 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeeding Up Question Answering Task of Language Models via Inverted Index
Oct 24, 2022



Natural language processing applications, such as conversational agents and their question-answering capabilities, are widely used in the real world. Despite the wide popularity of large language models (LLMs), few real-world conversational agents take advantage of LLMs. Extensive resources consumed by LLMs disable developers from integrating them into end-user applications. In this study, we leverage an inverted indexing mechanism combined with LLMs to improve the efficiency of question-answering models for closed-domain questions. Our experiments show that using the index improves the average response time by 97.44%. In addition, due to the reduced search scope, the average BLEU score improved by 0.23 while using the inverted index.
Optimized Tracking of Topic Evolution
Dec 16, 2019
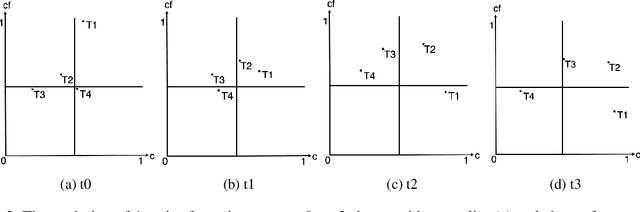
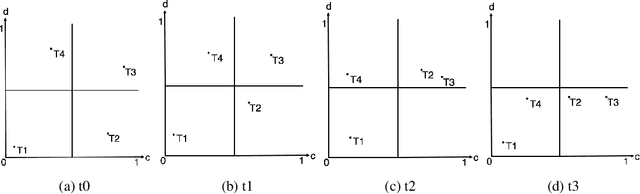
Topic evolution modeling has been researched for a long time and has gained considerable interest. A state-of-the-art method has been recently using word modeling algorithms in combination with community detection mechanisms to achieve better results in a more effective way. We analyse results of this approach and discuss the two major challenges that this approach still faces. Although the topics that have resulted from the recent algorithm are good in general, they are very noisy due to many topics that are very unimportant because of their size, words, or ambiguity. Additionally, the number of words defining each topic is too large, making it difficult to analyse them in their unsorted state. In this paper, we propose approaches to tackle these challenges by adding topic filtering and network analysis metrics to define the importance of a topic. We test different combinations of these metrics to see which combination yields the best results. Furthermore, we add word filtering and ranking to each topic to identify the words with the highest novelty automatically. We evaluate our enhancement methods in two ways: human qualitative evaluation and automatic quantitative evaluation. Moreover, we created two case studies to test the quality of the clusters and words. In the quantitative evaluation, we use the pairwise mutual information score to test the coherency of topics. The quantitative evaluation also includes an analysis of execution times for each part of the program. The results of the experimental evaluations show that the two evaluation methods agree on the positive feasibility of the algorithm. We then show possible extensions in the form of usability and future improvements to the algorithm.
Public vs Media Opinion on Robots
May 05, 2019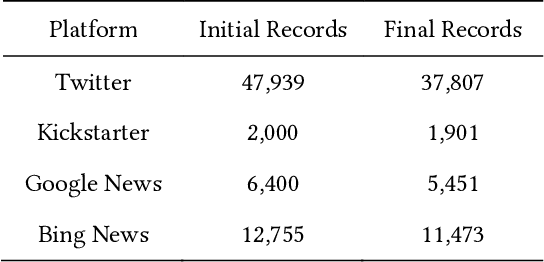

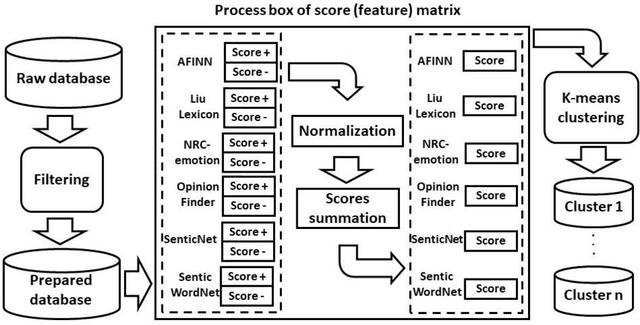
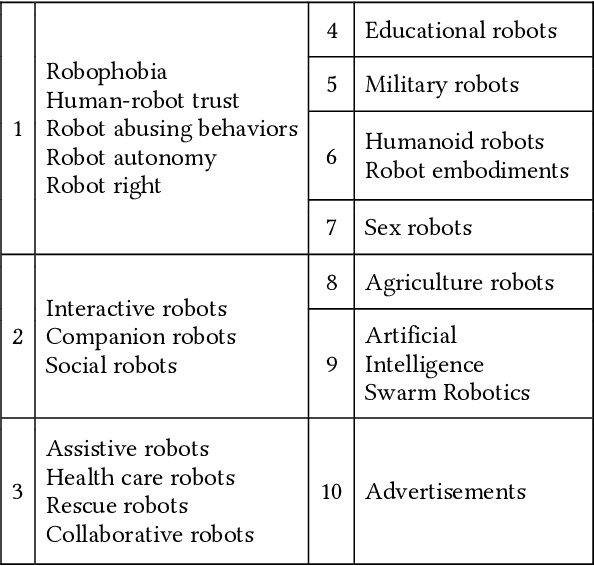
Fast proliferation of robots in people's everyday lives during recent years calls for a profound examination of public consensus, which is the ultimate determinant of the future of this industry. This paper investigates text corpora, consisting of posts in Twitter, Google News, Bing News, and Kickstarter, over an 8 year period to quantify the public and media opinion about this emerging technology. Results demonstrate that the news platforms and the public take an overall positive position on robots. However, there is a deviation between news coverage and people's attitude. Among various robot types, sex robots raise the fiercest debate. Besides, our evaluation reveals that the public and news media conceptualization of robotics has altered over the recent years. More specifically, a shift from the solely industrial-purposed machines, towards more social, assistive, and multi-purpose gadgets is visible.