and compiler optimization instability. Compiler optimization settings and SHA-256 hash checksums of the compiled binaries are used to cluster implementations that are equivalent but may not have identical syntax - using this clustering over 100,000 novel and correct versions of the SHA-1 codebase were generated where each component C function of the reference implementation is different from the original code.
Automated Multi-Language to English Machine Translation Using Generative Pre-Trained Transformers
Apr 23, 2024



The task of accurate and efficient language translation is an extremely important information processing task. Machine learning enabled and automated translation that is accurate and fast is often a large topic of interest in the machine learning and data science communities. In this study, we examine using local Generative Pretrained Transformer (GPT) models to perform automated zero shot black-box, sentence wise, multi-natural-language translation into English text. We benchmark 16 different open-source GPT models, with no custom fine-tuning, from the Huggingface LLM repository for translating 50 different non-English languages into English using translated TED Talk transcripts as the reference dataset. These GPT model inference calls are performed strictly locally, on single A100 Nvidia GPUs. Benchmark metrics that are reported are language translation accuracy, using BLEU, GLEU, METEOR, and chrF text overlap measures, and wall-clock time for each sentence translation. The best overall performing GPT model for translating into English text for the BLEU metric is ReMM-v2-L2-13B with a mean score across all tested languages of $0.152$, for the GLEU metric is ReMM-v2-L2-13B with a mean score across all tested languages of $0.256$, for the chrF metric is Llama2-chat-AYT-13B with a mean score across all tested languages of $0.448$, and for the METEOR metric is ReMM-v2-L2-13B with a mean score across all tested languages of $0.438$.
Sampling binary sparse coding QUBO models using a spiking neuromorphic processor
Jun 02, 2023



We consider the problem of computing a sparse binary representation of an image. To be precise, given an image and an overcomplete, non-orthonormal basis, we aim to find a sparse binary vector indicating the minimal set of basis vectors that when added together best reconstruct the given input. We formulate this problem with an $L_2$ loss on the reconstruction error, and an $L_0$ (or, equivalently, an $L_1$) loss on the binary vector enforcing sparsity. This yields a so-called Quadratic Unconstrained Binary Optimization (QUBO) problem, whose solution is generally NP-hard to find. The contribution of this work is twofold. First, the method of unsupervised and unnormalized dictionary feature learning for a desired sparsity level to best match the data is presented. Second, the binary sparse coding problem is then solved on the Loihi 1 neuromorphic chip by the use of stochastic networks of neurons to traverse the non-convex energy landscape. The solutions are benchmarked against the classical heuristic simulated annealing. We demonstrate neuromorphic computing is suitable for sampling low energy solutions of binary sparse coding QUBO models, and although Loihi 1 is capable of sampling very sparse solutions of the QUBO models, there needs to be improvement in the implementation in order to be competitive with simulated annealing.
An Enhanced Machine Learning Topic Classification Methodology for Cybersecurity
Aug 30, 2021
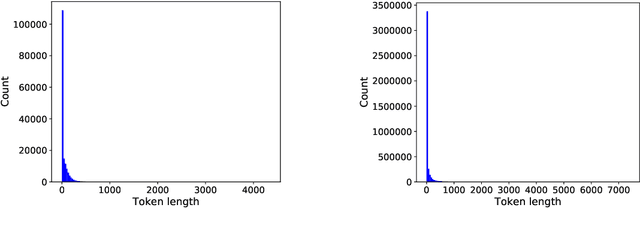
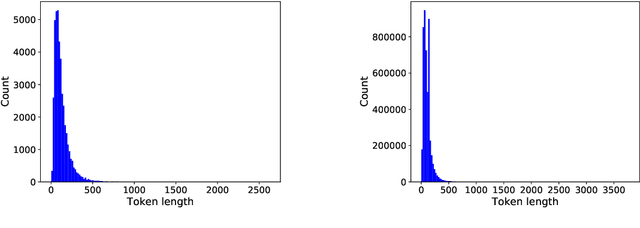
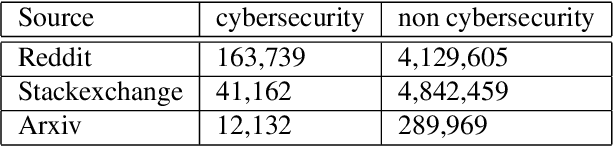
In this research, we use user defined labels from three internet text sources (Reddit, Stackexchange, Arxiv) to train 21 different machine learning models for the topic classification task of detecting cybersecurity discussions in natural text. We analyze the false positive and false negative rates of each of the 21 model's in a cross validation experiment. Then we present a Cybersecurity Topic Classification (CTC) tool, which takes the majority vote of the 21 trained machine learning models as the decision mechanism for detecting cybersecurity related text. We also show that the majority vote mechanism of the CTC tool provides lower false negative and false positive rates on average than any of the 21 individual models. We show that the CTC tool is scalable to the hundreds of thousands of documents with a wall clock time on the order of hours.