 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Decoding via Test-Time Policy Learning for Self-Improving Generation
Mar 19, 2026Decoding strategies largely determine the quality of Large Language Model (LLM) outputs, yet widely used heuristics such as greedy or fixed temperature/top-p decoding are static and often task-agnostic, leading to suboptimal or inconsistent generation quality across domains that demand stylistic or structural flexibility. We introduce a reinforcement learning-based decoder sampler that treats decoding as sequential decision-making and learns a lightweight policy to adjust sampling parameters at test-time while keeping LLM weights frozen. We evaluated summarization datasets including BookSum, arXiv, and WikiHow using Granite-3.3-2B and Qwen-2.5-0.5B. Our policy sampler consistently outperforms greedy and static baselines, achieving relative gains of up to +88% (BookSum, Granite) and +79% (WikiHow, Qwen). Reward ablations show that overlap-only objectives underperform compared to composite rewards, while structured shaping terms (length, coverage, repetition, completeness) enable stable and sustained improvements. These findings highlight reinforcement learning as a practical mechanism for test-time adaptation in decoding, enabling domain-aware and user-controllable generation without retraining large models.
Predicting Loss Risks for B2B Tendering Processes
Sep 14, 2021
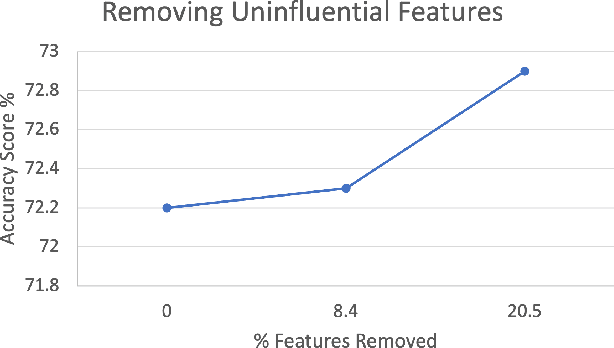
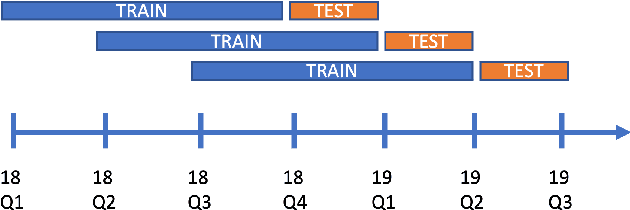
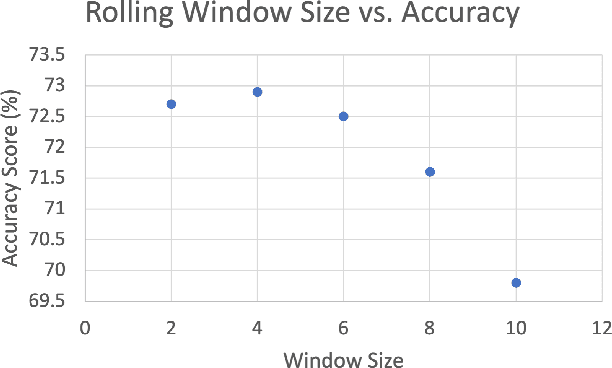
Sellers and executives who maintain a bidding pipeline of sales engagements with multiple clients for many opportunities significantly benefit from data-driven insight into the health of each of their bids. There are many predictive models that offer likelihood insights and win prediction modeling for these opportunities. Currently, these win prediction models are in the form of binary classification and only make a prediction for the likelihood of a win or loss. The binary formulation is unable to offer any insight as to why a particular deal might be predicted as a loss. This paper offers a multi-class classification model to predict win probability, with the three loss classes offering specific reasons as to why a loss is predicted, including no bid, customer did not pursue, and lost to competition. These classes offer an indicator of how that opportunity might be handled given the nature of the prediction. Besides offering baseline results on the multi-class classification, this paper also offers results on the model after class imbalance handling, with the results achieving a high accuracy of 85% and an average AUC score of 0.94.