 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning based, end-to-end metaphor detection in Greek language with Recurrent and Convolutional Neural Networks
Jul 23, 2020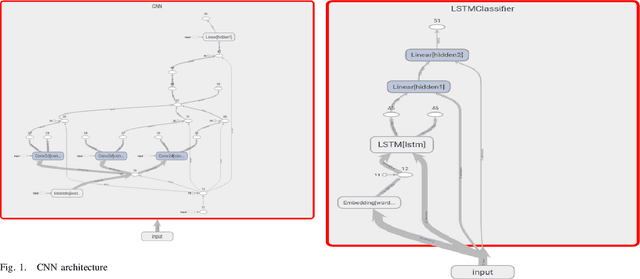
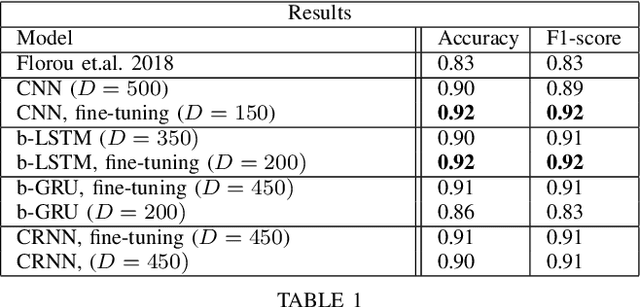
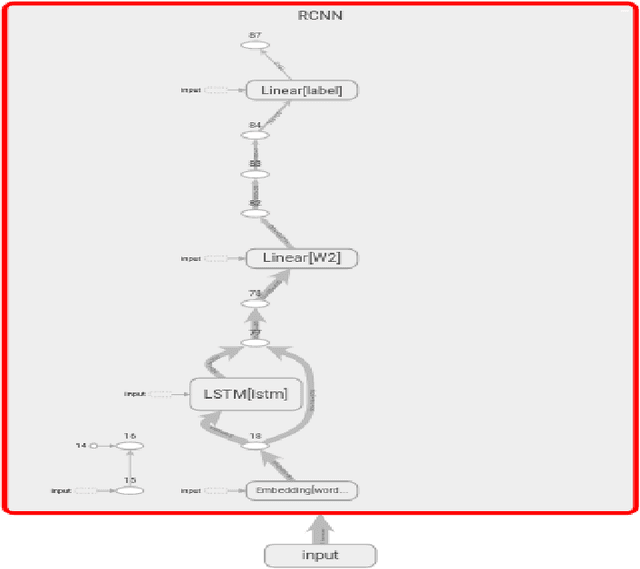
This paper presents and benchmarks a number of end-to-end Deep Learning based models for metaphor detection in Greek. We combine Convolutional Neural Networks and Recurrent Neural Networks with representation learning to bear on the metaphor detection problem for the Greek language. The models presented achieve exceptional accuracy scores, significantly improving the previous state of the art results, which had already achieved accuracy 0.82. Furthermore, no special preprocessing, feature engineering or linguistic knowledge is used in this work. The methods presented achieve accuracy of 0.92 and F-score 0.92 with Convolutional Neural Networks (CNNs) and bidirectional Long Short Term Memory networks (LSTMs). Comparable results of 0.91 accuracy and 0.91 F-score are also achieved with bidirectional Gated Recurrent Units (GRUs) and Convolutional Recurrent Neural Nets (CRNNs). The models are trained and evaluated only on the basis of the training tuples, the sentences and their labels. The outcome is a state of the art collection of metaphor detection models, trained on limited labelled resources, which can be extended to other languages and similar tasks.
Neural embeddings for metaphor detection in a corpus of Greek texts
Feb 10, 2019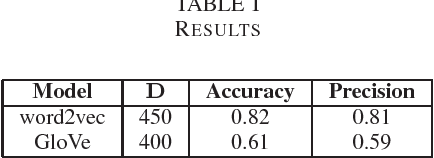
One of the major challenges that NLP faces is metaphor detection, especially by automatic means, a task that becomes even more difficult for languages lacking in linguistic resources and tools. Our purpose is the automatic differentiation between literal and metaphorical meaning in authentic non-annotated phrases from the Corpus of Greek Texts by means of computational methods of machine learning. For this purpose the theoretical background of distributional semantics is discussed and employed. Distributional Semantics Theory develops concepts and methods for the quantification and classification of semantic similarities displayed by linguistic elements in large amounts of linguistic data according to their distributional properties. In accordance with this model, the approach followed in the thesis takes into account the linguistic context for the computation of the distributional representation of phrases in geometrical space, as well as for their comparison with the distributional representations of other phrases, whose function in speech is already "known" with the objective to reach conclusions about their literal or metaphorical function in the specific linguistic context. This procedure aims at dealing with the lack of linguistic resources for the Greek language, as the almost impossible up to now semantic comparison between "phrases", takes the form of an arithmetical comparison of their distributional representations in geometrical space.
Word embeddings for idiolect identification
Feb 10, 2019The term idiolect refers to the unique and distinctive use of language of an individual and it is the theoretical foundation of Authorship Attribution. In this paper we are focusing on learning distributed representations (embeddings) of social media users that reflect their writing style. These representations can be considered as stylistic fingerprints of the authors. We are exploring the performance of the two main flavours of distributed representations, namely embeddings produced by Neural Probabilistic Language models (such as word2vec) and matrix factorization (such as GloVe).