 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare Event Analysis of Large Language Models
Feb 06, 2026Being probabilistic models, during inference large language models (LLMs) display rare events: behaviour that is far from typical but highly significant. By definition all rare events are hard to see, but the enormous scale of LLM usage means that events completely unobserved during development are likely to become prominent in deployment. Here we present an end-to-end framework for the systematic analysis of rare events in LLMs. We provide a practical implementation spanning theory, efficient generation strategies, probability estimation and error analysis, which we illustrate with concrete examples. We outline extensions and applications to other models and contexts, highlighting the generality of the concepts and techniques presented here.
Reinforcement Learning with Tensor Networks: Application to Dynamical Large Deviations
Sep 28, 2022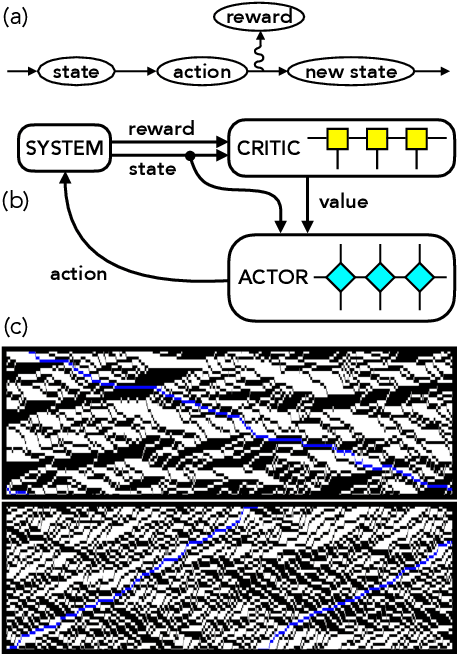
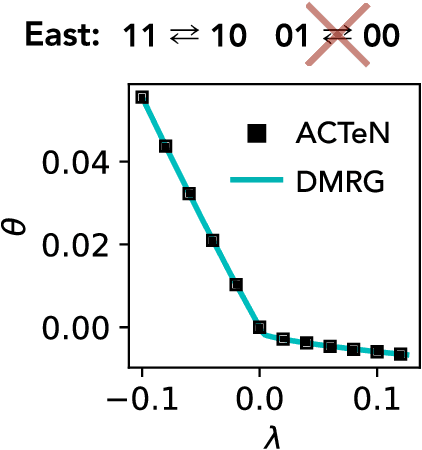
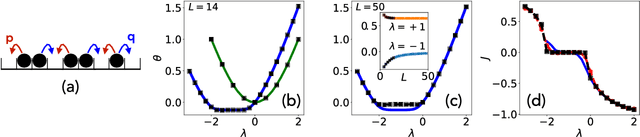
We present a framework to integrate tensor network (TN) methods with reinforcement learning (RL) for solving dynamical optimisation tasks. We consider the RL actor-critic method, a model-free approach for solving RL problems, and introduce TNs as the approximators for its policy and value functions. Our "actor-critic with tensor networks" (ACTeN) method is especially well suited to problems with large and factorisable state and action spaces. As an illustration of the applicability of ACTeN we solve the exponentially hard task of sampling rare trajectories in two paradigmatic stochastic models, the East model of glasses and the asymmetric simple exclusion process (ASEP), the latter being particularly challenging to other methods due to the absence of detailed balance. With substantial potential for further integration with the vast array of existing RL methods, the approach introduced here is promising both for applications in physics and to multi-agent RL problems more generally.
A Tensor Network Approach to Finite Markov Decision Processes
Feb 12, 2020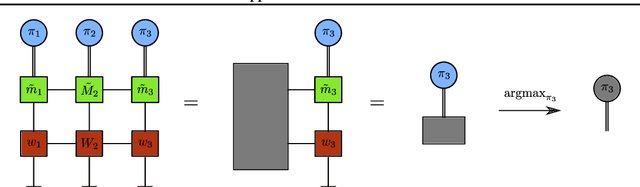
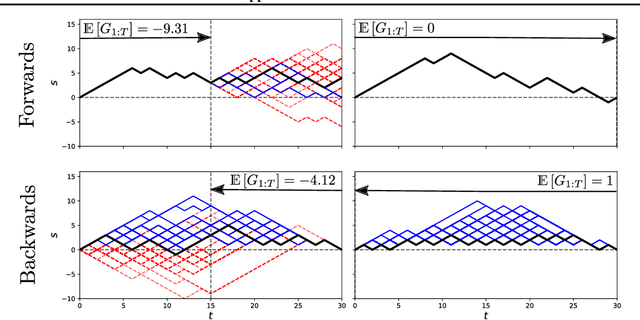
Tensor network (TN) techniques - often used in the context of quantum many-body physics - have shown promise as a tool for tackling machine learning (ML) problems. The application of TNs to ML, however, has mostly focused on supervised and unsupervised learning. Yet, with their direct connection to hidden Markov chains, TNs are also naturally suited to Markov decision processes (MDPs) which provide the foundation for reinforcement learning (RL). Here we introduce a general TN formulation of finite, episodic and discrete MDPs. We show how this formulation allows us to exploit algorithms developed for TNs for policy optimisation, the key aim of RL. As an application we consider the issue - formulated as an RL problem - of finding a stochastic evolution that satisfies specific dynamical conditions, using the simple example of random walk excursions as an illustration.