 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Learning with Loss-Guided Training
May 31, 2020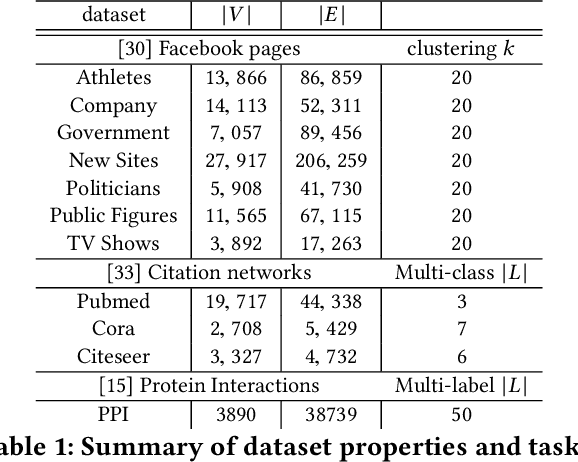

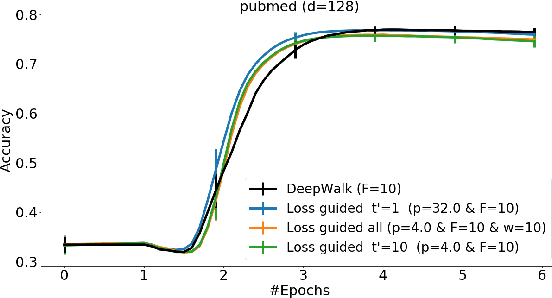
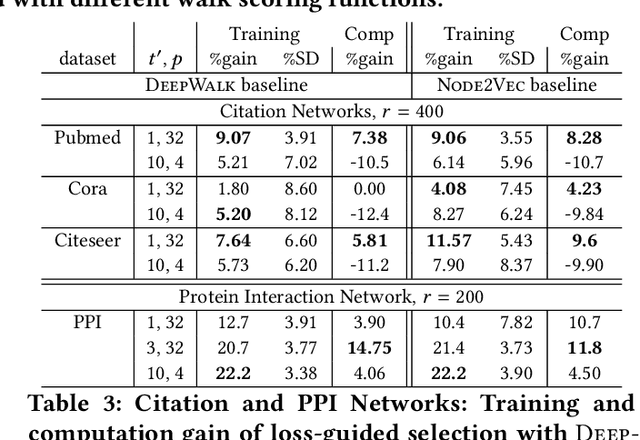
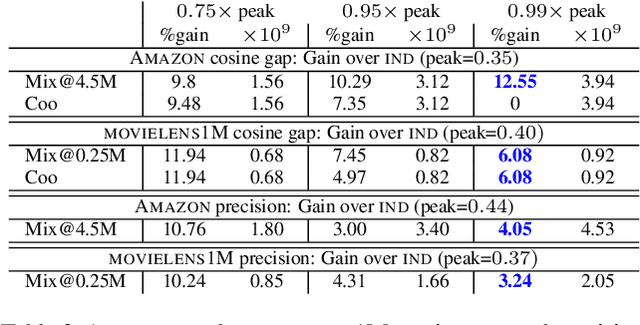
Classically, ML models trained with stochastic gradient descent (SGD) are designed to minimize the average loss per example and use a distribution of training examples that remains {\em static} in the course of training. Research in recent years demonstrated, empirically and theoretically, that significant acceleration is possible by methods that dynamically adjust the training distribution in the course of training so that training is more focused on examples with higher loss. We explore {\em loss-guided training} in a new domain of node embedding methods pioneered by {\sc DeepWalk}. These methods work with implicit and large set of positive training examples that are generated using random walks on the input graph and therefore are not amenable for typical example selection methods. We propose computationally efficient methods that allow for loss-guided training in this framework. Our empirical evaluation on a rich collection of datasets shows significant acceleration over the baseline static methods, both in terms of total training performed and overall computation.
LSH Microbatches for Stochastic Gradients: Value in Rearrangement
Oct 05, 2018
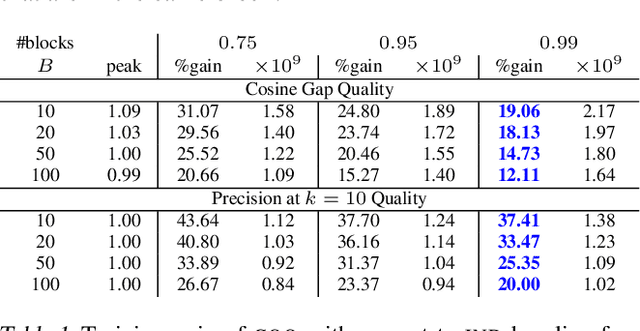
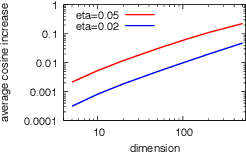
Metric embeddings are immensely useful representation of interacting entities such as videos, users, search queries, online resources, words, and more. Embeddings are computed by optimizing a loss function of the form of a sum over provided associations so that relation of embedding vectors reflects strength of association. Moreover, the resulting embeddings allow us to predict the strength of unobserved associations. Typically, the optimization performs stochastic gradient updates on minibatches of associations that are arranged independently at random. We propose and study here the antithesis of {\em coordinated} arrangements, which we obtain efficiently through {\em LSH microbatching}, where similar associations are grouped together. Coordinated arrangements leverage the similarity of entities evident from their association vectors. We experimentally study the benefit of tunable minibatch arrangements, demonstrating consistent reductions of 3-15\% in training. Arrangement emerges as a powerful performance knob for SGD that is orthogonal and compatible with other tuning methods, and thus is a candidate for wide deployment.
Bootstrapped Graph Diffusions: Exposing the Power of Nonlinearity
Mar 15, 2017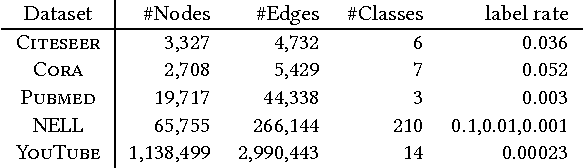
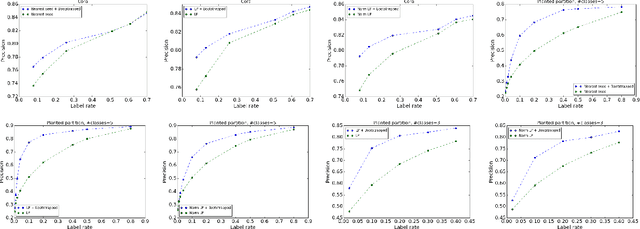
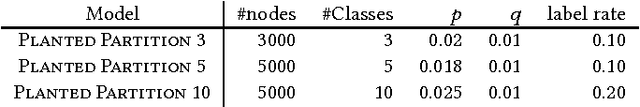
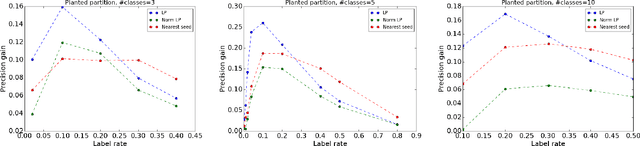
Graph-based semi-supervised learning (SSL) algorithms predict labels for all nodes based on provided labels of a small set of seed nodes. Classic methods capture the graph structure through some underlying diffusion process that propagates through the graph edges. Spectral diffusion, which includes personalized page rank and label propagation, propagates through random walks. Social diffusion propagates through shortest paths. A common ground to these diffusions is their {\em linearity}, which does not distinguish between contributions of few "strong" relations and many "weak" relations. Recently, non-linear methods such as node embeddings and graph convolutional networks (GCN) demonstrated a large gain in quality for SSL tasks. These methods introduce multiple components and greatly vary on how the graph structure, seed label information, and other features are used. We aim here to study the contribution of non-linearity, as an isolated ingredient, to the performance gain. To do so, we place classic linear graph diffusions in a self-training framework. Surprisingly, we observe that SSL using the resulting {\em bootstrapped diffusions} not only significantly improves over the respective non-bootstrapped baselines but also outperform state-of-the-art non-linear SSL methods. Moreover, since the self-training wrapper retains the scalability of the base method, we obtain both higher quality and better scalability.