 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeidSCD: Identifying Training Datasets through Semantic Correlation Descriptors
May 28, 2026Can a dataset be recognized from the spurious correlations it induces during training? We argue that datasets leave dataset-specific traces in a model's learned semantic correlation structure: incidental regularities that are predictive within a dataset, but not causal for the underlying task, can be internalized during training. We use this insight to study dataset-level membership inference, moving beyond existing methods that rely on behavioral or distributional evidence such as confidence scores, losses, margins, generated samples, or query responses. We introduce a white-box semantic fingerprinting approach based on semantic correlation descriptors (SCDs), which capture the semantic correlation structure learned by a model and make it comparable across dataset mixtures. In a controlled leave-one-dataset-out diagnostic, SCDs recover dataset-specific changes and perfectly separate matching from non-matching dataset pairs. We then propose a practical SCD-based membership score that tests whether a target dataset is part of a model's training mixture using only the model's SCD and the target dataset's standalone SCD, without requiring leave-one-dataset-out models. Across three diverse experimental settings, with dataset groups for natural language inference, emotion classification, and medical text classification, we test both the advantages and limitations of SCD-based membership inference with different degrees of semantic separation and keyword support between dataset splits. On average, the classifier based on this score achieves the highest performance and the lowest std, outperforming black-box baselines RMIA, Attack-P, and LiRA, as well as the white-box SIF baseline. These results show that dataset membership can be traced through internal semantic correlations, with the largest relative gain exceeding 60% in ROC-AUC when dataset groups expose distinct semantic particularities.
Fine-Tuning Regimes Define Distinct Continual Learning Problems
Apr 23, 2026Continual learning (CL) studies how models acquire tasks sequentially while retaining previously learned knowledge. Despite substantial progress in benchmarking CL methods, comparative evaluations typically keep the fine-tuning regime fixed. In this paper, we argue that the fine-tuning regime, defined by the trainable parameter subspace, is itself a key evaluation variable. We formalize adaptation regimes as projected optimization over fixed trainable subspaces, showing that changing the trainable depth alters the effective update signal through which both current task fitting and knowledge preservation operate. This analysis motivates the hypothesis that method comparisons need not be invariant across regimes. We test this hypothesis in task incremental CL, five trainable depth regimes, and four standard methods: online EWC, LwF, SI, and GEM. Across five benchmark datasets, namely MNIST, Fashion MNIST, KMNIST, QMNIST, and CIFAR-100, and across 11 task orders per dataset, we find that the relative ranking of methods is not consistently preserved across regimes. We further show that deeper adaptation regimes are associated with larger update magnitudes, higher forgetting, and a stronger relationship between the two. These results show that comparative conclusions in CL can depend strongly on the chosen fine-tuning regime, motivating regime-aware evaluation protocols that treat trainable depth as an explicit experimental factor.
Temporal Taskification in Streaming Continual Learning: A Source of Evaluation Instability
Apr 23, 2026Streaming Continual Learning (CL) typically converts a continuous stream into a sequence of discrete tasks through temporal partitioning. We argue that this temporal taskification step is not a neutral preprocessing choice, but a structural component of evaluation: different valid splits of the same stream can induce different CL regimes and therefore different benchmark conclusions. To study this effect, we introduce a taskification-level framework based on plasticity and stability profiles, a profile distance between taskifications, and Boundary-Profile Sensitivity (BPS), which diagnoses how strongly small boundary perturbations alter the induced regime before any CL model is trained. We evaluate continual finetuning, Experience Replay, Elastic Weight Consolidation, and Learning without Forgetting on network traffic forecasting with CESNET-Timeseries24, keeping the stream, model, and training budget fixed while varying only the temporal taskification. Across 9-, 30-, and 44-day splits, we observe substantial changes in forecasting error, forgetting, and backward transfer, showing that taskification alone can materially affect CL evaluation. We further find that shorter taskifications induce noisier distribution-level patterns, larger structural distances, and higher BPS, indicating greater sensitivity to boundary perturbations. These results show that benchmark conclusions in streaming CL depend not only on the learner and the data stream, but also on how that stream is taskified, motivating temporal taskification as a first-class evaluation variable.
Closing the gap on tabular data with Fourier and Implicit Categorical Features
Feb 26, 2026While Deep Learning has demonstrated impressive results in applications on various data types, it continues to lag behind tree-based methods when applied to tabular data, often referred to as the last "unconquered castle" for neural networks. We hypothesize that a significant advantage of tree-based methods lies in their intrinsic capability to model and exploit non-linear interactions induced by features with categorical characteristics. In contrast, neural-based methods exhibit biases toward uniform numerical processing of features and smooth solutions, making it challenging for them to effectively leverage such patterns. We address this performance gap by using statistical-based feature processing techniques to identify features that are strongly correlated with the target once discretized. We further mitigate the bias of deep models for overly-smooth solutions, a bias that does not align with the inherent properties of the data, using Learned Fourier. We show that our proposed feature preprocessing significantly boosts the performance of deep learning models and enables them to achieve a performance that closely matches or surpasses XGBoost on a comprehensive tabular data benchmark.
ChronoGraph: A Real-World Graph-Based Multivariate Time Series Dataset
Sep 04, 2025We present ChronoGraph, a graph-structured multivariate time series forecasting dataset built from real-world production microservices. Each node is a service that emits a multivariate stream of system-level performance metrics, capturing CPU, memory, and network usage patterns, while directed edges encode dependencies between services. The primary task is forecasting future values of these signals at the service level. In addition, ChronoGraph provides expert-annotated incident windows as anomaly labels, enabling evaluation of anomaly detection methods and assessment of forecast robustness during operational disruptions. Compared to existing benchmarks from industrial control systems or traffic and air-quality domains, ChronoGraph uniquely combines (i) multivariate time series, (ii) an explicit, machine-readable dependency graph, and (iii) anomaly labels aligned with real incidents. We report baseline results spanning forecasting models, pretrained time-series foundation models, and standard anomaly detectors. ChronoGraph offers a realistic benchmark for studying structure-aware forecasting and incident-aware evaluation in microservice systems.
ConceptDrift: Uncovering Biases through the Lens of Foundational Models
Oct 24, 2024



Datasets and pre-trained models come with intrinsic biases. Most methods rely on spotting them by analysing misclassified samples, in a semi-automated human-computer validation. In contrast, we propose ConceptDrift, a method which analyzes the weights of a linear probe, learned on top a foundational model. We capitalize on the weight update trajectory, which starts from the embedding of the textual representation of the class, and proceeds to drift towards embeddings that disclose hidden biases. Different from prior work, with this approach we can pin-point unwanted correlations from a dataset, providing more than just possible explanations for the wrong predictions. We empirically prove the efficacy of our method, by significantly improving zero-shot performance with biased-augmented prompting. Our method is not bounded to a single modality, and we experiment in this work with both image (Waterbirds, CelebA, Nico++) and text datasets (CivilComments).
Stylist: Style-Driven Feature Ranking for Robust Novelty Detection
Oct 05, 2023Novelty detection aims at finding samples that differ in some form from the distribution of seen samples. But not all changes are created equal. Data can suffer a multitude of distribution shifts, and we might want to detect only some types of relevant changes. Similar to works in out-of-distribution generalization, we propose to use the formalization of separating into semantic or content changes, that are relevant to our task, and style changes, that are irrelevant. Within this formalization, we define the robust novelty detection as the task of finding semantic changes while being robust to style distributional shifts. Leveraging pretrained, large-scale model representations, we introduce Stylist, a novel method that focuses on dropping environment-biased features. First, we compute a per-feature score based on the feature distribution distances between environments. Next, we show that our selection manages to remove features responsible for spurious correlations and improve novelty detection performance. For evaluation, we adapt domain generalization datasets to our task and analyze the methods behaviors. We additionally built a large synthetic dataset where we have control over the spurious correlations degree. We prove that our selection mechanism improves novelty detection algorithms across multiple datasets, containing both stylistic and content shifts.
Environment-biased Feature Ranking for Novelty Detection Robustness
Sep 21, 2023



We tackle the problem of robust novelty detection, where we aim to detect novelties in terms of semantic content while being invariant to changes in other, irrelevant factors. Specifically, we operate in a setup with multiple environments, where we determine the set of features that are associated more with the environments, rather than to the content relevant for the task. Thus, we propose a method that starts with a pretrained embedding and a multi-env setup and manages to rank the features based on their environment-focus. First, we compute a per-feature score based on the feature distribution variance between envs. Next, we show that by dropping the highly scored ones, we manage to remove spurious correlations and improve the overall performance by up to 6%, both in covariance and sub-population shift cases, both for a real and a synthetic benchmark, that we introduce for this task.
Learning a Fast 3D Spectral Approach to Object Segmentation and Tracking over Space and Time
Dec 15, 2022



We pose video object segmentation as spectral graph clustering in space and time, with one graph node for each pixel and edges forming local space-time neighborhoods. We claim that the strongest cluster in this video graph represents the salient object. We start by introducing a novel and efficient method based on 3D filtering for approximating the spectral solution, as the principal eigenvector of the graph's adjacency matrix, without explicitly building the matrix. This key property allows us to have a fast parallel implementation on GPU, orders of magnitude faster than classical approaches for computing the eigenvector. Our motivation for a spectral space-time clustering approach, unique in video semantic segmentation literature, is that such clustering is dedicated to preserving object consistency over time, which we evaluate using our novel segmentation consistency measure. Further on, we show how to efficiently learn the solution over multiple input feature channels. Finally, we extend the formulation of our approach beyond the segmentation task, into the realm of object tracking. In extensive experiments we show significant improvements over top methods, as well as over powerful ensembles that combine them, achieving state-of-the-art on multiple benchmarks, both for tracking and segmentation.
Env-Aware Anomaly Detection: Ignore Style Changes, Stay True to Content!
Oct 06, 2022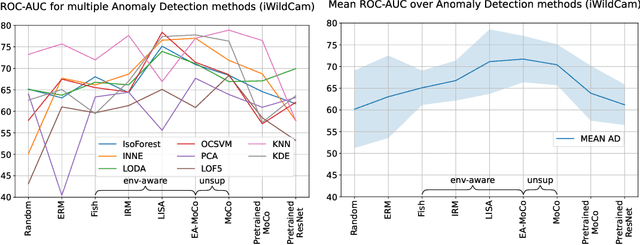
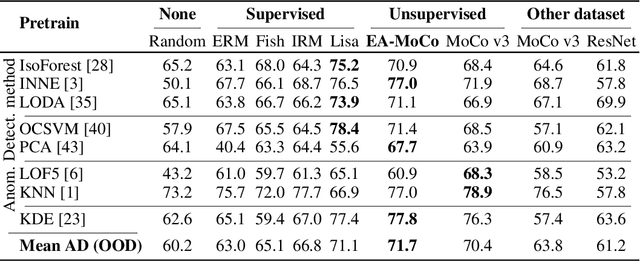
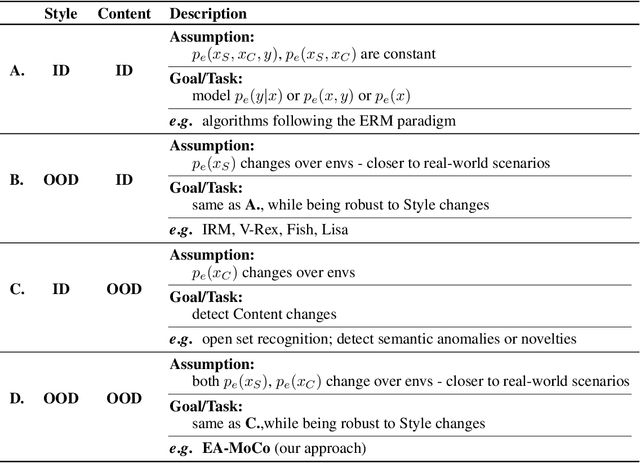
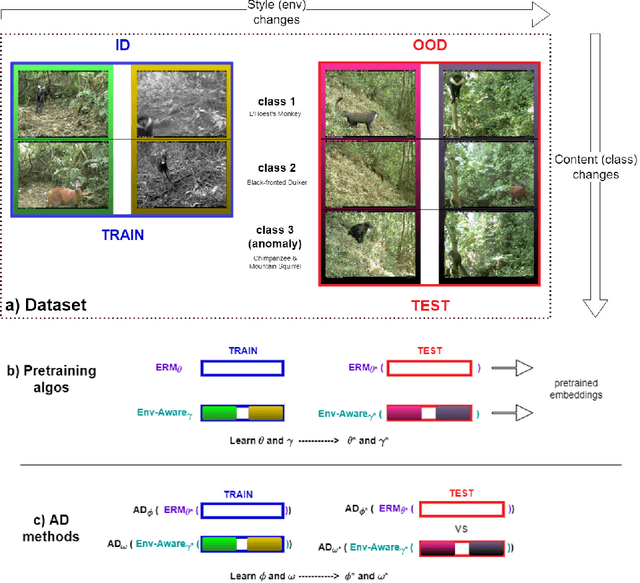
We introduce a formalization and benchmark for the unsupervised anomaly detection task in the distribution-shift scenario. Our work builds upon the iWildCam dataset, and, to the best of our knowledge, we are the first to propose such an approach for visual data. We empirically validate that environment-aware methods perform better in such cases when compared with the basic Empirical Risk Minimization (ERM). We next propose an extension for generating positive samples for contrastive methods that considers the environment labels when training, improving the ERM baseline score by 8.7%.