 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Place-Related Questions to GeoSPARQL Queries
May 06, 2022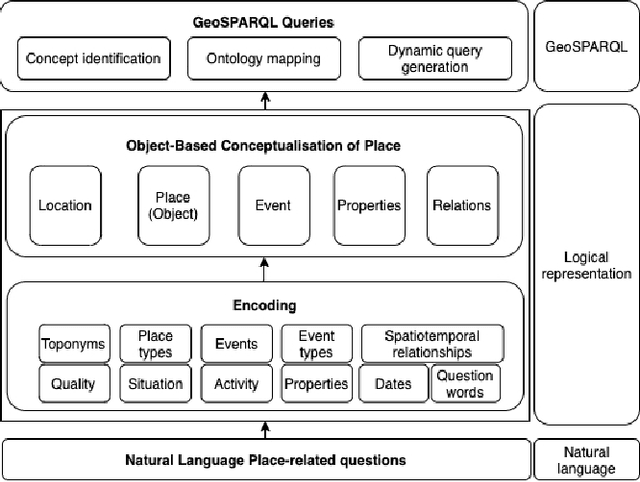
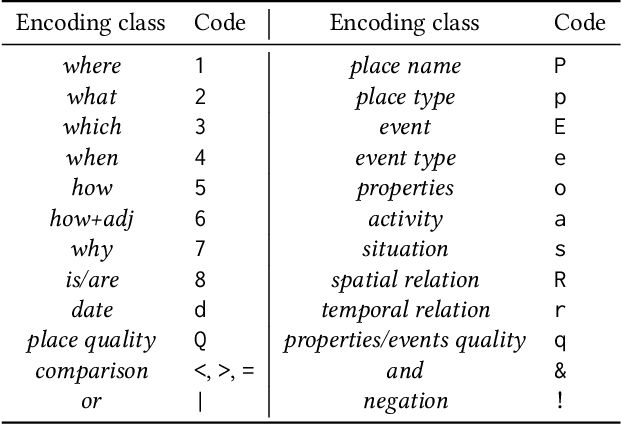
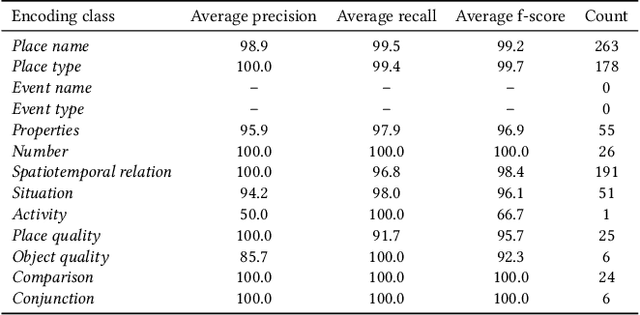
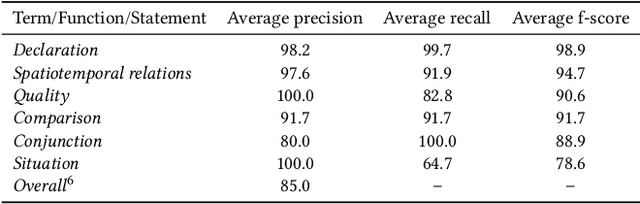
Many place-related questions can only be answered by complex spatial reasoning, a task poorly supported by factoid question retrieval. Such reasoning using combinations of spatial and non-spatial criteria pertinent to place-related questions is increasingly possible on linked data knowledge bases. Yet, to enable question answering based on linked knowledge bases, natural language questions must first be re-formulated as formal queries. Here, we first present an enhanced version of YAGO2geo, the geospatially-enabled variant of the YAGO2 knowledge base, by linking and adding more than one million places from OpenStreetMap data to YAGO2. We then propose a novel approach to translate the place-related questions into logical representations, theoretically grounded in the core concepts of spatial information. Next, we use a dynamic template-based approach to generate fully executable GeoSPARQL queries from the logical representations. We test our approach using the Geospatial Gold Standard dataset and report substantial improvements over existing methods.
Templates of generic geographic information for answering where-questions
Jan 21, 2021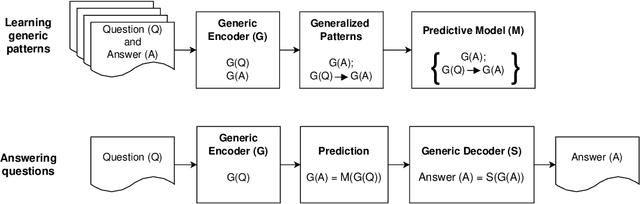

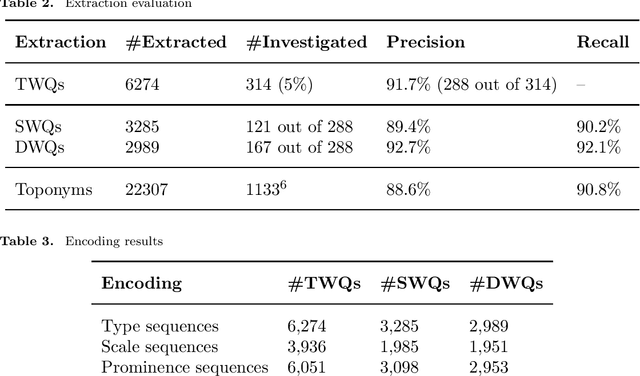
In everyday communication, where-questions are answered by place descriptions. To answer where-questions automatically, computers should be able to generate relevant place descriptions that satisfy inquirers' information needs. Human-generated answers to where-questions constructed based on a few anchor places that characterize the location of inquired places. The challenge for automatically generating such relevant responses stems from selecting relevant anchor places. In this paper, we present templates that allow to characterize the human-generated answers and to imitate their structure. These templates are patterns of generic geographic information derived and encoded from the largest available machine comprehension dataset, MS MARCO v2.1. In our approach, the toponyms in the questions and answers of the dataset are encoded into sequences of generic information. Next, sequence prediction methods are used to model the relation between the generic information in the questions and their answers. Finally, we evaluate the performance of predicting templates for answers to where-questions.