 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Training and Evaluation Resources for Vision-Language Models
Apr 20, 2026Vision Language Models (VLMs) achieved rapid progress in the recent years. However, despite their growth, VLMs development is heavily grounded on English, leading to two main limitations: (i) the lack of multilingual and multimodal datasets for training, and (ii) the scarcity of comprehensive evaluation benchmarks across languages. In this work, we address these gaps by introducing a new comprehensive suite of resources for VLMs training and evaluation spanning five European languages (English, French, German, Italian, and Spanish). We adopt a regeneration-translation paradigm that produces high-quality cross-lingual resources by combining curated synthetic generation and manual annotation. Specifically, we build Multi-PixMo, a training corpus obtained regenerating examples from Pixmo pre-existing datasets with permissively licensed models: PixMo-Cap, PixMo-AskModelAnything, and CoSyn-400k. On the evaluation side, we construct a set of multilingual benchmarks derived translating widely used English datasets (MMbench, ScienceQA, MME, POPE, AI2D). We assess the quality of these resources through qualitative and quantitative human analyses, measuring inter-annotator agreement. Additionally, we perform ablation studies to demonstrate the impact of multilingual data, with respect to English only, in VLMs training. Experiments, comprising 3 different models show that using multilingual, multimodal examples for training VLMs aids is consistently beneficial on non-English benchmarks, with positive transfer to English as well.
Deep Contextualized Word Embeddings in Transition-Based and Graph-Based Dependency Parsing -- A Tale of Two Parsers Revisited
Aug 27, 2019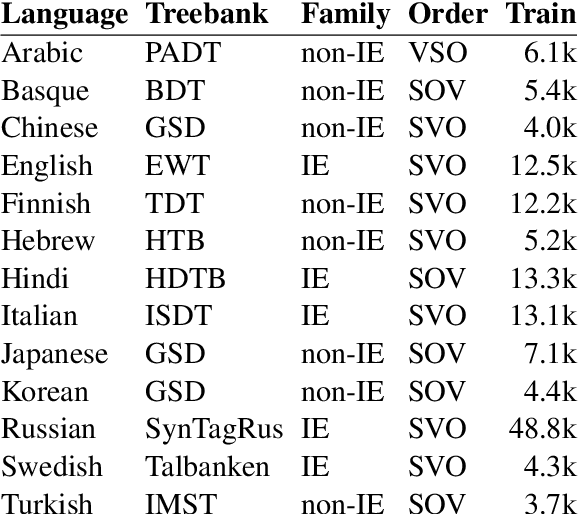
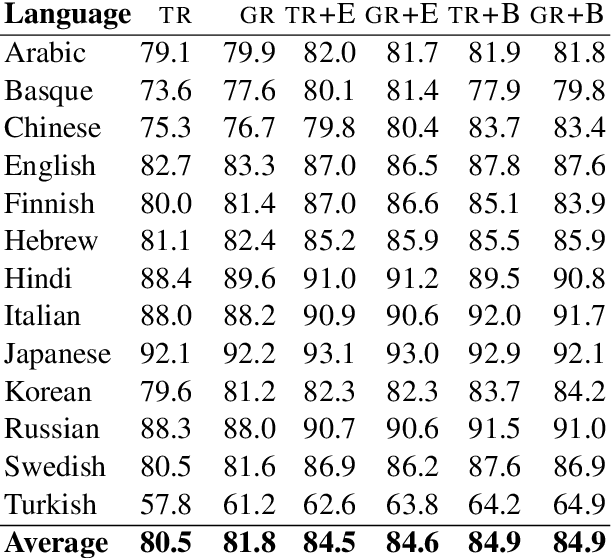
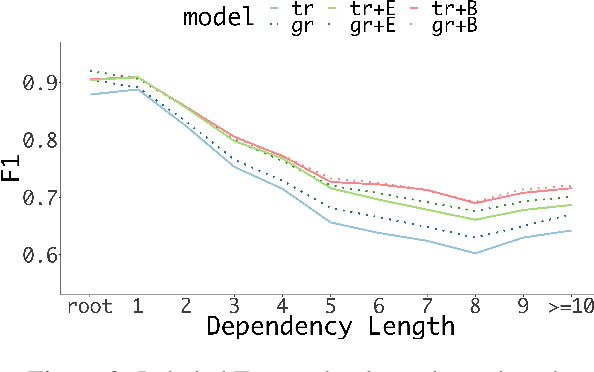
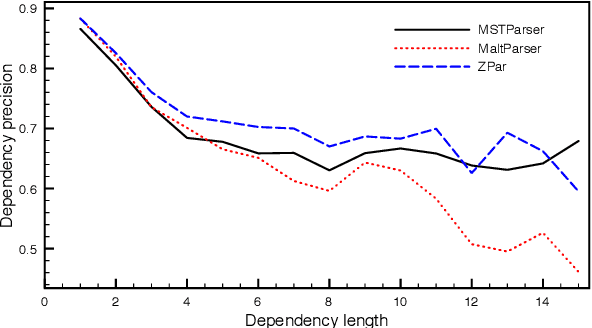
Transition-based and graph-based dependency parsers have previously been shown to have complementary strengths and weaknesses: transition-based parsers exploit rich structural features but suffer from error propagation, while graph-based parsers benefit from global optimization but have restricted feature scope. In this paper, we show that, even though some details of the picture have changed after the switch to neural networks and continuous representations, the basic trade-off between rich features and global optimization remains essentially the same. Moreover, we show that deep contextualized word embeddings, which allow parsers to pack information about global sentence structure into local feature representations, benefit transition-based parsers more than graph-based parsers, making the two approaches virtually equivalent in terms of both accuracy and error profile. We argue that the reason is that these representations help prevent search errors and thereby allow transition-based parsers to better exploit their inherent strength of making accurate local decisions. We support this explanation by an error analysis of parsing experiments on 13 languages.